במדריך הזה מוסבר איך דוחות מדידה מוצפנים מועברים לספקי טכנולוגיות הפרסום. דפדפנים ולקוחות של Chrome שולחים את הדוחות האלה לנקודות קצה ייעודיות לדיווח, שבהן פלטפורמת טכנולוגיית הפרסום מקבלת ומאחסנת דוחות שניתן לצבור. נקודות הקצה האלה, שנמצאות בכתובות URL מסוג .well-known בתוך מקור הדיווח של הספק, מתארחות בפלטפורמה ומאפשרות לספקי טכנולוגיות הפרסום לגשת אליהן באמצעות Attribution Reporting API או Private Aggregation API.
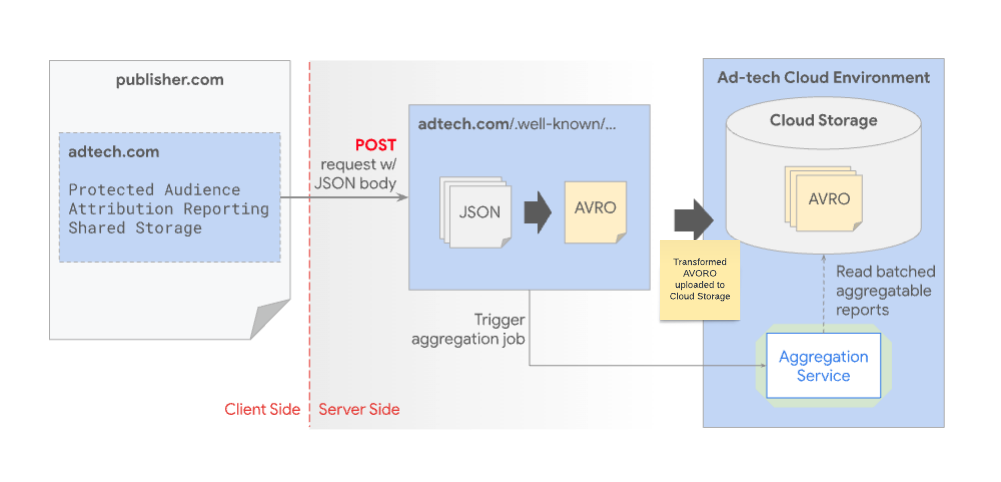
השלבים הבאים מתארים את התהליך של שירות הצבירה לקבלה ולאחסון של דוחות שניתן לצבור אותם:
- כשהאירוע מופעל, הדפדפן שולח דוחות שאפשר לצבור, שמכילים פרטים על נתוני המרות ונתונים מאתרים שונים.
- הדפדפן מעביר את הדוחות המוצפנים לכתובת URL מסוג
.well-knownבדומיין הדיווח של טכנולוגיית הפרסום. - המערכת מעבירה את קבוצות הדוחות לשירות הצבירה לצורך עיבוד.
- שירות הצבירה מסכם את הדוחות באופן סטטיסטי.
- שירות האגרגציה מוסיף רעש לנתונים המסכמים כדי לשפר את פרטיות המשתמשים.
- המערכת מאפשרת לחברת טכנולוגיית הפרסום לגשת לדוחות לצורכי ניתוח ומדידה.
בטבלה הבאה מפורטות נקודות הקצה לניפוי באגים ולפריסה פעילה של Private Aggregation API ושל Attribution Reporting API:
| API | נקודת קצה | תיאור |
|---|---|---|
| Private Aggregation API |
|
|
| Attribution Reporting API |
|
|
מקורות הדיווח מקבלים דוחות JSON באמצעות קריאות POST. לאחר מכן, המערכת ממירה את הדוחות האלה לפורמט Avro ומעבירה אותם לאחסון בענן. אחרי עיבוד באצווה, המערכת שולחת את דוחות ה-Avro ל-Aggregation Service לצורך סיכום.
פלטפורמות של טכנולוגיות פרסום מפעילות בקשה לביצוע עבודה של צבירת נתונים לשירות הצבירת נתונים כשאצווה של דוחות Avro מוכנה לעיבוד. השירות הזה, שמתארח בסביבת הענן של פלטפורמת טכנולוגיית הפרסום, מאחזר את דוחות ה-Avro הנדרשים מאותו מיקום אחסון. מטעמי אבטחה, צריך להגדיר את שירות האגרגציה כך שישתמש בקובץ אימג' מאושר של קונטיינר. במאגר GitHub של ארגז החול לפרטיות/שירות האגרגציה מפורטות קובצי האימג' הזמינים בקונטיינרים.
