
Google Cloud Search स्कीमा, एक JSON स्ट्रक्चर है. इसमें आपके डेटा को इंडेक्स करने और उस पर क्वेरी करने के लिए इस्तेमाल किए जाने वाले ऑब्जेक्ट, प्रॉपर्टी, और विकल्पों के बारे में बताया जाता है. आपका कॉन्टेंट कनेक्टर, आपकी रिपॉज़िटरी से डेटा पढ़ता है. साथ ही, रजिस्टर किए गए स्कीमा के आधार पर, डेटा को स्ट्रक्चर करता है और उसे इंडेक्स करता है.
एपीआई को JSON स्कीमा ऑब्जेक्ट देकर और फिर उसे रजिस्टर करके, स्कीमा बनाया जा सकता है. डेटा को इंडेक्स करने से पहले, आपको हर रिपॉज़िटरी के लिए स्कीमा ऑब्जेक्ट रजिस्टर करना होगा.
इस दस्तावेज़ में, स्कीमा बनाने के बारे में बुनियादी जानकारी दी गई है. खोज के अनुभव को बेहतर बनाने के लिए, अपने स्कीमा को ट्यून करने का तरीका जानने के लिए, खोज की क्वालिटी को बेहतर बनाना लेख पढ़ें.
स्कीमा बनाएं
Cloud Search स्कीमा बनाने के लिए, यहां दिया गया तरीका अपनाएं:
- उपयोगकर्ता के संभावित व्यवहार की पहचान करना
- डेटा सोर्स को शुरू करना
- स्कीमा बनाना
- पूरा सैंपल स्कीमा
- स्कीमा रजिस्टर करना
- अपना डेटा इंडेक्स करना
- अपने स्कीमा की जांच करना
- स्कीमा को ट्यून करना
उपयोगकर्ता के संभावित व्यवहार की पहचान करना
यह अनुमान लगाने से कि आपके उपयोगकर्ता किस तरह की क्वेरी करते हैं, आपको स्कीमा बनाने के लिए अपनी रणनीति तय करने में मदद मिलती है.
उदाहरण के लिए, किसी फ़िल्म डेटाबेस के लिए क्वेरी जारी करते समय, हो सकता है कि आप उपयोगकर्ता की क्वेरी का अनुमान लगा सकें. जैसे, "मुझे रॉबर्ट रेडफ़ोर्ड की सभी फ़िल्में दिखाओ." इसलिए, आपके स्कीमा में "किसी खास कलाकार की सभी फ़िल्मों" के आधार पर क्वेरी के नतीजे दिखाने की सुविधा होनी चाहिए.
अपने उपयोगकर्ता के व्यवहार के पैटर्न को दिखाने के लिए, अपने स्कीमा को तय करने के लिए, ये काम करें:
- अलग-अलग उपयोगकर्ताओं की पसंदीदा क्वेरी के अलग-अलग सेट का आकलन करें.
- उन ऑब्जेक्ट की पहचान करें जिनका इस्तेमाल क्वेरी में किया जा सकता है. ऑब्जेक्ट, मिलते-जुलते डेटा के लॉजिकल सेट होते हैं. जैसे, फ़िल्मों के डेटाबेस में कोई फ़िल्म.
- उन प्रॉपर्टी और वैल्यू की पहचान करें जो ऑब्जेक्ट बनाती हैं और जिनका इस्तेमाल क्वेरी में किया जा सकता है. प्रॉपर्टी, ऑब्जेक्ट के इंडेक्स किए जा सकने वाले एट्रिब्यूट होते हैं. इनमें प्राइमिटिव वैल्यू या अन्य ऑब्जेक्ट शामिल हो सकते हैं. उदाहरण के लिए, किसी मूवी ऑब्जेक्ट में, मूवी के टाइटल और रिलीज़ की तारीख जैसी प्रॉपर्टी, प्राइमिटिव वैल्यू के तौर पर हो सकती हैं. मूवी ऑब्जेक्ट में, कलाकारों जैसे अन्य ऑब्जेक्ट भी हो सकते हैं. इन ऑब्जेक्ट की अपनी प्रॉपर्टी होती हैं, जैसे कि नाम या भूमिका.
- प्रॉपर्टी के लिए मान्य वैल्यू के उदाहरण की पहचान करना. वैल्यू, किसी प्रॉपर्टी के लिए इंडेक्स किया गया असल डेटा होता है. उदाहरण के लिए, आपके डेटाबेस में किसी फ़िल्म का टाइटल "Raiders of the Lost Ark" हो सकता है.
- अपने उपयोगकर्ताओं के हिसाब से, क्रम से लगाने और रैंकिंग के विकल्प तय करें. उदाहरण के लिए, फ़िल्मों के बारे में क्वेरी करते समय, हो सकता है कि उपयोगकर्ता समय के हिसाब से क्रम में लगाना चाहें और दर्शकों की रेटिंग के हिसाब से रैंक करना चाहें. उन्हें टाइटल के हिसाब से, वर्णमाला के क्रम में लगाने की ज़रूरत नहीं है.
- (ज़रूरी नहीं) देखें कि आपकी कोई प्रॉपर्टी, किसी खास कॉन्टेक्स्ट के बारे में बताती है या नहीं. जैसे, उपयोगकर्ता की नौकरी की भूमिका या विभाग. इससे, कॉन्टेक्स्ट के आधार पर अपने-आप पूरा होने वाले सुझाव दिए जा सकते हैं. उदाहरण के लिए, हो सकता है कि फ़िल्मों का डेटाबेस खोजने वाले लोगों की दिलचस्पी सिर्फ़ किसी खास शैली की फ़िल्मों में हो. उपयोगकर्ता यह तय कर सकते हैं कि उन्हें किस तरह के वीडियो के सुझाव चाहिए. ऐसा, शायद उनकी उपयोगकर्ता प्रोफ़ाइल के तौर पर किया जा सकता है. इसके बाद, जब कोई उपयोगकर्ता फ़िल्मों के लिए क्वेरी टाइप करना शुरू करता है, तो ऑटोमैटिक तरीके से सुझाव देने की सुविधा के तहत, उसे सिर्फ़ अपनी पसंदीदा शैली की फ़िल्में सुझाई जाती हैं. जैसे,"ऐक्शन फ़िल्में".
