Pour configurer votre environnement afin de commencer à implémenter FedCM, vous avez besoin d'un contexte sécurisé (HTTPS ou localhost) à la fois sur l'IDP et la RP dans Chrome.
Bloquer les cookies tiers
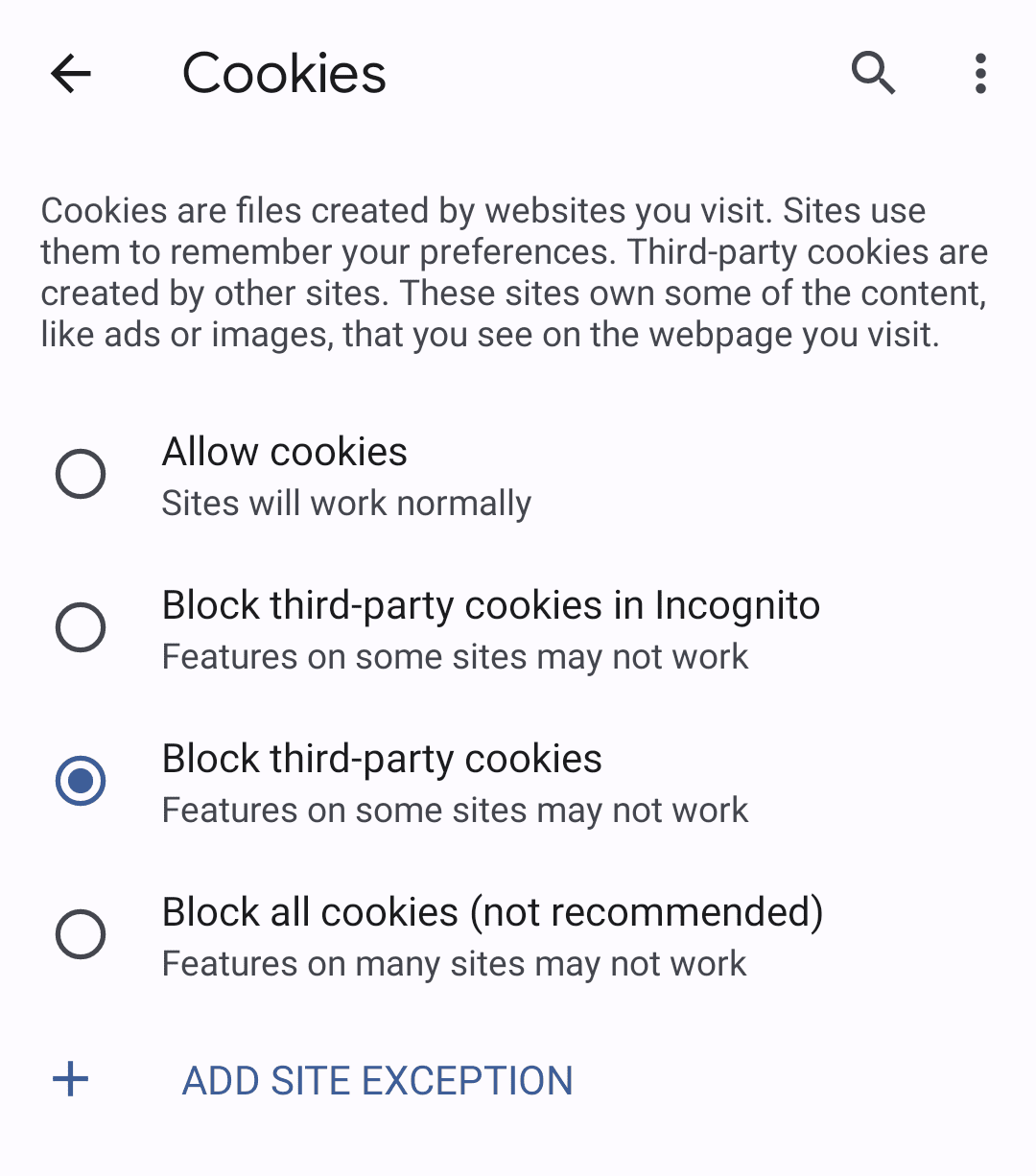
Vous pouvez tester le fonctionnement de FedCM sans cookies tiers dans Chrome.