בהמשך מוצגות דוגמאות מייצגות לדוחות שמוחזרים על ידי כל API:
- דוגמה לדוח של Private Aggregation API:
{
"aggregation_coordinator_origin": "https://publickeyservice.msmt.aws.privacysandboxservices.com",
"aggregation_service_payloads": [ {
"key_id": "1a2baa3f-5d48-46cf-91f0-772633c12640",
"payload": "8Cjr1s3FVkCYkjzBvyzJn14yardVjd5N4vLCA69LQAPbIkJ0B58hAqUGBCNXpvTjW9ZpIoZbCSiUOsUDuoA/S+tqVolLMkame6sWC07cfUmZcVsbU+La3pzTMtCgdtNc8MIWgD3C63CMw7rWroRlechewVUajvAYVK/0HJq0YyGrTiFZZm36zi0jjyHLAXKV8p1Lvy1d0o/wnBxC5oVo5BV6LPkxqQEcoYS2GyixUuht6wD0RzuH+BxxuH6vY/ynp2xDrnwftjvqwDUAxUWLFTunthM6BXZVxlrvOBim1h2dvPqWSyKZ5gafo+MgW9EM4SraavNM3XzZSCjdtAfSMJMrynSu2j0opyAq+9e1jq1xeYN00yZrJ0Y/GTI45IGjgCnVmvmuoI9ucW2SnXP31CQBwHqk4gtUgMsYGFSUYfhtnAQ/8TSbaXyS2LX+cQW87LqkvIraWw6o37O24VFBreFoFFXpu3IUeCZfji+Sr4/ykfZuHeMzQbBavyNnHKzPZlbLSXMiucx4/vWzYyOzHeIlbtupXVvbi40V2PieDShaSbjI266kGgFkeCk6z51AaAGebDPtRT1lhBpcoQ6JdF0Yp5VWSnyFARKFtCZ1aEBrlUlrEHLUQY/pFtmDxJQiicRz1YPjR8jRr3C7hlRhWwov0dMocqnMz5209hHGVZWSsaGc9kWjtxREW2ULXfoIwOGbX+WZsyFW2RhXksQPJ5fhyNc4ROkAzUthLb68gC5e0yZHvmLIAU4hcWe0UanJv+jRljn8PAPaJHKFUxQNJyBA7mTbn5mkpycxGrX6T3ZYdPHqvckqt9llJZWjr8NneizzZFRuJk423BDs38fXkvcTAsAckd2Zu0u2KC45WR93sN2/CWrqB7/QU9BsgNdonl/ehAWhU1LbcRRvBTcR9+0wL7vRL7cv5LG3+gRYRKsWI6U2nDSWp0cNpo9+HU0JNiifa5X0cguihqU2bSk6ABozgRtCZ7m+7eqWXMLSzBdmc1CPUoQppo6Wmf6ujdNqI6v2S6pDH781lph8Z2v7ZpxGdhVVPEL51cVn"
} ],
"debug_key": "1234",
"shared_info": "{\"api\":\"shared-storage\",\"report_id\":\"05e3b948-cb8d-4404-be29-bfeac7ad9710\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1707784729\",\"version\":\"0.1\"}"
}
- דוגמה לדוח של Attribution Reporting API
{
"aggregation_coordinator_origin": "https://publickeyservice.msmt.aws.privacysandboxservices.com",
"aggregation_service_payloads": [ {
"key_id": "2dee0f3f-2aee-4a4a-8238-9154ed3d6f72",