- इन ऑब्जेक्ट, प्रॉपर्टी, और उदाहरण के तौर पर दी गई वैल्यू की सूची बनाएं, जिनका इस्तेमाल खोजों में किया जा सकता है. (इस सूची का इस्तेमाल करने के तरीके के बारे में जानकारी पाने के लिए, ऑपरेटर के विकल्प तय करना सेक्शन देखें.)
डेटा सोर्स को शुरू करना
डेटा सोर्स, किसी ऐसी रिपॉज़िटरी के डेटा को दिखाता है जिसे इंडेक्स किया गया है और Google Cloud में सेव किया गया है. डेटा सोर्स को शुरू करने के निर्देशों के लिए, तीसरे पक्ष के डेटा सोर्स मैनेज करना लेख पढ़ें.
उपयोगकर्ता के खोज के नतीजे, डेटा सोर्स से दिखाए जाते हैं. जब कोई उपयोगकर्ता खोज के नतीजे पर क्लिक करता है, तो Cloud Search, इंडेक्स करने के अनुरोध में दिए गए यूआरएल का इस्तेमाल करके, उपयोगकर्ता को असली आइटम पर ले जाता है.
अपने ऑब्जेक्ट तय करना
स्कीमा में डेटा की बुनियादी इकाई ऑब्जेक्ट होती है. इसे "स्कीमा ऑब्जेक्ट" भी कहा जाता है. यह डेटा का लॉजिकल स्ट्रक्चर होता है. फ़िल्मों के डेटाबेस में, डेटा का एक लॉजिकल स्ट्रक्चर "movie" होता है. मूवी में शामिल कलाकारों और क्रू को दिखाने के लिए, "person" एक और ऑब्जेक्ट हो सकता है.
स्कीमा में मौजूद हर ऑब्जेक्ट में प्रॉपर्टी या एट्रिब्यूट की एक सीरीज़ होती है. इनसे ऑब्जेक्ट के बारे में जानकारी मिलती है. जैसे, किसी फ़िल्म का टाइटल और अवधि या किसी व्यक्ति का नाम और जन्म की तारीख. किसी ऑब्जेक्ट की प्रॉपर्टी में प्राइमिटिव वैल्यू या दूसरे ऑब्जेक्ट शामिल हो सकते हैं.
पहली इमेज में, फ़िल्म और व्यक्ति के ऑब्जेक्ट और उनसे जुड़ी प्रॉपर्टी दिखाई गई हैं.
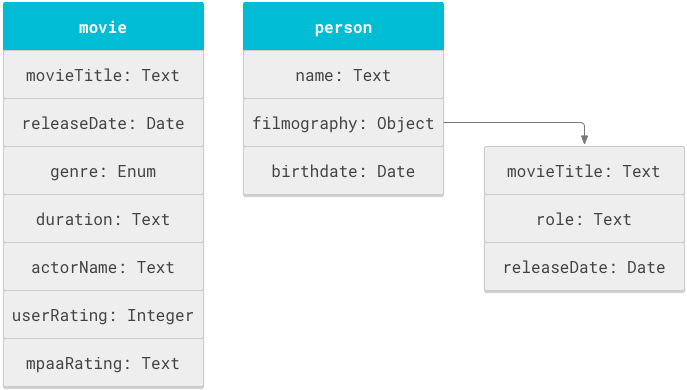
Cloud Search स्कीमा, objectDefinitions टैग में बताए गए ऑब्जेक्ट की परिभाषा वाले स्टेटमेंट की सूची होती है. यहां दिया गया स्कीमा स्निपेट, फ़िल्म और व्यक्ति के स्कीमा ऑब्जेक्ट के लिए objectDefinitions स्टेटमेंट दिखाता है.
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
स्कीमा ऑब्जेक्ट तय करते समय, आपको ऑब्जेक्ट के लिए एक name देना होता है. यह name, स्कीमा के सभी अन्य ऑब्जेक्ट से यूनीक होना चाहिए. आम तौर पर, name
वैल्यू का इस्तेमाल किया जाता है, जो ऑब्जेक्ट के बारे में बताती है. जैसे, फ़िल्म ऑब्जेक्ट के लिए movie. स्कीमा सेवा, इंडेक्स किए जा सकने वाले ऑब्जेक्ट के लिए, name फ़ील्ड का इस्तेमाल मुख्य आइडेंटिफ़ायर के तौर पर करती है. name फ़ील्ड के बारे में ज़्यादा जानकारी के लिए, ऑब्जेक्ट की परिभाषा देखें.
ऑब्जेक्ट प्रॉपर्टी तय करना
ObjectDefinition के रेफ़रंस में बताए गए तरीके के मुताबिक, ऑब्जेक्ट के नाम के बाद options का एक सेट और propertyDefinitions की एक सूची होती है.
options में, freshnessOptions और displayOptions भी शामिल हो सकते हैं.
freshnessOptions का इस्तेमाल, किसी आइटम के नए होने के आधार पर खोज रैंकिंग में बदलाव करने के लिए किया जाता है. displayOptions का इस्तेमाल यह तय करने के लिए किया जाता है कि किसी ऑब्जेक्ट के खोज नतीजों में, खास लेबल और प्रॉपर्टी दिखेंगी या नहीं.
propertyDefinitions सेक्शन में, किसी ऑब्जेक्ट की प्रॉपर्टी तय की जाती हैं. जैसे, फ़िल्म का नाम और रिलीज़ की तारीख.
इस स्निपेट में, दो प्रॉपर्टी वाला movie ऑब्जेक्ट दिखाया गया है: movieTitle और releaseDate.
