En esta guía, se describe cómo se entregan los informes de medición encriptados a los proveedores de tecnología publicitaria. Los navegadores y clientes de Chrome envían estos informes a extremos de informes designados, donde la plataforma de tecnología publicitaria recibe y almacena informes agregables. La plataforma aloja estos extremos, que se encuentran en URLs de .well-known dentro del origen de informes del proveedor, lo que permite que los proveedores de tecnología publicitaria que usan la API de Attribution Reporting o la API de Private Aggregation accedan a ellos.
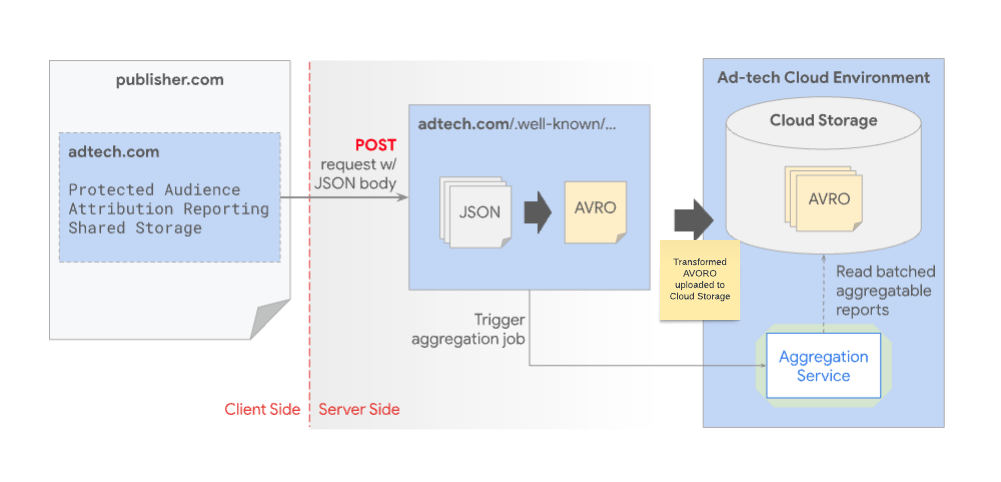
En los siguientes pasos, se detalla el proceso del servicio de agregación para recibir y almacenar informes agregables:
- Cuando se activa, el navegador envía informes agregables que contienen detalles sobre los datos de conversiones y de varios sitios.
- El navegador envía los informes encriptados a una URL de
.well-knowndentro del dominio de informes de la tecnología publicitaria. - El sistema reenvía los lotes de informes al servicio de agregación para su procesamiento.
- El servicio de agregación resume los informes de forma estadística.
- El servicio de agregación agrega ruido a los datos resumidos para mejorar la privacidad del usuario.
- El sistema pone los informes a disposición de la empresa de tecnología publicitaria para fines de análisis y medición.
En la siguiente tabla, se describen los extremos de depuración y en vivo de la API de Private Aggregation y la API de Attribution Reporting:
| API | Extremo | Descripción |
|---|---|---|
| API de Private Aggregation |
|
|
| API de Attribution Reporting |
|
|
Los orígenes de informes reciben informes JSON a través de llamadas POST. Luego, el sistema transforma estos informes en formato Avro y los coloca en el almacenamiento en la nube. Después del procesamiento por lotes, el sistema envía los informes Avro al servicio de agregación para su resumen.
Las plataformas de tecnología publicitaria activan una solicitud de trabajo de agregación al servicio de agregación cuando se considera que un lote de informes Avro está listo para procesarse. Este servicio, alojado en el entorno de nube de la plataforma de tecnología publicitaria, recupera los informes Avro necesarios desde la misma ubicación de almacenamiento. Por motivos de seguridad, el servicio de agregación debe configurarse para usar una imagen de contenedor aprobada. Consulta el repositorio de GitHub de la zona de pruebas de privacidad o del servicio de agregación para ver las imágenes de contenedor disponibles.
A continuación, se muestran ejemplos representativos de los informes que muestra cada API:
- Ejemplo de informe de la API de Private Aggregation:
{
"aggregation_coordinator_origin": "https://publickeyservice.msmt.aws.privacysandboxservices.com",
"aggregation_service_payloads": [ {
"key_id": "1a2baa3f-5d48-46cf-91f0-772633c12640",
"payload": "8Cjr1s3FVkCYkjzBvyzJn14yardVjd5N4vLCA69LQAPbIkJ0B58hAqUGBCNXpvTjW9ZpIoZbCSiUOsUDuoA/S+tqVolLMkame6sWC07cfUmZcVsbU+La3pzTMtCgdtNc8MIWgD3C63CMw7rWroRlechewVUajvAYVK/0HJq0YyGrTiFZZm36zi0jjyHLAXKV8p1Lvy1d0o/wnBxC5oVo5BV6LPkxqQEcoYS2GyixUuht6wD0RzuH+BxxuH6vY/ynp2xDrnwftjvqwDUAxUWLFTunthM6BXZVxlrvOBim1h2dvPqWSyKZ5gafo+MgW9EM4SraavNM3XzZSCjdtAfSMJMrynSu2j0opyAq+9e1jq1xeYN00yZrJ0Y/GTI45IGjgCnVmvmuoI9ucW2SnXP31CQBwHqk4gtUgMsYGFSUYfhtnAQ/8TSbaXyS2LX+cQW87LqkvIraWw6o37O24VFBreFoFFXpu3IUeCZfji+Sr4/ykfZuHeMzQbBavyNnHKzPZlbLSXMiucx4/vWzYyOzHeIlbtupXVvbi40V2PieDShaSbjI266kGgFkeCk6z51AaAGebDPtRT1lhBpcoQ6JdF0Yp5VWSnyFARKFtCZ1aEBrlUlrEHLUQY/pFtmDxJQiicRz1YPjR8jRr3C7hlRhWwov0dMocqnMz5209hHGVZWSsaGc9kWjtxREW2ULXfoIwOGbX+WZsyFW2RhXksQPJ5fhyNc4ROkAzUthLb68gC5e0yZHvmLIAU4hcWe0UanJv+jRljn8PAPaJHKFUxQNJyBA7mTbn5mkpycxGrX6T3ZYdPHqvckqt9llJZWjr8NneizzZFRuJk423BDs38fXkvcTAsAckd2Zu0u2KC45WR93sN2/CWrqB7/QU9BsgNdonl/ehAWhU1LbcRRvBTcR9+0wL7vRL7cv5LG3+gRYRKsWI6U2nDSWp0cNpo9+HU0JNiifa5X0cguihqU2bSk6ABozgRtCZ7m+7eqWXMLSzBdmc1CPUoQppo6Wmf6ujdNqI6v2S6pDH781lph8Z2v7ZpxGdhVVPEL51cVn"
} ],
"debug_key": "1234",
"shared_info": "{\"api\":\"shared-storage\",\"report_id\":\"05e3b948-cb8d-4404-be29-bfeac7ad9710\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1707784729\",\"version\":\"0.1\"}"
}
- Ejemplo de informe de la API de Attribution Reporting
{
"aggregation_coordinator_origin": "https://publickeyservice.msmt.aws.privacysandboxservices.com",
"aggregation_service_payloads": [ {
"key_id": "2dee0f3f-2aee-4a4a-8238-9154ed3d6f72",
"payload": "pHvTHhcxvNKaCmnLpvYQsXlJpiNRuFO5Zj1QqUlqgWPOfuoHLfiXiFjmpvY8a53/OYnS4bKwHwJReFcofldsu8E9BzTTJ3CEk+B7vbEjnDPaljhpIBMTuQXy3QHGK4slWR/yNZVm2uXRWR/DVVzXziBoTDjN7qaPstRoLKUUMdfY2u8oq4tnLY00Y+NDZttZ4wJvC7hPmvY3lqHjdl14JPD2ytZZ4NViYzno3WKdH/oZc0jhGK4zI38lAM0qpahF/B9yb4zOu7IRIjQpNx73P8naDyddxLldoVlW/qHpO04FguWymscvI/8i6NwUR6Kj8seRlWS0iIUhETt/ai3lilKUHUb+uz0YG2kxjoXq7Ldk+MP56nNl67ZRNi2YZ7bOGI/okYWoT/wt2uWPe/5xAEMmadxl0hQQrG7YXHRSD8rDnaVPXo+AKIxdg727yJeB1ZENZvovl/kIevdRAmdBe2h1U3J6Uz6psly/46fvjgkj5QD+kO2uaYirzvmwS19luJsN/Qvh/R3ZO4qlJIQI0nDJPWwUJ4ODpyVmj4a0xQp3t2ESEnf4EmY7+khn3xpF5+MwEWKES2ZeDf7SHalR99pvZA8G3Fr8M0PWFmT00cmKCBwpQgZyd3Eay70UlqdkbFEedxiCVWKNNOUz41m5KG/7K3aR+dYx57l57Wct4gOFQg3jiUEBJWrFIVCXf12BT5iz5rBQh1N1CUt2oCOhYL/sPuBl6OV5GWHSIj8FUdpoDolqKXWINXfE88MUijE2ghNRpJN25BXIErUQtO9wFQv7zotC6d2BIaF0x8AkKg/7yzBQRySX/FZP3H3lMkpOz9rQMV8DjZ2lz7nV4k6CFo8qhT6cpYJD7GpYl81xJbglNqcJt5Pe5YUHrdBMyAFsTh3yoJvYnhQib/0xVN/a93lbYccxsd0yi375n4Xz0i1HUoe2ps+WlU8XysAUA1agG936eshaY1anTtbJbrcoaH+BNSacKiq4saprgUGl4eDjaR/uBhvUnO52WkmAGon8De3EFMZ/kwpPBNSXi7/MIAMjotsSKBc19bfg"
} ],
"shared_info": "{\"api\":\"attribution-reporting\",\"attribution_destination\":\"https://privacy-sandbox-demos-shop.dev\",\"report_id\":\"5b052748-f5fb-4f14-b291-de03484ed59e\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1707786751\",\"source_registration_time\":\"0\",\"version\":\"0.1\"}",
"source_debug_key": "123456789",
"trigger_debug_key": "123456789"
}
Convierte informes de JSON a Avro
Los informes agregables deben estar en el formato de serialización de datos de Apache Avro para realizar tareas por lotes. Para crear un informe de Avro, debes usar un esquema AVSC. El archivo de esquema AVSC define la estructura del registro y el tipo de datos de Avro. Para ver un ejemplo de esquema AVSC, consulta el archivo example.avsc en este repositorio de GitHub de avrodoc/schemata.
Puedes encontrar un ejemplo de código JavaScript en la sección Collect, transform and batch reports de la página Collecting and Batching Aggregatable Reports, ubicada en el repositorio de GitHub privacysandbox/aggregation-service.
Tienes la flexibilidad de almacenar todos los informes en un solo archivo AVRO o distribuirlos en varios archivos. Si bien los archivos AVRO no tienen límite de tamaño, el rendimiento óptimo suele alcanzarse cuando la cantidad de archivos varía entre la cantidad de CPUs de tu instancia en la nube y 1,000.
En el siguiente ejemplo de código, se muestra un esquema Avro para informes agregables. Los campos de informes incluyen payload, key_id y shared_info.
{
"type": "record",
"name": "AggregatableReport",
"fields": [
{
"name": "payload",
"type": "bytes"
},
{
"name": "key_id",
"type": "string"
},
{
"name": "shared_info",
"type": "string"
}
]
}
| Parámetro | Tipo | Descripción |
|---|---|---|
payload |
Bytes |
El payload debe decodificarse en base64 y convertirse en un array de bytes para los informes en vivo o de producción.
|
debug_cleartext_payload |
Bytes |
La carga útil debe decodificarse en base64 y convertirse en un array de bytes de debug_cleartext_payload para los informes de depuración.
|
key_id |
String | Esta es la cadena key_id que se encuentra en el informe. key_id es un identificador único universal de 128 bits. |
shared_info |
String | Esta es la cadena sin alteraciones que se encuentra en el campo shared_info del informe. |
El siguiente es un ejemplo de informe JSON:
{
"aggregation_coordinator_identifier": "aws-cloud",
"aggregation_service_payloads": [{
"debug_cleartext_payload": "omRkYXhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAFWW1vcGVyYX",
"key_id": "3c6e2850-edf6-4886-eb70-eb3f2a7a7596",
"payload": "oapYz92Mb1yam9YQ2AnK8dduTt2RwFUSApGcKqXnG1q+aGXfJ5DGpSxMj0NxdZgp7Cq"
}],
"debug_key": "1234",
"shared_info":
"{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"b029b922-93e9-4d66-a8c6-8cdeec762aed\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1719251997\",\"version\":\"0.1\"}"
}
Especificación del archivo de dominio
Para generar informes de resumen con el servicio de agregación, necesitas tus informes agregables (informes JSON convertidos a Avro) y el archivo de dominio asociado. El sistema extrae claves declaradas previamente de tus informes agregables y las incluye en los informes de resumen dentro de los dominios de salida. Encontrarás detalles sobre estas claves de agregación fundamentales en Información sobre las claves de agregación para los informes de atribución y en la sección Clave de agregación de Conceptos básicos de la API de agregación privada. El dominio de salida también incluye el campo bucket, que representa el valor de la clave del bucket.
El archivo de dominio debe estar en formato Avro con el siguiente esquema:
{
"type": "record",
"name": "AggregationBucket",
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "A single bucket that appears in the aggregation service output. It is an 128-bit integer value encoded as a 16-byte big-endian bytestring."
}
]
}
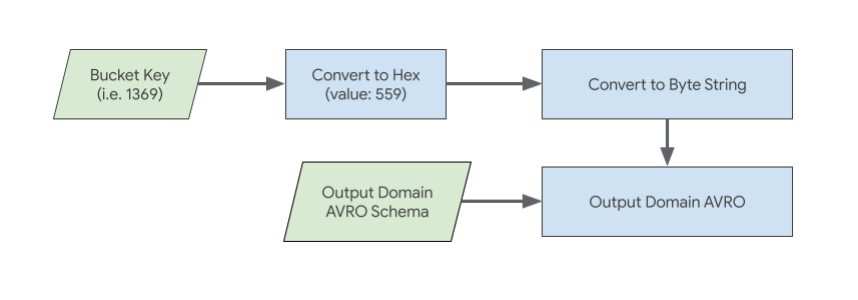
Clave del bucket
La clave del bucket dentro del dominio de salida debe representarse como una cadena de bytes hexadecimal.
Por ejemplo:
Si la clave del bucket es el valor decimal 1369, haz lo siguiente:
Convierte 1369 a su equivalente hexadecimal: 559
Convierte la cadena hexadecimal "559" en una cadena de bytes.
Esta representación de cadena de bytes de la clave del bucket se debe incluir en el esquema Avro del dominio de salida.
Consideraciones importantes:
Tipo de datos: La clave de bucket dentro del esquema de Avro se debe definir como un tipo de byte para admitir la representación de cadena de bytes hexadecimal.
Conversión: La conversión de decimal a hexadecimal y, luego, a una cadena de bytes se puede implementar con Python o Java.
Este enfoque garantiza que la clave del bucket tenga el formato correcto y sea compatible con el tipo de datos esperado dentro del esquema Avro para el dominio de salida.
Informes por lotes
Para obtener más información sobre los presupuestos de privacidad y las estrategias de procesamiento por lotes, consulta la documentación sobre estrategias de procesamiento por lotes. Ten en cuenta que los informes agregables tienen un límite de MAX_REPORT_AGE (actualmente, 90 días) entre su scheduled_report_time y la fecha de ejecución por lotes.
Informes de resumen
Después de la agrupación por lotes, el servicio de agregación crea el informe de resumen en formato Avro con el esquema results.avsc.
Cuando se completa el trabajo, el informe de resumen se almacena en output_data_blob_prefix dentro del bucket output_data_bucket_name, como se indica en la solicitud createJob.
En el caso de los lotes del servicio de agregación en los que debug_run está habilitado, se crean dos informes: el informe de resumen y el informe de resumen de depuración. El informe de resumen de depuración se encuentra en la carpeta output_data_blob_prefix/debug. El informe de resumen de depuración usa el esquema debug_results.avsc.
Tanto el informe de resumen como el de depuración se denominan [output_data_blob_prefix]-1-of-1.avro. Si tu output_data_blob_prefix es summary/summary.avro, el informe se encuentra en la carpeta de resumen con el nombre summary-1-of-1.avro.
Ejemplo results.avsc
El siguiente es un ejemplo de esquema de Avro para results.avsc:
{
"type": "record",
"name": "AggregatedFact",
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "Histogram bucket used in aggregation. It is an 128-bit integer value encoded as a 16-byte big-endian bytestring. Leading 0-bits are left out."
},
{
"name": "metric",
"type": "long",
"doc": "The metric associated with the bucket"
}
]
}
El ejemplo de esquema de Avro define un registro llamado AggregatedFact.
Ejemplo debug_results.avsc
El siguiente es un ejemplo de esquema Avro para debug_results.avsc:
{
"type": "record",
"name": "DebugAggregatedFact", Output domains include summary reports that contain pre-declared keys extracted from your aggregatable reports.
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "This represents the histogram bucket used in aggregation. It's a 128-bit integer, encoded as a 16-byte big-endian bytestring, with leading zero bytes omitted.."
},
{
"name": "unnoised_metric",
"type": "long",
"doc": "The raw metric for the bucket."
},
{
"name": "noise",
"type": "long",
"doc": "The noise applied to the metric in the regular result."
}
{
"name":"annotations",
"type": {
"type": "array",
"items": {
"type":"enum",
"name":"bucket_tags",
"symbols":["in_domain","in_reports"]
}
}
]
}
Una vez convertido, tu informe de resumen se parecerá al ejemplo de results.json. Cuando debug_run está habilitado, el informe de resumen de depuración que se muestra es similar al ejemplo de debug_results.json.
Formato de informes de Avro
Los informes de Avro que se reciben del servicio de agregación suelen seguir un formato coherente. El formato de informe de Avro incluye los siguientes campos:
bucket: Es un identificador único para la agregación de datos (por ejemplo, "\u0005Y").
metric: Es el valor agregado del bucket correspondiente. A menudo, este valor incluye ruido agregado para mejorar la privacidad.
Por ejemplo:
{
"bucket": "\u0005Y",
"metric": 26308
}
Ejemplo debug_results.json
Los informes de Avro de depuración del servicio de agregación se parecerán al siguiente ejemplo de debug_results.json. Estos informes incluyen las claves de bucket, el unnoised_metric (el resumen de las claves de bucket antes de la aplicación del ruido) y el ruido agregado a esa métrica.
{
"bucket": "\u0005Y",
"unnoised_metric": 128,
"noise": -17948,
"annotations": [
"in_reports",
"in_domain"
]
}
Las anotaciones también contienen los siguientes valores:
in_reports: Es la clave de bucket disponible en los informes agregables.in_domain: Es la clave del bucket disponible dentro del archivo Avrooutput_domain.