Pour bloquer les cookies tiers, utilisez le mode navigation privée, ou sélectionnez "Bloquer les cookies tiers" dans les paramètres de votre ordinateur à l'adresse chrome://settings/cookies ou sur votre appareil mobile en accédant à Paramètres > Paramètres du site > Cookies.
Déboguer sur un ordinateur
Nous mettons tout en œuvre pour améliorer l'expérience de débogage FedCM avec DevTools.
Pendant que ces fonctionnalités sont en cours de développement, vous pouvez utiliser les journaux des requêtes réseau chrome://net-export:
- Accédez à
chrome://net-export. Cochez la case "Inclure les octets bruts", puis cliquez sur "Start Logging to Disk" (Commencer la journalisation sur disque). Sélectionnez un emplacement pour enregistrer les journaux lorsque vous y êtes invité.
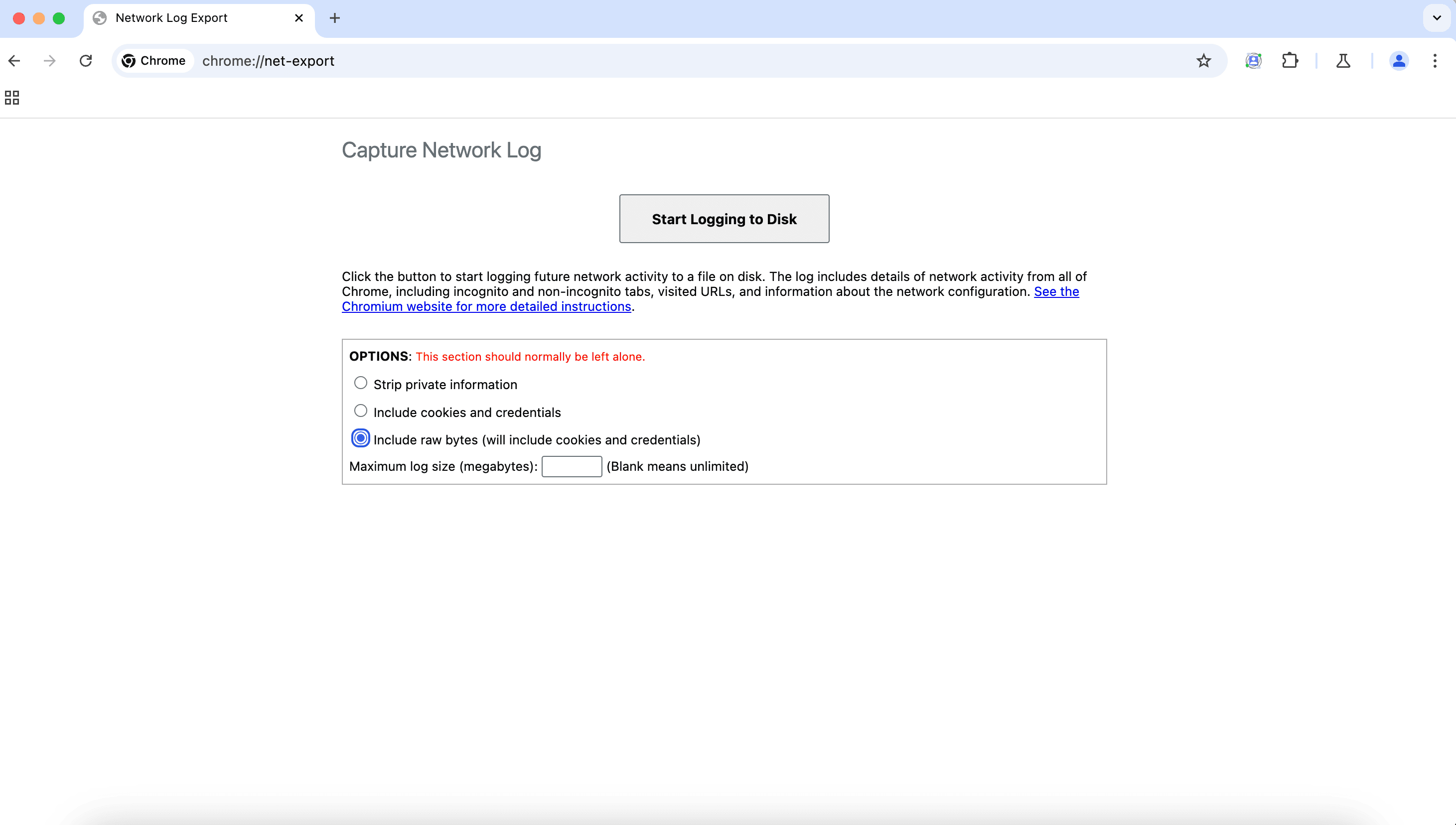
Interface de l'outil Net-export: démarrage Ouvrez une page qui appelle FedCM, par exemple la RP de démonstration.