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
PropertyDefinition में ये आइटम शामिल होते हैं:
nameस्ट्रिंग.- अलग-अलग टाइप के विकल्पों की सूची. जैसे, पिछले स्निपेट में
isReturnable. - टाइप और उससे जुड़े टाइप के हिसाब से विकल्प, जैसे कि पिछले स्निपेट में
textPropertyOptionsऔरretrievalImportance. operatorOptions, जिसमें बताया गया हो कि प्रॉपर्टी का इस्तेमाल खोज ऑपरेटर के तौर पर कैसे किया जाता है.- एक या उससे ज़्यादा
displayOptions, जैसे कि पिछले स्निपेट मेंdisplayLabel.
किसी प्रॉपर्टी का name, उसमें शामिल ऑब्जेक्ट में यूनीक होना चाहिए. हालांकि, उसी नाम का इस्तेमाल दूसरे ऑब्जेक्ट और सब-ऑब्जेक्ट में किया जा सकता है.
पहली इमेज में, मूवी का टाइटल और रिलीज़ की तारीख दो बार दी गई है: एक बार movie ऑब्जेक्ट में और फिर person ऑब्जेक्ट के filmography सब-ऑब्जेक्ट में. यह स्कीमा, movieTitle फ़ील्ड का फिर से इस्तेमाल करता है, ताकि स्कीमा दो तरह के सर्च व्यवहार के साथ काम कर सके:
- जब उपयोगकर्ता किसी फ़िल्म का टाइटल खोजते हैं, तब उन्हें फ़िल्म के नतीजे दिखाएं.
- जब उपयोगकर्ता किसी ऐसी फ़िल्म का टाइटल खोजते हैं जिसमें किसी कलाकार ने काम किया है, तो उन्हें लोगों के नतीजे दिखाएं.
इसी तरह, स्कीमा releaseDate फ़ील्ड का फिर से इस्तेमाल करता है, क्योंकि दोनों movieTitle फ़ील्ड के लिए इसका मतलब एक ही होता है.
अपना स्कीमा बनाते समय, इस बात का ध्यान रखें कि आपकी रिपॉज़िटरी में ऐसे मिलते-जुलते फ़ील्ड कैसे हो सकते हैं जिनमें ऐसा डेटा हो जिसे आपको अपने स्कीमा में एक से ज़्यादा बार एलान करना है.
टाइप के हिसाब से विकल्प जोड़ना
PropertyDefinition में, खोज के सामान्य फ़ंक्शन के विकल्पों की सूची दी गई है. ये विकल्प, सभी प्रॉपर्टी के लिए एक जैसे होते हैं. भले ही, डेटा टाइप कोई भी हो.
isReturnable- इससे पता चलता है कि प्रॉपर्टी में उस डेटा की पहचान की जाती है जिसे क्वेरी एपीआई के ज़रिए खोज के नतीजों में दिखाया जाना चाहिए. फ़िल्म की उदाहरण के तौर पर दी गई सभी प्रॉपर्टी को लौटाया जा सकता है. नतीजे न दिखाने वाली प्रॉपर्टी का इस्तेमाल, उपयोगकर्ता को नतीजे दिखाए बिना, खोजने या रैंक करने के लिए किया जा सकता है.isRepeatable- इससे पता चलता है कि प्रॉपर्टी के लिए एक से ज़्यादा वैल्यू सबमिट की जा सकती हैं या नहीं. उदाहरण के लिए, किसी फ़िल्म की रिलीज़ की सिर्फ़ एक तारीख होती है, लेकिन उसमें कई कलाकार हो सकते हैं.isSortable- इससे पता चलता है कि प्रॉपर्टी का इस्तेमाल, क्रम से लगाने के लिए किया जा सकता है. यह बात, दोबारा इस्तेमाल की जा सकने वाली प्रॉपर्टी के लिए सही नहीं है. उदाहरण के लिए, फ़िल्म के नतीजों को रिलीज़ की तारीख या ऑडियंस रेटिंग के हिसाब से क्रम में लगाया जा सकता है.isFacetable- इससे पता चलता है कि प्रॉपर्टी का इस्तेमाल फ़ेसेट जनरेट करने के लिए किया जा सकता है. फ़ेसेट का इस्तेमाल, खोज के नतीजों को बेहतर बनाने के लिए किया जाता है. इसमें उपयोगकर्ता को शुरुआती नतीजे दिखते हैं. इसके बाद, उन नतीजों को बेहतर बनाने के लिए, वह शर्तें या फ़ेसेट जोड़ता है. यह विकल्प उन प्रॉपर्टी के लिए सही नहीं हो सकता जिनका टाइप ऑब्जेक्ट है. साथ ही, इस विकल्प को सेट करने के लिए,isReturnableकी वैल्यू 'सही' होनी चाहिए. आखिर में, यह विकल्प सिर्फ़ एनम, बूलियन, और टेक्स्ट प्रॉपर्टी के लिए काम करता है. उदाहरण के लिए, अपने सैंपल स्कीमा में, हमgenre,actorName,userRating, औरmpaaRatingफ़ेसटेबल बना सकते हैं, ताकि इनका इस्तेमाल खोज के नतीजों को बेहतर बनाने के लिए किया जा सके.isWildcardSearchableसे पता चलता है कि उपयोगकर्ता इस प्रॉपर्टी के लिए वाइल्डकार्ड खोज कर सकते हैं. यह विकल्प सिर्फ़ टेक्स्ट प्रॉपर्टी पर उपलब्ध है. टेक्स्ट फ़ील्ड में वाइल्डकार्ड खोज का तरीका, exactMatchWithOperator फ़ील्ड में सेट की गई वैल्यू पर निर्भर करता है. अगरexactMatchWithOperatorकोtrueपर सेट किया जाता है, तो टेक्स्ट वैल्यू को एक एटमिक वैल्यू के तौर पर टोकन किया जाता है और उसके आधार पर वाइल्डकार्ड खोज की जाती है. उदाहरण के लिए, अगर टेक्स्ट वैल्यूscience-fictionहै, तो वाइल्डकार्ड क्वेरीscience-*उससे मैच होती है. अगरexactMatchWithOperatorकोfalseपर सेट किया जाता है, तो टेक्स्ट वैल्यू को टोकन में बदल दिया जाता है और हर टोकन के लिए वाइल्डकार्ड खोज की जाती है. उदाहरण के लिए, अगर टेक्स्ट वैल्यू "साइंस-फ़िक्शन" है, तो वाइल्डकार्ड क्वेरीsci*याfi*, आइटम से मैच करती है, लेकिनscience-*मैच नहीं करती.