"payload": "pHvTHhcxvNKaCmnLpvYQsXlJpiNRuFO5Zj1QqUlqgWPOfuoHLfiXiFjmpvY8a53/OYnS4bKwHwJReFcofldsu8E9BzTTJ3CEk+B7vbEjnDPaljhpIBMTuQXy3QHGK4slWR/yNZVm2uXRWR/DVVzXziBoTDjN7qaPstRoLKUUMdfY2u8oq4tnLY00Y+NDZttZ4wJvC7hPmvY3lqHjdl14JPD2ytZZ4NViYzno3WKdH/oZc0jhGK4zI38lAM0qpahF/B9yb4zOu7IRIjQpNx73P8naDyddxLldoVlW/qHpO04FguWymscvI/8i6NwUR6Kj8seRlWS0iIUhETt/ai3lilKUHUb+uz0YG2kxjoXq7Ldk+MP56nNl67ZRNi2YZ7bOGI/okYWoT/wt2uWPe/5xAEMmadxl0hQQrG7YXHRSD8rDnaVPXo+AKIxdg727yJeB1ZENZvovl/kIevdRAmdBe2h1U3J6Uz6psly/46fvjgkj5QD+kO2uaYirzvmwS19luJsN/Qvh/R3ZO4qlJIQI0nDJPWwUJ4ODpyVmj4a0xQp3t2ESEnf4EmY7+khn3xpF5+MwEWKES2ZeDf7SHalR99pvZA8G3Fr8M0PWFmT00cmKCBwpQgZyd3Eay70UlqdkbFEedxiCVWKNNOUz41m5KG/7K3aR+dYx57l57Wct4gOFQg3jiUEBJWrFIVCXf12BT5iz5rBQh1N1CUt2oCOhYL/sPuBl6OV5GWHSIj8FUdpoDolqKXWINXfE88MUijE2ghNRpJN25BXIErUQtO9wFQv7zotC6d2BIaF0x8AkKg/7yzBQRySX/FZP3H3lMkpOz9rQMV8DjZ2lz7nV4k6CFo8qhT6cpYJD7GpYl81xJbglNqcJt5Pe5YUHrdBMyAFsTh3yoJvYnhQib/0xVN/a93lbYccxsd0yi375n4Xz0i1HUoe2ps+WlU8XysAUA1agG936eshaY1anTtbJbrcoaH+BNSacKiq4saprgUGl4eDjaR/uBhvUnO52WkmAGon8De3EFMZ/kwpPBNSXi7/MIAMjotsSKBc19bfg"
} ],
"shared_info": "{\"api\":\"attribution-reporting\",\"attribution_destination\":\"https://privacy-sandbox-demos-shop.dev\",\"report_id\":\"5b052748-f5fb-4f14-b291-de03484ed59e\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1707786751\",\"source_registration_time\":\"0\",\"version\":\"0.1\"}",
"source_debug_key": "123456789",
"trigger_debug_key": "123456789"
}
המרת דוחות JSON לדוחות Avro
כדי שאפשר יהיה לצבור דוחות, הם צריכים להיות בפורמט של שרשור נתונים (serialization) של Apache Avro. כדי ליצור דוח Avro, צריך להשתמש בסכימה של AVSC. קובץ הסכימה של AVSC מגדיר את מבנה הרשומה ואת סוג הנתונים של Avro. דוגמה לסכימה של AVSC מופיעה בקובץ example.avsc במאגר GitHub הזה של avrodoc/schemata.
דוגמה לקוד JavaScript מופיעה בקטע Collect, transform and batch reports בדף Collecting and Batching Aggregatable Reports שנמצא במאגר GitHub privacysandbox/aggregation-service.
יש לכם גמישות לאחסן את כל הדוחות בקובץ AVRO אחד או לפצל אותם לכמה קבצים. אין מגבלת גודל לקבצי AVRO, אבל בדרך כלל הביצועים האופטימליים מתקבלים כשמספר הקבצים נע בין מספר מעבדי ה-CPU במכונה בענן ל-1,000.
בדוגמת הקוד הבאה מוצגת סכימה של Avro לדוחות שניתן לצבור אותם. שדות הדוח כוללים את payload, key_id ו-shared_info.
{
"type": "record",
"name": "AggregatableReport",
"fields": [
{
"name": "payload",
"type": "bytes"
},
{
"name": "key_id",
"type": "string"
},
{
"name": "shared_info",
"type": "string"
}
]
}
| פרמטר | סוג | תיאור |
|---|---|---|
payload |
בייטים |
צריך לבצע פענוח base64 של payload ולהמיר אותו למערך בייטים בדוחות חיים או בדוחות ייצור.
|
debug_cleartext_payload |
בייטים |
כדי לקבל דוחות ניפוי באגים, צריך לבצע פענוח של עומס העבודה ב-base64 ולהמיר אותו למערך בייטים מ-debug_cleartext_payload.
|
key_id |
מחרוזת | זוהי המחרוזת key_id שנמצאה בדוח. השדה key_id הוא מזהה ייחודי אוניברסלי באורך 128 ביט. |
shared_info |
מחרוזת | זוהי המחרוזת ללא שינוי או פגיעה שנמצאת בשדה shared_info בדוח. |
דוגמה לדוח JSON:
{
"aggregation_coordinator_identifier": "aws-cloud",
"aggregation_service_payloads": [{
"debug_cleartext_payload": "omRkYXhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAFWW1vcGVyYX",
"key_id": "3c6e2850-edf6-4886-eb70-eb3f2a7a7596",
"payload": "oapYz92Mb1yam9YQ2AnK8dduTt2RwFUSApGcKqXnG1q+aGXfJ5DGpSxMj0NxdZgp7Cq"
}],
"debug_key": "1234",
"shared_info":
"{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"b029b922-93e9-4d66-a8c6-8cdeec762aed\",\"reporting_origin\":\"https://privacy-sandbox-demos-dsp.dev\",\"scheduled_report_time\":\"1719251997\",\"version\":\"0.1\"}"
}
מפרט קובץ הדומיין
כדי ליצור דוחות סיכום באמצעות שירות האגרגציה, נדרשים הדוחות שאפשר לאסוף (דוחות JSON שהוסבו ל-Avro) וקובץ הדומיין המשויך. המערכת מחלצת מפתחות שהוצהרו מראש מהדוחות שאפשר לצבור אותם, ומצרפת אותם לדוחות הסיכום בדומייני הפלט. פרטים על מפתחות הסיכום החשובים האלה מופיעים במאמר הסבר על מפתחות סיכום לדיווח על שיוך ובקטע מפתח סיכום במאמר יסודות של Private Aggregation API. דומיין הפלט כולל גם את השדה bucket שמייצג את ערך מפתח הקטגוריה.
קובץ הדומיין חייב להיות בפורמט Avro באמצעות הסכימה הבאה:
{
"type": "record",
"name": "AggregationBucket",
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "A single bucket that appears in the aggregation service output. It is an 128-bit integer value encoded as a 16-byte big-endian bytestring."
}
]
}
מפתח קטגוריה
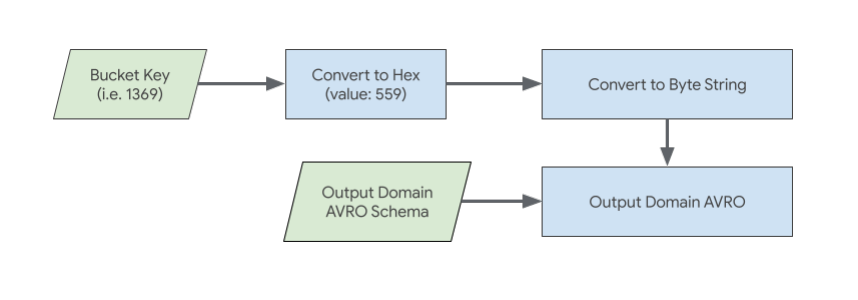
מפתח הקטגוריה בדומיין הפלט חייב להיות מיוצג כמחרוזת של בייטים הקסדצימליים.
לדוגמה:
אם מפתח הקטגוריה הוא הערך העשרוני 1369:
המרת המספר 1369 לערכו המקביל הקסדצימלי: 559
המרת המחרוזת הקסדצימלית '559' למחרוזת בייטים.
לאחר מכן, יש לכלול את הייצוג של מחרוזת הבייטים של מפתח הקטגוריה בסכימת Avro של דומיין הפלט.
שיקולים חשובים:
סוג הנתונים: צריך להגדיר את מפתח הקטגוריה בסכימה של Avro כסוג בייט כדי להתאים לייצוג של מחרוזת בייטים הקסדצימליים.
המרה: אפשר להטמיע את ההמרה מעשרונית לחזקה עשרונית ואז למחרוזת בייט באמצעות Python או Java.
הגישה הזו מבטיחה שהפורמט של מפתח הקטגוריה תקין ותואם לסוג הנתונים הצפוי בתוך הסכימה של Avro לדומיין הפלט.
