In diesem Leitfaden wird beschrieben, wie verschlüsselte Analyseberichte an Anbieter von Anzeigentechnologien gesendet werden. Chrome-Browser und ‑Clients senden diese Berichte an bestimmte Berichts-Endpunkte, an denen die AdTech-Plattform aggregierbare Berichte empfängt und speichert. Diese Endpunkte, die sich unter .well-known-URLs im Berichtsstamm des Anbieters befinden, werden von der Plattform gehostet. So können Anbieter von Anzeigentechnologien, die die Attribution Reporting API oder die Private Aggregation API verwenden, darauf zugreifen.
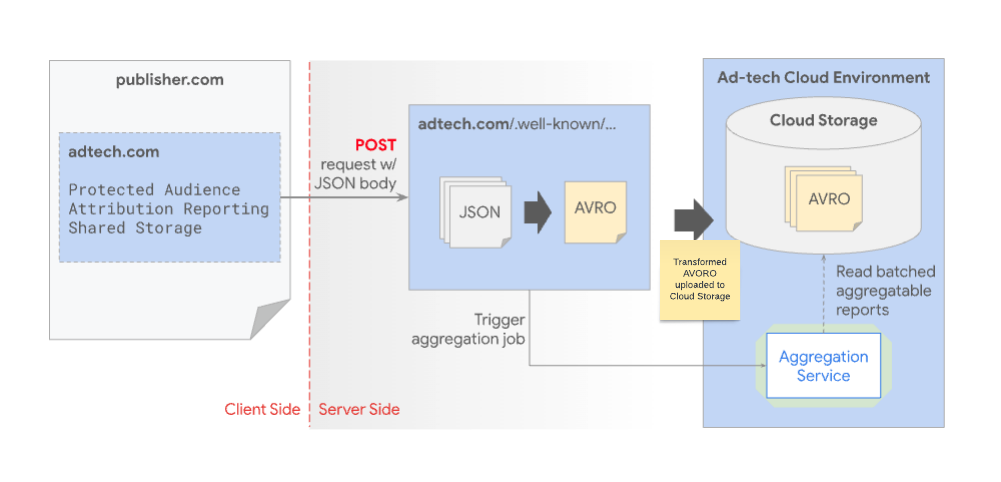
In den folgenden Schritten wird beschrieben, wie aggregierbare Berichte vom Aggregationsdienst empfangen und gespeichert werden:
- Wenn das Ereignis ausgelöst wird, sendet der Browser aggregierbare Berichte mit Details zu websiteübergreifenden und Conversion-Daten.
- Der Browser übergibt die verschlüsselten Berichte an eine
.well-known-URL innerhalb der Domain für AdTech-Berichte. - Das System leitet die Berichtsbatches zur Verarbeitung an den Aggregationsdienst weiter.
- Der Aggregationsdienst fasst die Berichte statistisch zusammen.
- Der Aggregationsdienst fügt den zusammengefassten Daten Rauschen hinzu, um den Datenschutz für Nutzer zu verbessern.
- Das System stellt die Berichte dem Anbieter von Anzeigentechnologien zu Analyse- und Analysezwecken zur Verfügung.
In der folgenden Tabelle werden die Debug- und Live-Endpunkte für die Private Aggregation API und die Attribution Reporting API beschrieben:
| API | Endpunkt | Beschreibung |
|---|---|---|
| Private Aggregation API |
|
|
| Attribution Reporting API |
|
|
JSON-Berichte werden über POST-Anfragen an die Berichtsquellen gesendet. Das System transformiert diese Berichte dann in das Avro-Format und speichert sie im Cloud-Speicher. Nach der Batchverarbeitung sendet das System die Avro-Berichte zur Zusammenfassung an den Aggregationsdienst.
Ad Tech-Plattformen lösen eine Aggregationsjobanfrage an den Aggregationsdienst aus, wenn ein Batch von Avro-Berichten zur Verarbeitung bereit ist. Dieser Dienst, der in der Cloud-Umgebung der AdTech-Plattform gehostet wird, ruft die erforderlichen Avro-Berichte vom selben Speicherort ab. Aus Sicherheitsgründen muss der Aggregationsdienst so konfiguriert sein, dass er ein genehmigtes Container-Image verwendet. Verfügbare Container-Images finden Sie im GitHub-Repository für die Privacy Sandbox/den Aggregationsdienst.
