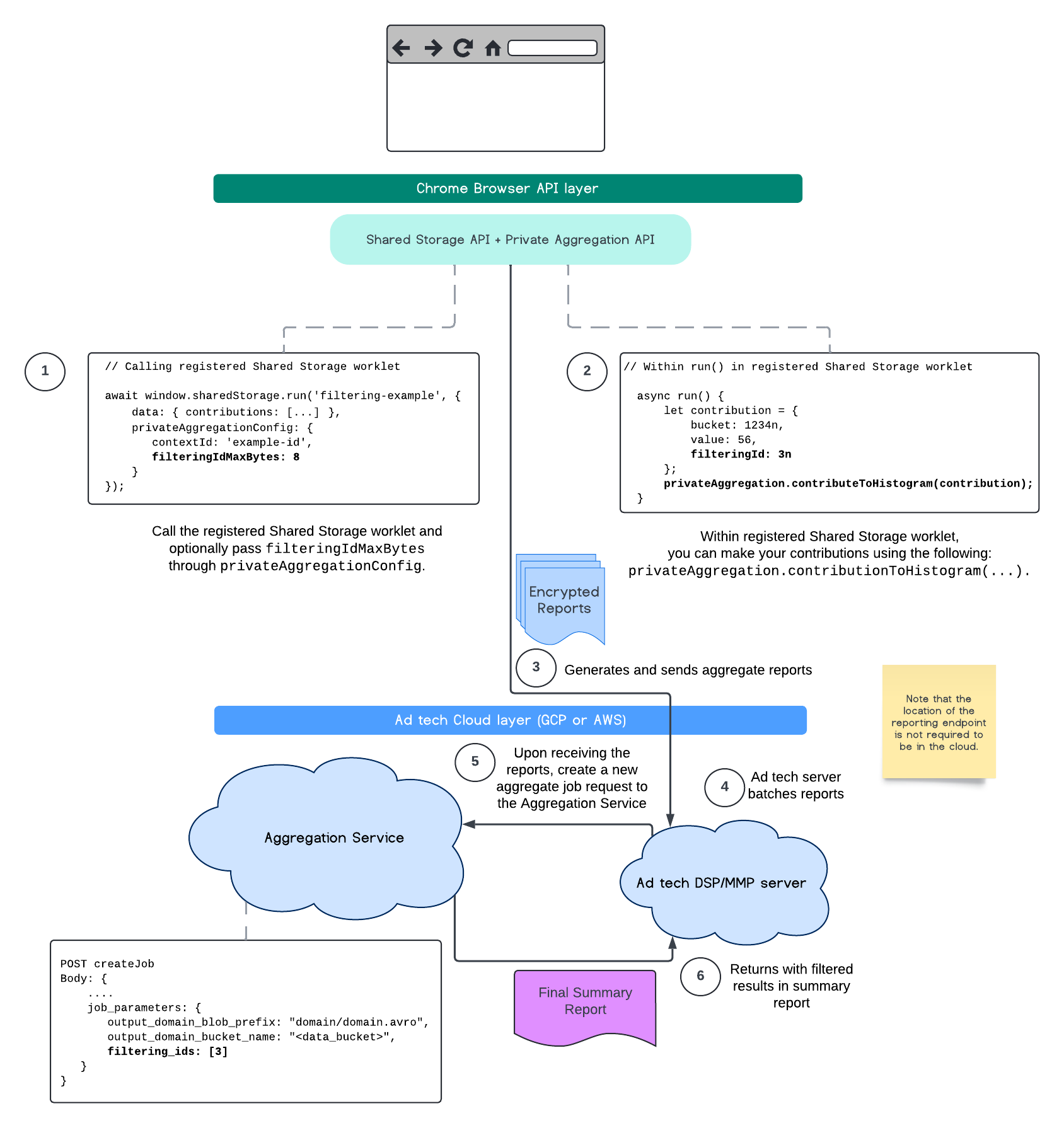
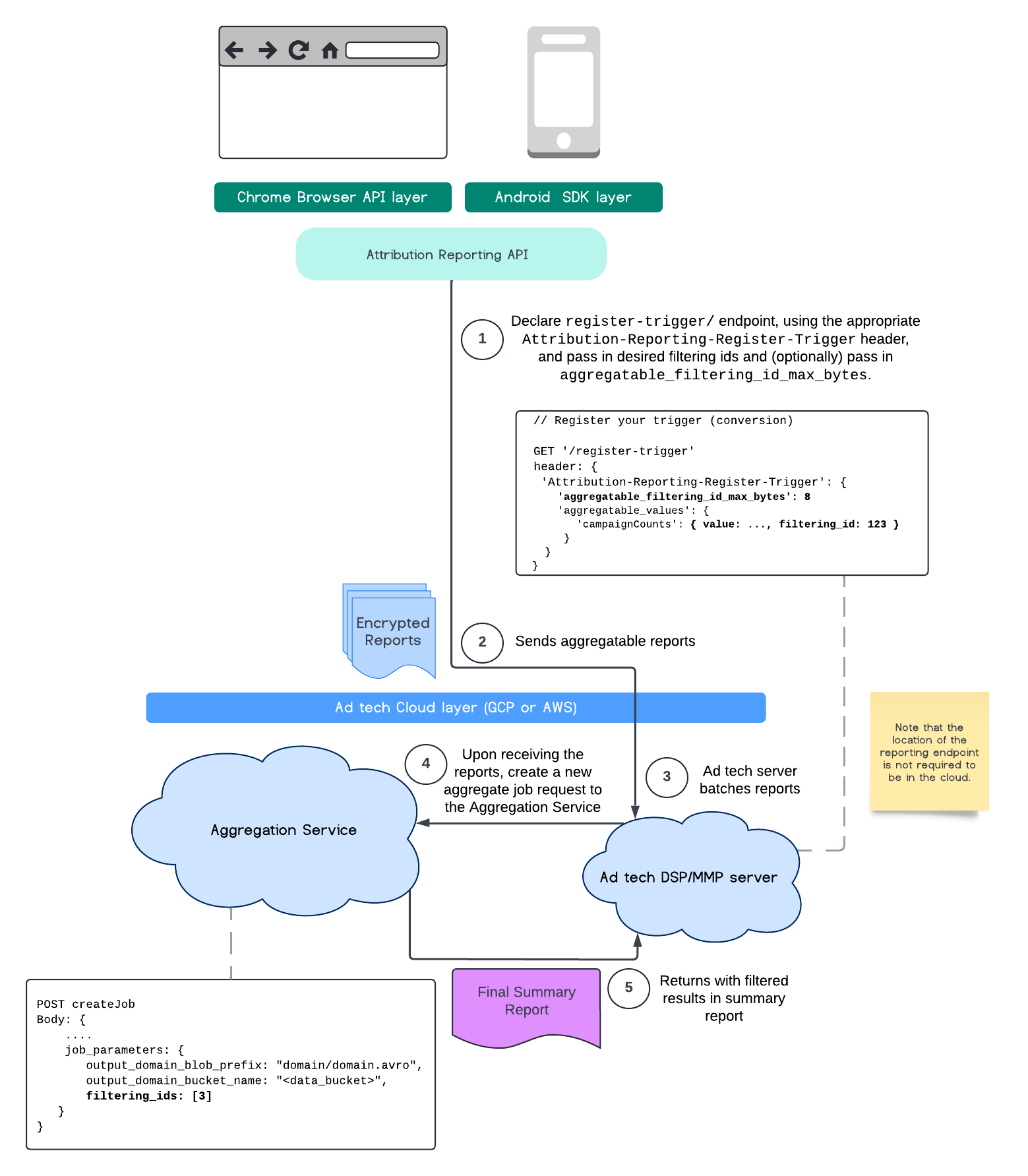
At this time, with the Aggregation Service, you may now process certain measurements at different cadences by leveraging filtering IDs. Filtering IDs can now be passed on job creation within your Aggregation Service like so:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
In order to use this filtering implementation, it's recommended to start from the measurement client APIs (Attribution Reporting API or Private Aggregation API) and pass in your filtering IDs. These will be passed to your deployed Aggregation Service, so that your final summary report returns back with expected filtered results.
If you are concerned with how this will affect your budget, your aggregate report account budget will only be consumed for filtering IDs that are specified in your job_parameters for reports. This way, you will be able to re-run jobs for the same reports specifying different filtering IDs without running into budget exhaustion errors.
The following flow depicts how you can make use of this within the Private Aggregation API, Shared Storage API, and through to Aggregation Service in your public cloud.
This flow depicts how to make use of filtering IDs with Attribution Reporting API and through to Aggregation Service in your public cloud.
For further reading, check out the Attribution Reporting API explainer and Private Aggregation API explainer, as well as the initial proposal.
Continue to our Attribution Reporting API or Private Aggregation API sections to read for a more detailed account. You can read more on the createJob and getJob endpoints in the Aggregation Service API documentation.