खोज की सामान्य सुविधाओं के ये पैरामीटर, सभी बूलियन वैल्यू हैं. इनकी डिफ़ॉल्ट वैल्यू false होती है. इनका इस्तेमाल करने के लिए, इन्हें true पर सेट करना ज़रूरी है.
नीचे दी गई टेबल में, ऐसे बूलियन पैरामीटर दिखाए गए हैं जिन्हें movie ऑब्जेक्ट की सभी प्रॉपर्टी के लिए true पर सेट किया गया है:
| प्रॉपर्टी | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
सही | सही | |||
releaseDate |
सही | सही | |||
genre |
सही | सही | सही | ||
duration |
सही | ||||
actorName |
सही | सही | सही | सही | |
userRating |
सही | सही | |||
mpaaRating |
सही | सही |
genre और actorName, दोनों के लिए isRepeatable को true पर सेट किया गया है, क्योंकि कोई फ़िल्म एक से ज़्यादा शैलियों में हो सकती है और आम तौर पर उसमें एक से ज़्यादा कलाकार होते हैं. अगर किसी प्रॉपर्टी को दोहराया जा सकता है या वह दोहराए जा सकने वाले किसी सब-ऑब्जेक्ट में शामिल है, तो उसे क्रम से नहीं लगाया जा सकता.
टाइप तय करना
PropertyDefinition रेफ़रंस सेक्शन में कई xxPropertyOptions की सूची दी गई है. इसमें xx एक खास टाइप है, जैसे कि boolean. प्रॉपर्टी का डेटा टाइप सेट करने के लिए, आपको सही डेटा-टाइप ऑब्जेक्ट तय करना होगा. किसी प्रॉपर्टी के लिए डेटा टाइप ऑब्जेक्ट तय करने पर, उस प्रॉपर्टी का डेटा टाइप तय हो जाता है. उदाहरण के लिए, movieTitle प्रॉपर्टी के लिए textPropertyOptions तय करने से पता चलता है कि फ़िल्म का टाइटल टेक्स्ट टाइप का है. नीचे दिया गया स्निपेट, movieTitle प्रॉपर्टी के साथ textPropertyOptions को डेटा टाइप सेट करते हुए दिखाता है.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
किसी प्रॉपर्टी में सिर्फ़ एक तरह का डेटा हो सकता है. उदाहरण के लिए, हमारी फ़िल्म के स्कीमा में, releaseDate सिर्फ़ तारीख हो सकती है (जैसे, 2016-01-13) या स्ट्रिंग (उदाहरण के लिए, January 13, 2016) का इस्तेमाल किया जा सकता है, लेकिन दोनों का नहीं.
यहां डेटा-टाइप ऑब्जेक्ट दिए गए हैं. इनका इस्तेमाल, सैंपल मूवी स्कीमा में प्रॉपर्टी के लिए डेटा टाइप तय करने के लिए किया जाता है:
| प्रॉपर्टी | डेटा टाइप ऑब्जेक्ट |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
प्रॉपर्टी के लिए चुना गया डेटा टाइप, आपके इस्तेमाल के उदाहरणों पर निर्भर करता है.
इस फ़िल्म स्कीमा की कल्पना की गई स्थिति में, उपयोगकर्ताओं को नतीजों को समय के हिसाब से क्रम में लगाना होगा. इसलिए, releaseDate एक तारीख ऑब्जेक्ट है.
उदाहरण के लिए, अगर आपको साल भर में रिलीज़ होने वाली दिसंबर की रिलीज़ की तुलना, जनवरी की रिलीज़ से करनी है, तो स्ट्रिंग फ़ॉर्मैट का इस्तेमाल किया जा सकता है.
टाइप के हिसाब से विकल्प कॉन्फ़िगर करना
PropertyDefinition रेफ़रंस सेक्शन में, हर टाइप के विकल्पों के लिंक होते हैं. टाइप के हिसाब से दिए गए ज़्यादातर विकल्प ज़रूरी नहीं हैं. हालांकि, enumPropertyOptions में possibleValues की सूची को चुनना ज़रूरी है. इसके अलावा, orderedRanking विकल्प की मदद से, वैल्यू को एक-दूसरे के हिसाब से रैंक किया जा सकता है. यहां दिए गए स्निपेट में, movieTitle प्रॉपर्टी को डेटा टाइप textPropertyOptions और टाइप के हिसाब से retrievalImportance विकल्प के साथ दिखाया गया है.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
यहां सैंपल स्कीमा में इस्तेमाल किए गए, टाइप के हिसाब से अन्य विकल्प दिए गए हैं:
| प्रॉपर्टी | टाइप | टाइप के हिसाब से विकल्प |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking, maximumValue |
mpaaRating |
textPropertyOptions |
ऑपरेटर के विकल्प तय करना
टाइप के हिसाब से विकल्पों के अलावा, हर टाइप के लिए वैकल्पिक विकल्पों का एक सेट होता हैoperatorOptions इन विकल्पों से पता चलता है कि प्रॉपर्टी का इस्तेमाल खोज ऑपरेटर के तौर पर कैसे किया जाता है. यहां दिया गया स्निपेट, movieTitle प्रॉपर्टी को दिखाता है. इसमें, डेटा टाइप को सेट करने के लिए textPropertyOptions और टाइप के हिसाब से retrievalImportance और operatorOptions विकल्पों का इस्तेमाल किया गया है.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
हर operatorOptions का एक operatorName होता है, जैसे कि movieTitle के लिए title. ऑपरेटर का नाम, प्रॉपर्टी के लिए सर्च ऑपरेटर होता है. सर्च ऑपरेटर, वह असल पैरामीटर होता है जिसका इस्तेमाल करके उपयोगकर्ता, खोज के नतीजों को सटीक बनाते हैं. उदाहरण के लिए, फ़िल्मों को उनके टाइटल के हिसाब से खोजने के लिए, उपयोगकर्ता title:movieName टाइप करेगा. यहां movieName, फ़िल्म का नाम है.