Suivez le flux FedCM que vous souhaitez déboguer (par exemple, l'inscription d'un utilisateur).
Accédez à
chrome://net-export, puis appuyez sur "Arrêter la journalisation".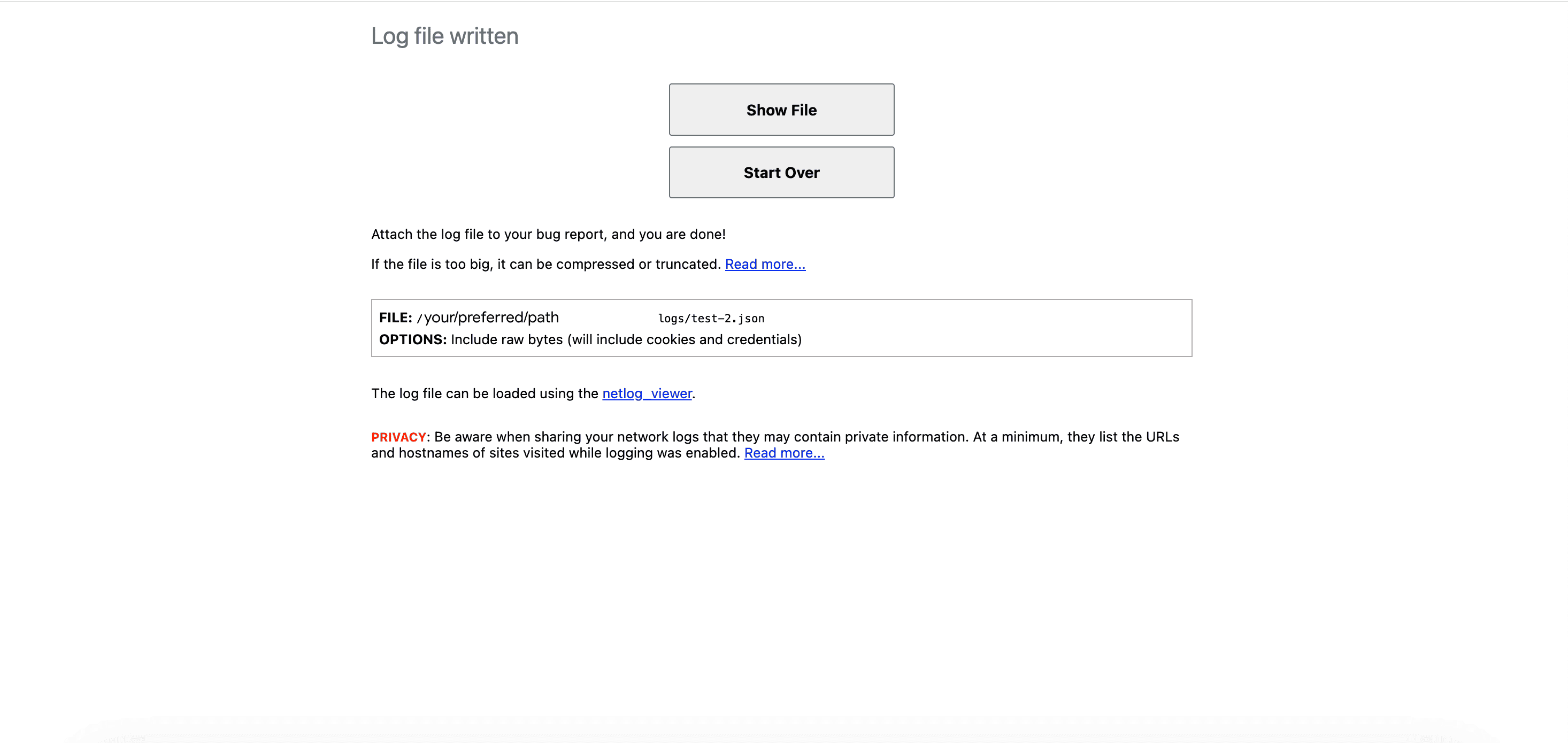
Interface de l'outil Net-export: fin de l'enregistrement sur disque Ouvrez vos journaux à l'aide de l'outil de visionnage de journaux de votre choix, par exemple NetLog Viewer.