Im Folgenden finden Sie repräsentative Beispiele für die von den einzelnen APIs zurückgegebenen Berichte:
- Beispiel für einen Bericht der Private Aggregation API:
{
"aggregation_coordinator_origin": "https://publickeyservice.msmt.aws.privacysandboxservices.com",
"aggregation_service_payloads": [ {
"key_id": "1a2baa3f-5d48-46cf-91f0-772633c12640",
"payload": "8Cjr1s3FVkCYkjzBvyzJn14yardVjd5N4vLCA69LQAPbIkJ0B58hAqUGBCNXpvTjW9ZpIoZbCSiUOsUDuoA/S+tqVolLMkame6sWC07cfUmZcVsbU+La3pzTMtCgdtNc8MIWgD3C63CMw7rWroRlechewVUajvAYVK/0HJq0YyGrTiFZZm36zi0jjyHLAXKV8p1Lvy1d0o/wnBxC5oVo5BV6LPkxqQEcoYS2GyixUuht6wD0RzuH+BxxuH6vY/ynp2xDrnwftjvqwDUAxUWLFTunthM6BXZVxlrvOBim1h2dvPqWSyKZ5gafo+MgW9EM4SraavNM3XzZSCjdtAfSMJMrynSu2j0opyAq+9e1jq1xeYN00yZrJ0Y/GTI45IGjgCnVmvmuoI9ucW2SnXP31CQBwHqk4gtUgMsYGFSUYfhtnAQ/8TSbaXyS2LX+cQW87LqkvIraWw6o37O24VFBreFoFFXpu3IUeCZfji+Sr4/ykfZuHeMzQbBavyNnHKzPZlbLSXMiucx4/vWzYyOzHeIlbtupXVvbi40V2PieDShaSbjI266kGgFkeCk6z51AaAGebDPtRT1lhBpcoQ6JdF0Yp5VWSnyFARKFtCZ1aEBrlUlrEHLUQY/pFtmDxJQiicRz1YPjR8jRr3C7hlRhWwov0dMocqnMz5209hHGVZWSsaGc9kWjtxREW2ULXfoIwOGbX+WZsyFW2RhXksQPJ5fhyNc4ROkAzUthLb68gC5e0yZHvmLIAU4hcWe0UanJv+jRljn8PAPaJHKFUxQNJyBA7mTbn5mkpycxGrX6T3ZYdPHqvckqt9llJZWjr8NneizzZFRuJk423BDs38fXkvcTAsAckd2Zu0u2KC45WR93sN2/CWrqB7/QU9BsgNdonl/ehAWhU1LbcRRvBTcR9+0wL7vRL7cv5LG3+gRYRKsWI6U2nDSWp0cNpo9+HU0JNiifa5X0cguihqU2bSk6ABozgRtCZ7m+7eqWXMLSzBdmc1CPUoQppo6Wmf6ujdNqI6v2S6pDH781lph8Z2v7ZpxGdhVVPEL51cVn"
} ],
"debug_key": "1234",
"shared_info": "{\"api\":\"shared-storage\",\"report_id\":\"05e3b948-cb8d-4404-be29-bfeac7ad9710\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1707784729\",\"version\":\"0.1\"}"
}
- Beispiel für einen Attribution Reporting API-Bericht
{
"aggregation_coordinator_origin": "https://publickeyservice.msmt.aws.privacysandboxservices.com",
"aggregation_service_payloads": [ {
"key_id": "2dee0f3f-2aee-4a4a-8238-9154ed3d6f72",
"payload": "pHvTHhcxvNKaCmnLpvYQsXlJpiNRuFO5Zj1QqUlqgWPOfuoHLfiXiFjmpvY8a53/OYnS4bKwHwJReFcofldsu8E9BzTTJ3CEk+B7vbEjnDPaljhpIBMTuQXy3QHGK4slWR/yNZVm2uXRWR/DVVzXziBoTDjN7qaPstRoLKUUMdfY2u8oq4tnLY00Y+NDZttZ4wJvC7hPmvY3lqHjdl14JPD2ytZZ4NViYzno3WKdH/oZc0jhGK4zI38lAM0qpahF/B9yb4zOu7IRIjQpNx73P8naDyddxLldoVlW/qHpO04FguWymscvI/8i6NwUR6Kj8seRlWS0iIUhETt/ai3lilKUHUb+uz0YG2kxjoXq7Ldk+MP56nNl67ZRNi2YZ7bOGI/okYWoT/wt2uWPe/5xAEMmadxl0hQQrG7YXHRSD8rDnaVPXo+AKIxdg727yJeB1ZENZvovl/kIevdRAmdBe2h1U3J6Uz6psly/46fvjgkj5QD+kO2uaYirzvmwS19luJsN/Qvh/R3ZO4qlJIQI0nDJPWwUJ4ODpyVmj4a0xQp3t2ESEnf4EmY7+khn3xpF5+MwEWKES2ZeDf7SHalR99pvZA8G3Fr8M0PWFmT00cmKCBwpQgZyd3Eay70UlqdkbFEedxiCVWKNNOUz41m5KG/7K3aR+dYx57l57Wct4gOFQg3jiUEBJWrFIVCXf12BT5iz5rBQh1N1CUt2oCOhYL/sPuBl6OV5GWHSIj8FUdpoDolqKXWINXfE88MUijE2ghNRpJN25BXIErUQtO9wFQv7zotC6d2BIaF0x8AkKg/7yzBQRySX/FZP3H3lMkpOz9rQMV8DjZ2lz7nV4k6CFo8qhT6cpYJD7GpYl81xJbglNqcJt5Pe5YUHrdBMyAFsTh3yoJvYnhQib/0xVN/a93lbYccxsd0yi375n4Xz0i1HUoe2ps+WlU8XysAUA1agG936eshaY1anTtbJbrcoaH+BNSacKiq4saprgUGl4eDjaR/uBhvUnO52WkmAGon8De3EFMZ/kwpPBNSXi7/MIAMjotsSKBc19bfg"
} ],
"shared_info": "{\"api\":\"attribution-reporting\",\"attribution_destination\":\"https://privacy-sandbox-demos-shop.dev\",\"report_id\":\"5b052748-f5fb-4f14-b291-de03484ed59e\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1707786751\",\"source_registration_time\":\"0\",\"version\":\"0.1\"}",
"source_debug_key": "123456789",
"trigger_debug_key": "123456789"
}
JSON-Berichte in Avro-Berichte konvertieren
Aggregierbare Berichte müssen für Batchzwecke im Apache Avro-Datenserialisierungsformat vorliegen. Um einen Avro-Bericht zu erstellen, müssen Sie ein AVSC-Schema verwenden. Die AVSC-Schemadatei definiert die Avro-Eintragsstruktur und den Datentyp. Ein Beispiel für ein AVSC-Schema finden Sie in der Datei example.avsc in diesem GitHub-Repository von avrodoc/schemata.
Beispiel-JavaScript-Code finden Sie im Abschnitt Berichte erfassen, transformieren und in Batches verarbeiten auf der Seite Aggregierbare Berichte erfassen und in Batches verarbeiten im GitHub-Repository privacysandbox/aggregation-service.
Sie können alle Berichte in einer einzigen AVRO-Datei speichern oder auf mehrere Dateien verteilen. Für AVRO-Dateien gibt es keine Größenbeschränkung. Die optimale Leistung wird in der Regel erreicht, wenn die Anzahl der Dateien der Anzahl der CPUs in Ihrer Cloud-Instanz entspricht oder diese übersteigt.
Das folgende Codebeispiel zeigt ein Avro-Schema für aggregierbare Berichte. Zu den Berichtsfeldern gehören payload, key_id und shared_info.
{
"type": "record",
"name": "AggregatableReport",
"fields": [
{
"name": "payload",
"type": "bytes"
},
{
"name": "key_id",
"type": "string"
},
{
"name": "shared_info",
"type": "string"
}
]
}
| Parameter | Typ | Beschreibung |
|---|---|---|
payload |
Byte |
Die payload muss für Live- oder Produktionsberichte base64-decodiert und in ein Byte-Array umgewandelt werden.
|
debug_cleartext_payload |
Byte |
Die Nutzlast muss aus der debug_cleartext_payload base64-decodiert und in ein Byte-Array umgewandelt werden, um Debug-Berichte zu erstellen.
|
key_id |
String | Das ist der String key_id, der im Bericht gefunden wurde. Die key_id ist eine 128-Bit-Universally Unique Identifier (UUID). |
shared_info |
String | Das ist der unveränderte, nicht manipulierte String, der im Berichts-shared_info-Feld gefunden wurde. |
Im Folgenden finden Sie ein Beispiel für einen JSON-Bericht:
{
"aggregation_coordinator_identifier": "aws-cloud",
"aggregation_service_payloads": [{
"debug_cleartext_payload": "omRkYXhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAFWW1vcGVyYX",
"key_id": "3c6e2850-edf6-4886-eb70-eb3f2a7a7596",
"payload": "oapYz92Mb1yam9YQ2AnK8dduTt2RwFUSApGcKqXnG1q+aGXfJ5DGpSxMj0NxdZgp7Cq"
}],
"debug_key": "1234",
"shared_info":
"{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"b029b922-93e9-4d66-a8c6-8cdeec762aed\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1719251997\",\"version\":\"0.1\"}"
}
Spezifikation der Domaindatei
Zum Generieren von Zusammenfassungsberichten mit dem Aggregationsdienst benötigen Sie Ihre aggregierbaren Berichte (JSON-Berichte, die in Avro konvertiert wurden) und die zugehörige Domaindatei. Das System liest vordefinierte Schlüssel aus Ihren aggregierbaren Berichten aus und nimmt sie in die Zusammenfassungsberichte in Ausgabedomains auf. Weitere Informationen zu diesen wichtigen Aggregationsschlüsseln finden Sie unter Aggregationsschlüssel für Attributionsberichte und im Abschnitt Aggregationsschlüssel des Artikels Grundlagen der Private Aggregation API. Die Ausgabedomain enthält auch das Feld bucket, das den Bucket-Schlüsselwert darstellt.
Die Domaindatei muss im Avro-Format mit dem folgenden Schema vorliegen:
{
"type": "record",
"name": "AggregationBucket",
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "A single bucket that appears in the aggregation service output. It is an 128-bit integer value encoded as a 16-byte big-endian bytestring."
}
]
}
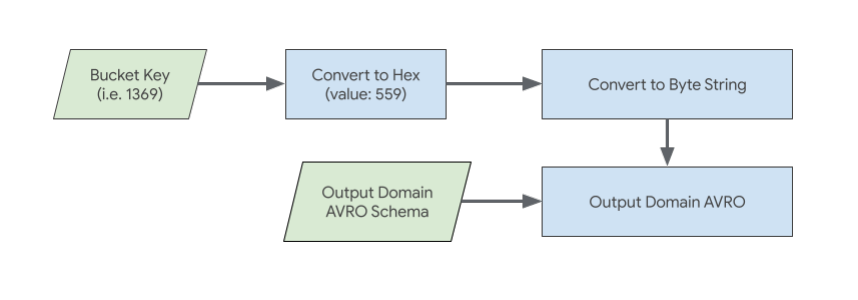
Bucket-Schlüssel
Der Bucket-Schlüssel in der Ausgabedomain muss als Hexadezimal-Byte-String dargestellt werden.
Beispiel:
Wenn der Bucket-Schlüssel der Dezimalwert 1369 ist:
1369 in das Hexadezimaläquivalent umwandeln: 559
Wandeln Sie den Hexadezimalstring „559“ in einen Bytestring um.
Diese Bytestring-Darstellung des Bucket-Schlüssels sollte dann in das Avro-Schema der Ausgabedomain aufgenommen werden.
Wichtige Aspekte:
Datentyp: Der Bucket-Schlüssel im Avro-Schema sollte als Bytetyp definiert werden, um die Hexadezimaldarstellung von Bytestrings zu ermöglichen.
Konvertierung: Die Konvertierung von Dezimal in Hexadezimal und dann in einen Byte-String kann mit Python oder Java implementiert werden.
So wird sichergestellt, dass der Bucket-Schlüssel richtig formatiert und mit dem erwarteten Datentyp im Avro-Schema für die Ausgabedomain kompatibel ist.