यह ज़रूरी नहीं है कि ऑपरेटर का नाम, प्रॉपर्टी के नाम से मेल खाए. इसके बजाय, आपको ऑपरेटर के ऐसे नाम इस्तेमाल करने चाहिए जो आपके संगठन के उपयोगकर्ताओं के सबसे ज़्यादा इस्तेमाल किए गए शब्दों से मेल खाते हों. उदाहरण के लिए, अगर आपके उपयोगकर्ता किसी फ़िल्म के टाइटल के लिए, "टाइटल" के बजाय "नाम" शब्द का इस्तेमाल करना पसंद करते हैं, तो ऑपरेटर का नाम "नाम" पर सेट किया जाना चाहिए.
एक ही ऑपरेटर के नाम का इस्तेमाल, कई प्रॉपर्टी के लिए तब तक किया जा सकता है, जब तक सभी प्रॉपर्टी एक ही टाइप की हों. क्वेरी के दौरान, शेयर किए गए ऑपरेटर के नाम का इस्तेमाल करने पर, उस ऑपरेटर के नाम का इस्तेमाल करने वाली सभी प्रॉपर्टी वापस लाई जाती हैं. उदाहरण के लिए,
मान लें कि फ़िल्म ऑब्जेक्ट में plotSummary और plotSynopsis प्रॉपर्टी थीं और इनमें से हर प्रॉपर्टी में plot की operatorName वैल्यू थी. जब तक ये दोनों प्रॉपर्टी टेक्स्ट (textPropertyOptions) हैं, तब तक plot सर्च ऑपरेटर का इस्तेमाल करके की गई एक क्वेरी, दोनों को वापस लाती है.
operatorName के अलावा, क्रम में लगाई जा सकने वाली प्रॉपर्टी में operatorOptions में lessThanOperatorName और greaterThanOperatorName फ़ील्ड हो सकते हैं.
उपयोगकर्ता इन विकल्पों का इस्तेमाल करके, सबमिट की गई वैल्यू की तुलना के आधार पर क्वेरी बना सकते हैं.
आखिर में, textOperatorOptions में exactMatchWithOperator फ़ील्ड है, जो operatorOptions में है. अगर आपने exactMatchWithOperator को true पर सेट किया है, तो क्वेरी स्ट्रिंग को पूरी प्रॉपर्टी वैल्यू से मैच करना चाहिए, न कि सिर्फ़ टेक्स्ट में मौजूद होना चाहिए.
ऑपरेटर खोजों और फ़ेसेट मैच में, टेक्स्ट वैल्यू को एक एटमिक वैल्यू माना जाता है.
उदाहरण के लिए, शैली की प्रॉपर्टी के साथ किताब या फ़िल्म ऑब्जेक्ट को इंडेक्स करें.
शैलियों में "साइंस-फ़िक्शन", "साइंस", और "फ़िक्शन" शामिल हो सकते हैं. exactMatchWithOperator को false पर सेट करने या हटाने पर, किसी शैली को खोजने या "विज्ञान" या "फ़िक्शन" फ़ेसेट में से किसी एक को चुनने पर, "साइंस-फ़िक्शन" के लिए भी नतीजे मिलेंगे. ऐसा इसलिए होता है, क्योंकि टेक्स्ट को टोकन में बदल दिया जाता है और "साइंस" और "फ़िक्शन" टोकन, "साइंस-फ़िक्शन" में मौजूद होते हैं.
जब exactMatchWithOperator की वैल्यू true होती है, तो टेक्स्ट को एक टोकन माना जाता है. इसलिए, "Science" और "Fiction", दोनों ही "Science-Fiction" से मैच नहीं करते.
(ज़रूरी नहीं) displayOptions सेक्शन जोड़ना
किसी भी propertyDefinition सेक्शन के आखिर में, वैकल्पिक displayOptions सेक्शन होता है. इस सेक्शन में एक displayLabel स्ट्रिंग है.
displayLabel, प्रॉपर्टी के लिए सुझाया गया, उपयोगकर्ता के हिसाब से बना टेक्स्ट लेबल है. अगर प्रॉपर्टी को ObjectDisplayOptions का इस्तेमाल करके डिसप्ले के लिए कॉन्फ़िगर किया गया है, तो यह लेबल प्रॉपर्टी के सामने दिखता है. अगर प्रॉपर्टी को डिसप्ले के लिए कॉन्फ़िगर किया गया है और displayLabel की वैल्यू तय नहीं की गई है, तो सिर्फ़ प्रॉपर्टी की वैल्यू दिखती है.
नीचे दिया गया स्निपेट, movieTitle प्रॉपर्टी को दिखाता है. इसमें displayLabel को 'टाइटल' पर सेट किया गया है.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
सैंपल स्कीमा में movie ऑब्जेक्ट की सभी प्रॉपर्टी के लिए displayLabel वैल्यू यहां दी गई हैं:
| प्रॉपर्टी | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(ज़रूरी नहीं) suggestionFilteringOperators[] सेक्शन जोड़ना
किसी भी propertyDefinition सेक्शन के आखिर में, वैकल्पिक suggestionFilteringOperators[] सेक्शन होता है. अपने-आप पूरा होने वाले सुझावों को फ़िल्टर करने के लिए इस्तेमाल की जाने वाली प्रॉपर्टी तय करने के लिए, इस सेक्शन का इस्तेमाल करें. उदाहरण के लिए, उपयोगकर्ता की पसंदीदा फ़िल्म शैली के आधार पर सुझावों को फ़िल्टर करने के लिए, genre का ऑपरेटर तय किया जा सकता है. इसके बाद, जब उपयोगकर्ता अपनी खोज क्वेरी टाइप करता है, तो अपने-आप पूरी होने वाले सुझावों के हिस्से के तौर पर, सिर्फ़ उनकी पसंदीदा शैली से मैच होने वाली फ़िल्में दिखती हैं.
अपना स्कीमा रजिस्टर करना
Cloud Search की क्वेरी से स्ट्रक्चर्ड डेटा पाने के लिए, आपको Cloud Search के स्कीमा की सेवा के साथ अपना स्कीमा रजिस्टर करना होगा. स्कीमा को रजिस्टर करने के लिए, डेटा सोर्स को शुरू करना चरण के दौरान मिले डेटा सोर्स आईडी की ज़रूरत होती है.
डेटा सोर्स आईडी का इस्तेमाल करके, अपने स्कीमा को रजिस्टर करने के लिए, UpdateSchema अनुरोध करें.
UpdateSchema के रेफ़रंस पेज पर बताए गए तरीके के मुताबिक, अपने स्कीमा को रजिस्टर करने के लिए, यहां दिया गया एचटीटीपी अनुरोध करें:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
आपके अनुरोध के मुख्य हिस्से में यह जानकारी शामिल होनी चाहिए:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
अपने स्कीमा को रजिस्टर किए बिना, उसकी पुष्टि करने के लिए validateOnly विकल्प का इस्तेमाल करें.
अपने डेटा को इंडेक्स करना
स्कीमा रजिस्टर होने के बाद, Index कॉल का इस्तेमाल करके डेटा सोर्स को पॉप्युलेट करें. आम तौर पर, इंडेक्स करने की प्रोसेस आपके कॉन्टेंट कनेक्टर में होती है.
मूवी स्कीमा का इस्तेमाल करके, किसी एक मूवी के लिए REST API का इंडेक्स करने का अनुरोध ऐसा दिखेगा:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
ध्यान दें कि objectType फ़ील्ड में movie की वैल्यू, स्कीमा में ऑब्जेक्ट की परिभाषा के नाम से कैसे मेल खाती है. इन दोनों वैल्यू को मैच करके, Cloud Search को पता चलता है कि इंडेक्स करने के दौरान किस स्कीमा ऑब्जेक्ट का इस्तेमाल करना है.
यह भी ध्यान दें कि schema प्रॉपर्टी releaseDate को इंडेक्स करने के लिए, year, month, और day की उन सब-प्रॉपर्टी का इस्तेमाल कैसे किया जाता है जिन्हें यह इनहेरिट करती है. ऐसा इसलिए होता है, क्योंकि इसे datePropertyOptions का इस्तेमाल करके date डेटा टाइप के तौर पर परिभाषित किया जाता है.
हालांकि, स्कीमा में year, month, और day की जानकारी नहीं दी गई है.इसलिए, इनमें से किसी एक प्रॉपर्टी के लिए क्वेरी नहीं की जा सकती. उदाहरण के लिए, year) को अलग-अलग सेट किया जा सकता है.
साथ ही, ध्यान दें कि वैल्यू की सूची का इस्तेमाल करके, दोहराई जा सकने वाली प्रॉपर्टी actorName को कैसे इंडेक्स किया जाता है.
इंडेक्स करने से जुड़ी संभावित समस्याओं की पहचान करना
स्कीमा और इंडेक्स करने से जुड़ी दो सबसे सामान्य समस्याएं ये हैं:
इंडेक्स करने के आपके अनुरोध में, स्कीमा ऑब्जेक्ट या प्रॉपर्टी का ऐसा नाम है जिसे स्कीमा सेवा के साथ रजिस्टर नहीं किया गया था. इस समस्या की वजह से, प्रॉपर्टी या ऑब्जेक्ट को अनदेखा कर दिया जाता है.
इंडेक्स करने के आपके अनुरोध में, प्रॉपर्टी की टाइप वैल्यू, स्कीमा में रजिस्टर की गई टाइप वैल्यू से अलग है. इस समस्या की वजह से, इंडेक्स करने के समय Cloud Search गड़बड़ी का मैसेज दिखाता है.
अलग-अलग तरह की क्वेरी की मदद से अपने स्कीमा की जांच करना
बड़े प्रोडक्शन डेटा रिपॉज़िटरी के लिए अपना स्कीमा रजिस्टर करने से पहले, छोटे टेस्ट डेटा रिपॉज़िटरी की मदद से जांच करें. छोटे डेटा स्टोर से टेस्ट करने पर, स्कीमा में तेज़ी से बदलाव किए जा सकते हैं. साथ ही, बड़े इंडेक्स या मौजूदा प्रोडक्शन इंडेक्स पर असर डाले बिना, इंडेक्स किया गया डेटा मिटाया जा सकता है. टेस्ट डेटा रिपॉज़िटरी के लिए, ऐसा एसीएल बनाएं जो सिर्फ़ टेस्ट उपयोगकर्ता को अनुमति देता हो. इससे अन्य उपयोगकर्ताओं को Search के नतीजों में यह डेटा नहीं दिखेगा.
खोज क्वेरी की पुष्टि करने के लिए खोज इंटरफ़ेस बनाने के लिए, खोज इंटरफ़ेस देखें
इस सेक्शन में, कई अलग-अलग उदाहरण क्वेरी शामिल हैं. इनका इस्तेमाल, मूवी स्कीमा की जांच करने के लिए किया जा सकता है.
सामान्य क्वेरी की मदद से जांच करना
सामान्य क्वेरी, डेटा सोर्स में मौजूद उन सभी आइटम को दिखाती है जिनमें कोई खास स्ट्रिंग मौजूद होती है. खोज इंटरफ़ेस का इस्तेमाल करके, किसी मूवी के डेटा सोर्स के लिए सामान्य क्वेरी चलाई जा सकती है. इसके लिए, "titanic" शब्द टाइप करें और Return दबाएं. खोज के नतीजों में, "titanic" शब्द वाली सभी फ़िल्में दिखनी चाहिए.
किसी ऑपरेटर की मदद से जांच करना
क्वेरी में ऑपरेटर जोड़ने से, नतीजे सिर्फ़ उन आइटम तक सीमित हो जाते हैं जो ऑपरेटर की वैल्यू से मैच करते हैं. उदाहरण के लिए, किसी खास कलाकार की सभी फ़िल्में ढूंढने के लिए, actor ऑपरेटर का इस्तेमाल किया जा सकता है. खोज इंटरफ़ेस का इस्तेमाल करके, ऑपरेटर क्वेरी को आसानी से चलाया जा सकता है. इसके लिए, ऑपरेटर=वैल्यू जोड़े को टाइप करें, जैसे कि "actor:Zane" और Return दबाएं. खोज के नतीजों में, उन सभी फ़िल्मों को दिखाया जाना चाहिए जिनमें ज़ेन ने अभिनय किया है.
अपने स्कीमा को ट्यून करना
स्कीमा और डेटा के इस्तेमाल के बाद, इस बात पर नज़र रखें कि आपके उपयोगकर्ताओं के लिए कौनसी चीज़ें काम कर रही हैं और कौनसी नहीं. आपको इन स्थितियों में अपने स्कीमा में बदलाव करने चाहिए:
- किसी ऐसे फ़ील्ड को इंडेक्स करना जिसे पहले इंडेक्स नहीं किया गया था. उदाहरण के लिए, हो सकता है कि आपके उपयोगकर्ता, निर्देशक के नाम के आधार पर बार-बार फ़िल्में खोजें. इसलिए, अपने स्कीमा में बदलाव करके, निर्देशक के नाम को ऑपरेटर के तौर पर इस्तेमाल किया जा सकता है.
- उपयोगकर्ताओं के सुझावों के आधार पर, खोज ऑपरेटर के नाम बदले जा रहे हैं. ऑपरेटर के नाम, उपयोगकर्ता के लिए आसान होने चाहिए. अगर आपके उपयोगकर्ताओं को हमेशा ऑपरेटर का गलत नाम "याद" रहता है, तो उसे बदला जा सकता है.
स्कीमा में बदलाव करने के बाद, फिर से इंडेक्स करना
अपने स्कीमा में इनमें से किसी भी वैल्यू को बदलने पर, आपको अपने डेटा को फिर से इंडेक्स करने की ज़रूरत नहीं पड़ती. इसके लिए, आपको बस एक नया UpdateSchema अनुरोध सबमिट करना होगा. इसके बाद, आपका इंडेक्स काम करता रहेगा:
- ऑपरेटर के नाम.
- पूर्णांक की कम से कम और ज़्यादा से ज़्यादा वैल्यू.
- पूर्णांक और एनम के क्रम में रैंकिंग.
- डेटा अपडेट होने की फ़्रीक्वेंसी के विकल्प.
- डिसप्ले के विकल्प
इन बदलावों के बाद, पहले से इंडेक्स किया गया डेटा, पहले से रजिस्टर किए गए स्कीमा के मुताबिक काम करता रहेगा. हालांकि, अपडेट किए गए स्कीमा के आधार पर बदलाव देखने के लिए, आपको मौजूदा एंट्री को फिर से इंडेक्स करना होगा. ऐसा तब करना होगा, जब स्कीमा में ये बदलाव हों:
- नई प्रॉपर्टी या ऑब्जेक्ट जोड़ना या हटाना
isReturnable,isFacetableयाisSortableकोfalseसे बदलकरtrueकरना.
अगर आपके पास इस्तेमाल का कोई उदाहरण और ज़रूरत है, तो आपको isFacetable या isSortable को true सिर्फ़ पर सेट करना चाहिए.
आखिर में, किसी प्रॉपर्टी को isSuggestable के तौर पर मार्क करके अपना स्कीमा अपडेट करने पर, आपको अपने डेटा को फिर से इंडेक्स करना होगा. इससे उस प्रॉपर्टी के लिए, अपने-आप पूरा होने की सुविधा का इस्तेमाल करने में देरी होती है.
प्रॉपर्टी में ऐसे बदलाव करना जिनकी अनुमति नहीं है
स्कीमा में कुछ बदलाव करने की अनुमति नहीं है. भले ही, आपने अपना डेटा फिर से इंडेक्स कर लिया हो, क्योंकि इन बदलावों से इंडेक्स खराब हो जाएगा या खोज के खराब या अलग-अलग नतीजे मिलेंगे. इनमें ये बदलाव शामिल हैं:
- प्रॉपर्टी का डेटा टाइप.
- प्रॉपर्टी का नाम.
exactMatchWithOperatorसेटिंग.retrievalImportanceसेटिंग.
हालांकि, इस सीमा को बढ़ाने का एक तरीका है.
स्कीमा में कोई जटिल बदलाव करना
Cloud Search, UpdateSchema के अनुरोधों में कुछ तरह के बदलावों को रोकता है. ऐसा इसलिए किया जाता है, ताकि खोज के खराब नतीजे न मिलें या खोज का इंडेक्स न टूटे. ऐसा तब किया जाता है, जब डेटा स्टोर को इंडेक्स कर लिया गया हो. उदाहरण के लिए, किसी प्रॉपर्टी का डेटा टाइप या नाम सेट होने के बाद, उसे बदला नहीं जा सकता. ये बदलाव, UpdateSchema के अनुरोध से नहीं किए जा सकते. भले ही, आपने अपना डेटा फिर से इंडेक्स किया हो.
अगर आपको अपने स्कीमा में ऐसा बदलाव करना है जो आम तौर पर अनुमति नहीं है, तो आम तौर पर अनुमति है वाले कई बदलाव किए जा सकते हैं. इनसे वही असर पड़ता है जो आपको अनुमति नहीं है वाले बदलाव से पड़ना था. आम तौर पर, इसमें पहले इंडेक्स की गई प्रॉपर्टी को किसी पुरानी ऑब्जेक्ट डेफ़िनिशन से नई ऑब्जेक्ट डेफ़िनिशन पर माइग्रेट करना होता है. इसके बाद, इंडेक्स करने का ऐसा अनुरोध भेजना होता है जिसमें सिर्फ़ नई प्रॉपर्टी का इस्तेमाल किया जाता है.
यहां किसी प्रॉपर्टी का डेटा टाइप या नाम बदलने का तरीका बताया गया है:
- अपने स्कीमा में ऑब्जेक्ट की परिभाषा में नई प्रॉपर्टी जोड़ें. उस प्रॉपर्टी के नाम से अलग नाम का इस्तेमाल करें जिसे बदलना है.
- नई परिभाषा के साथ, UpdateSchema अनुरोध करें. अनुरोध में पूरा स्कीमा भेजना न भूलें. इसमें नई और पुरानी, दोनों प्रॉपर्टी शामिल होनी चाहिए.
डेटा रिपॉज़िटरी से इंडेक्स को बैकफ़िल करें. इंडेक्स को बैकफ़िल करने के लिए, नई प्रॉपर्टी का इस्तेमाल करके इंडेक्स करने के सभी अनुरोध भेजें. हालांकि, पुरानी प्रॉपर्टी का इस्तेमाल नहीं करें, क्योंकि इससे क्वेरी मैच की गिनती दो बार हो जाएगी.
- इंडेक्स करने के दौरान, नई प्रॉपर्टी की जांच करें और डिफ़ॉल्ट रूप से पुरानी प्रॉपर्टी का इस्तेमाल करें, ताकि कोई गड़बड़ी न हो.
- बैकफ़िल पूरा होने के बाद, पुष्टि करने के लिए टेस्ट क्वेरी चलाएं.
पुरानी प्रॉपर्टी मिटाएं. पुरानी प्रॉपर्टी के नाम के बिना, UpdateSchema का एक और अनुरोध करें. साथ ही, आने वाले समय में इंडेक्स करने के अनुरोधों में, पुरानी प्रॉपर्टी के नाम का इस्तेमाल बंद करें.
पुरानी प्रॉपर्टी के इस्तेमाल को नई प्रॉपर्टी में माइग्रेट करें. उदाहरण के लिए, अगर आपने प्रॉपर्टी का नाम क्रिएटर से बदलकर लेखक कर दिया है, तो आपको अपने क्वेरी कोड को अपडेट करना होगा, ताकि जहां पहले क्रिएटर का रेफ़रंस दिया गया था वहां लेखक का इस्तेमाल किया जा सके.
Cloud Search, मिटाई गई किसी भी प्रॉपर्टी या ऑब्जेक्ट का रिकॉर्ड 30 दिनों तक रखता है. ऐसा इसलिए किया जाता है, ताकि उसे फिर से इस्तेमाल न किया जा सके. इससे, इंडेक्स करने के दौरान अनचाहे नतीजे मिलने से बचा जा सकता है. आपको 30 दिनों के अंदर, मिटाए गए ऑब्जेक्ट या प्रॉपर्टी के सभी इस्तेमाल को माइग्रेट कर देना चाहिए. साथ ही, आने वाले समय में इंडेक्स करने के अनुरोधों से भी उन्हें हटा देना चाहिए. इससे यह पक्का होता है कि अगर बाद में उस प्रॉपर्टी या ऑब्जेक्ट को फिर से शामिल करने का फ़ैसला लिया जाता है, तो ऐसा इस तरह किया जा सकता है कि आपके इंडेक्स में कोई गड़बड़ी न हो.
फ़ाइल के साइज़ की सीमाओं के बारे में जानकारी
Cloud Search, स्ट्रक्चर्ड डेटा ऑब्जेक्ट और स्कीमा के साइज़ पर सीमाएं लगाता है. ये सीमाएं हैं:
- टॉप-लेवल ऑब्जेक्ट की संख्या ज़्यादा से ज़्यादा 10 हो सकती है.
- स्ट्रक्चर्ड डेटा की हैरारकी में ज़्यादा से ज़्यादा 10 लेवल हो सकते हैं.
- किसी ऑब्जेक्ट में फ़ील्ड की कुल संख्या 1,000 तक सीमित होती है. इसमें प्राइमिटिव फ़ील्ड की संख्या के साथ-साथ, नेस्ट किए गए हर ऑब्जेक्ट में फ़ील्ड की संख्या का योग शामिल होता है.
अगले चरण
यहां कुछ ऐसे तरीके दिए गए हैं जिनका इस्तेमाल करके, इस समस्या को हल किया जा सकता है:
अपने स्कीमा की जांच करने के लिए, सर्च इंटरफ़ेस बनाएं.
खोज क्वालिटी को बेहतर बनाने के लिए, अपने स्कीमा को ट्यून करें.
अपनी कंपनी में आम तौर पर इस्तेमाल होने वाले शब्दों के लिए, मिलते-जुलते शब्द तय करने के लिए,
_dictionaryEntryस्कीमा का फ़ायदा पाने का तरीका जानें._dictionaryEntryस्कीमा का इस्तेमाल करने के लिए, समानार्थी शब्द तय करना लेख पढ़ें.कनेक्टर बनाएं.