דוחות באצווה
פרטים על תקציבי פרטיות ועל שיטות ארגון בקבוצות זמינים במסמכי התיעוד בנושא שיטות ארגון בקבוצות. חשוב לזכור שלדוחות שאפשר לצבור יש מגבלה של MAX_REPORT_AGE (כיום 90 ימים) בין scheduled_report_time לבין תאריך ההרצה של האצווה.
דוחות סיכום
אחרי הקיבוץ, שירות הצבירה יוצר את דוח הסיכום בפורמט Avro באמצעות הסכימה results.avsc.
בסיום המשימה, דוח הסיכום נשמר ב-output_data_blob_prefix בקטגוריה output_data_bucket_name כפי שצוין בבקשה createJob.
באצווה של שירות צבירה שבה debug_run מופעל, נוצרים שני דוחות: דוח הסיכום ודוח הסיכום של ניפוי הבאגים. דוח הסיכום של ניפוי הבאגים נמצא בתיקייה output_data_blob_prefix/debug. בדוח הסיכום של ניפוי הבאגים נעשה שימוש בסכימה debug_results.avsc.
גם דוח הסיכום וגם דוח ניפוי הבאגים נקראים [output_data_blob_prefix]-1-of-1.avro. אם הערך של output_data_blob_prefix הוא summary/summary.avro, הדוח נמצא בתיקיית הסיכום בשם summary-1-of-1.avro.
דוגמה ל-results.avsc
סכימה לדוגמה של Avro עבור results.avsc:
{
"type": "record",
"name": "AggregatedFact",
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "Histogram bucket used in aggregation. It is an 128-bit integer value encoded as a 16-byte big-endian bytestring. Leading 0-bits are left out."
},
{
"name": "metric",
"type": "long",
"doc": "The metric associated with the bucket"
}
]
}
הסכימה לדוגמה של Avro מגדירה רשומה בשם AggregatedFact.
דוגמה ל-debug_results.avsc
זוהי דוגמה לסכימה של Avro עבור debug_results.avsc:
{
"type": "record",
"name": "DebugAggregatedFact", Output domains include summary reports that contain pre-declared keys extracted from your aggregatable reports.
"fields": [
{
"name": "bucket",
"type": "bytes",
"doc": "This represents the histogram bucket used in aggregation. It's a 128-bit integer, encoded as a 16-byte big-endian bytestring, with leading zero bytes omitted.."
},
{
"name": "unnoised_metric",
"type": "long",
"doc": "The raw metric for the bucket."
},
{
"name": "noise",
"type": "long",
"doc": "The noise applied to the metric in the regular result."
}
{
"name":"annotations",
"type": {
"type": "array",
"items": {
"type":"enum",
"name":"bucket_tags",
"symbols":["in_domain","in_reports"]
}
}
]
}
לאחר ההמרה, דוח הסיכום ייראה כמו הדוגמה results.json. כשהאפשרות debug_run מופעלת, הדוח של סיכום ניפוי הבאגים מחזיר נתונים דומים לדוגמה של debug_results.json.
פורמט הדוחות של Avro
דוחות Avro שמתקבלים משירות האגרגציה בדרך כלל עומדים בפורמט עקבי. פורמט הדוח של Avro כולל את השדות הבאים:
bucket: מזהה ייחודי של צבירת הנתונים (לדוגמה, \u0005Y).
metric: הערך המצטבר של הקטגוריה המתאימה. לרוב הערך הזה כולל רעש נוסף לשיפור הפרטיות.
לדוגמה:
{
"bucket": "\u0005Y",
"metric": 26308
}
דוגמה ל-debug_results.json
דוחות Debug Avro מ-Aggregation Service ייראו כמו הדוגמה הבאה של debug_results.json. הדוחות האלה כוללים מפתחות קטגוריות, את הערך unnoised_metric (הסיכום של מפתחות הקטגוריות לפני החלת הרעש) ואת הרעש שנוסף למדד הזה.
{
"bucket": "\u0005Y",
"unnoised_metric": 128,
"noise": -17948,
"annotations": [
"in_reports",
"in_domain"
]
}
ההערות מכילות גם את הערכים הבאים:
in_reports: מפתח הקטגוריה שזמין בדוחות שאפשר לצבורin_domain: מפתח הקטגוריה שזמין בקובץ Avrooutput_domain