Batchberichte
Weitere Informationen zu Datenschutzbudgets und Batching-Strategien finden Sie in der Dokumentation zu Batching-Strategien. Für aggregierbare Berichte gilt das Limit MAX_REPORT_AGE (aktuell 90 Tage) zwischen dem scheduled_report_time und dem Datum der Batchausführung.
Zusammenfassende Berichte
Nach dem Batching erstellt der Aggregations-Dienst den Zusammenfassungsbericht im Avro-Format mit dem results.avsc-Schema.
Nach Abschluss des Jobs wird der Zusammenfassungsbericht im output_data_blob_prefix im output_data_bucket_name-Bucket gespeichert, wie in der createJob-Anfrage angegeben.
Für Aggregationsdienst-Batches, bei denen debug_run aktiviert ist, werden zwei Berichte erstellt: der Zusammenfassungsbericht und der Bericht zur Fehlerbehebung. Der Bericht zur Fehlerbehebung befindet sich im Ordner output_data_blob_prefix/debug. Für den Bericht zur Fehlerbehebung wird das debug_results.avsc-Schema verwendet.
Sowohl der Zusammenfassungs- als auch der Debug-Bericht haben den Namen [output_data_blob_prefix]-1-of-1.avro. Wenn Ihre output_data_blob_prefix summary/summary.avro ist, befindet sich der Bericht im Ordner „Zusammenfassung“ mit dem Namen summary-1-of-1.avro.
results.avsc-Beispiel
Im Folgenden finden Sie ein Beispiel für ein Avro-Schema für results.avsc:
{
"type": "record",
"name": "AggregatedFact",
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "Histogram bucket used in aggregation. It is an 128-bit integer value encoded as a 16-byte big-endian bytestring. Leading 0-bits are left out."
},
{
"name": "metric",
"type": "long",
"doc": "The metric associated with the bucket"
}
]
}
Im Beispiel-Avro-Schema wird ein Datensatz mit dem Namen AggregatedFact definiert.
debug_results.avsc-Beispiel
Das folgende Beispiel ist ein Avro-Schema für debug_results.avsc:
{
"type": "record",
"name": "DebugAggregatedFact", Output domains include summary reports that contain pre-declared keys extracted from your aggregatable reports.
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "This represents the histogram bucket used in aggregation. It's a 128-bit integer, encoded as a 16-byte big-endian bytestring, with leading zero bytes omitted.."
},
{
"name": "unnoised_metric",
"type": "long",
"doc": "The raw metric for the bucket."
},
{
"name": "noise",
"type": "long",
"doc": "The noise applied to the metric in the regular result."
}
{
"name":"annotations",
"type": {
"type": "array",
"items": {
"type":"enum",
"name":"bucket_tags",
"symbols":["in_domain","in_reports"]
}
}
]
}
Nach der Umwandlung sieht Ihr Zusammenfassungsbericht in etwa so aus wie in results.json. Wenn debug_run aktiviert ist, ähnelt der zurückgegebene Bericht zur Fehlerbehebung der Zusammenfassung in debug_results.json.
Avro-Berichtsformat
Avro-Berichte, die vom Aggregationsdienst empfangen werden, folgen in der Regel einem einheitlichen Format. Das Avro-Berichtsformat enthält die folgenden Felder:
bucket: Eine eindeutige Kennung für die Datenaggregation (z. B. „\u0005Y“).
Messwert: Der aggregierte Wert für den entsprechenden Bucket. Dieser Wert enthält oft zusätzliches Rauschen, um den Datenschutz zu verbessern.
Beispiel:
{
"bucket": "\u0005Y",
"metric": 26308
}
debug_results.json-Beispiel
Avro-Debugberichte vom Aggregationsdienst ähneln dem folgenden debug_results.json-Beispiel. Diese Berichte enthalten Bucket-Schlüssel, die unnoised_metric (die Zusammenfassung der Bucket-Schlüssel vor der Anwendung von Rauschen) und das Rauschen, das diesem Messwert hinzugefügt wurde.
{
"bucket": "\u0005Y",
"unnoised_metric": 128,
"noise": -17948,
"annotations": [
"in_reports",
"in_domain"
]
}
Die Anmerkungen enthalten außerdem die folgenden Werte:
in_reports: der Bucket-Schlüssel in den aggregierten Berichtenin_domain: Der Bucket-Schlüssel in der Avro-Dateioutput_domain