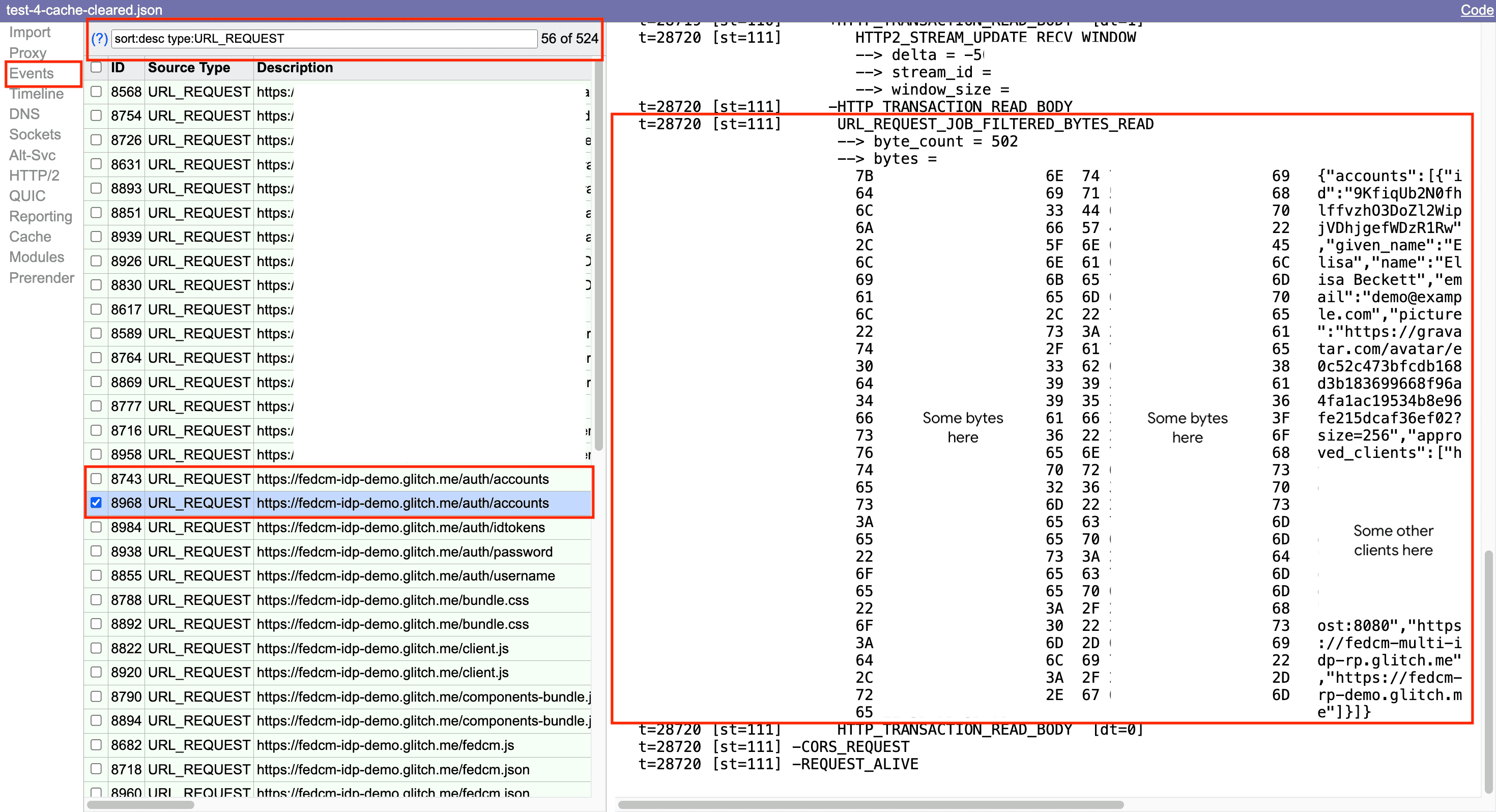
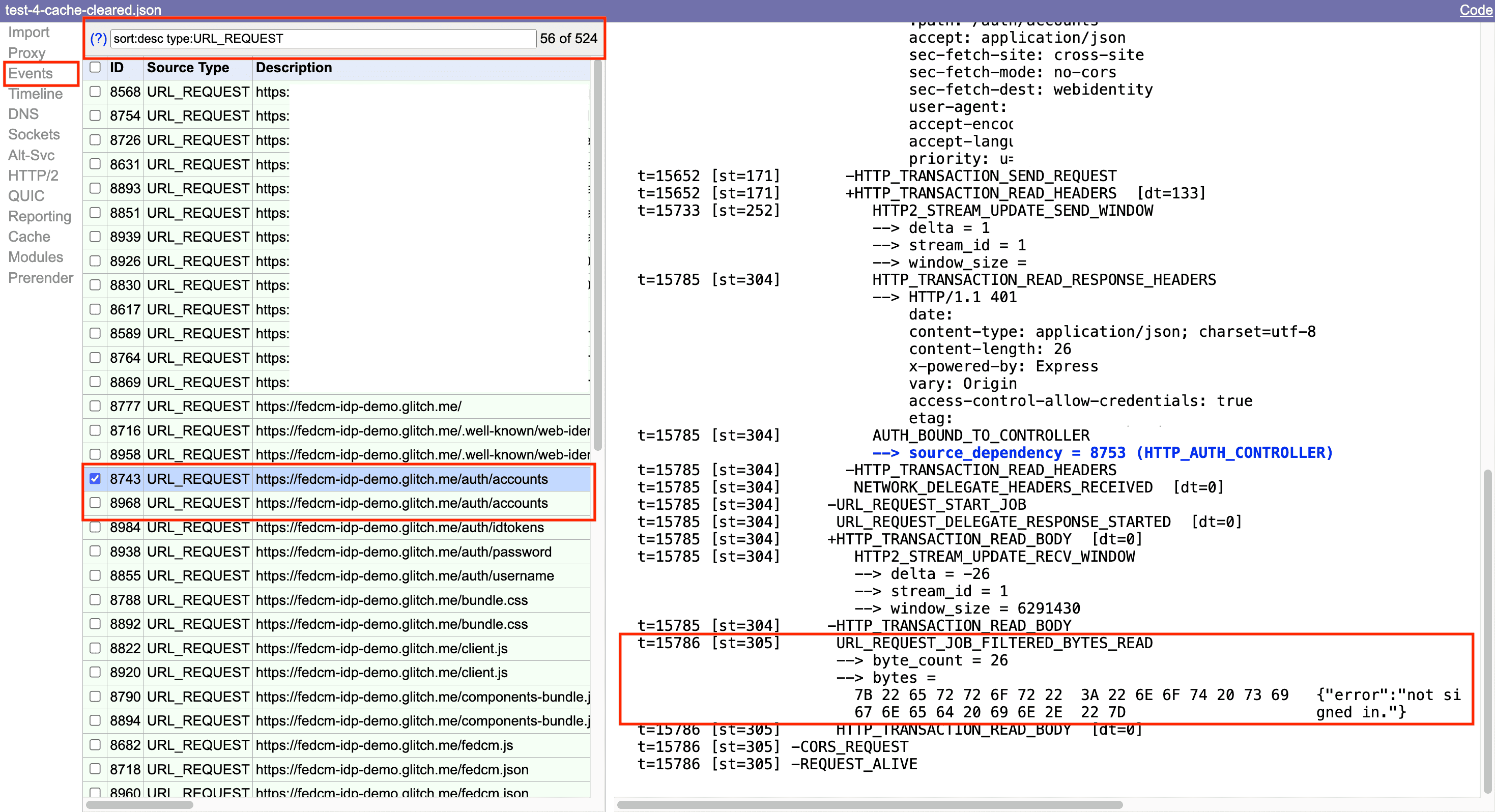
Lorsque vous utilisez l'outil de visualisation NetLog, sélectionnez
Eventsdans le panneau de gauche et appliquez le filtretype:URL_REQUEST.
Dans cet exemple, les journaux indiquent que deux requêtes ont été envoyées au point de terminaison accounts.
Cela se produit parce que l'utilisateur n'était pas connecté à l'IDP lors de sa première visite sur la page. URL_REQUEST_JOB_FILTERED_BYTES_READ indique que le serveur a répondu avec un message d'erreur dans le corps de la réponse: { error: "not signed in."
}.
La deuxième requête /accounts a abouti, et l'IDP a répondu avec les données du compte: