
Google Cloud Search 스키마는 데이터 색인 생성 및 쿼리에 사용할 객체, 속성, 옵션을 정의하는 JSON 구조입니다. 콘텐츠 커넥터는 저장소에서 데이터를 읽고 등록된 스키마를 기반으로 데이터를 구조화하고 색인을 생성합니다.
JSON 스키마 객체를 API에 제공한 다음 등록하여 스키마를 만들 수 있습니다. 데이터의 색인을 생성하려면 각 저장소의 스키마 객체를 등록해야 합니다.
이 문서는 스키마 생성의 기본 사항을 다룹니다. 스키마 미세 조정을 통한 검색 환경 개선에 관한 내용은 검색 품질 개선을 참조하세요.
스키마 만들기
다음은 Cloud Search 스키마 생성 단계 입니다.
을 참고하세요.예상되는 사용자 동작 식별
사용자가 수행하는 쿼리의 유형을 예상해 보면 스키마 생성 전략을 세우는 데 도움이 됩니다.
예를 들어 영화 데이터베이스에 대한 쿼리를 실행하는 경우 사용자가 '로버트 레드포드가 주연으로 출연한 모든 영화 보기'와 같은 쿼리를 수행할 것이라 예상할 수 있습니다. 따라서 스키마는 '특정 배우가 출연하는 모든 영화'를 기준으로 쿼리 결과를 지원해야 합니다.
사용자의 동작 패턴을 반영하여 스키마를 정의하려면 다음 태스크를 수행하는 것이 좋습니다.
- 다양한 사용자가 원하는 다양한 쿼리 평가
- 쿼리에서 사용할 수 있는 객체 식별. 객체는 관련 데이터의 논리적 집합입니다(예: 영화 데이터베이스의 영화).
- 객체를 구성하며 쿼리에서 사용될 수 있는 속성 및 값 식별. 속성은 색인을 생성할 수 있는 객체의 특성이며, 기본 값 또는 다른 객체를 포함할 수 있습니다. 예를 들어 영화 객체에는 영화의 제목 및 개봉일과 같은 속성이 기본 값으로 포함될 수 있습니다. 또한 영화 객체에는 이름이나 역할과 같은 자체 속성을 가진 배역과 같은 다른 객체가 포함될 수도 있습니다.
- 실제로 유효한 속성 값 파악. 값은 속성의 색인을 생성하는 데 사용되는 실제 데이터입니다. 예를 들어 데이터베이스에 '레이더스'라는 제목의 영화가 있을 수 있습니다.
- 사용자가 원하는 정렬 및 순위 옵션 파악. 예를 들어 사용자가 영화를 쿼리할 때 시간순으로 정렬하고 시청자층 평점에 따라 순위를 매기는 것을 원하지만 제목순으로 정렬하는 기능은 필요하지 않을 수 있습니다.
- (선택사항) 속성 중 하나가 사용자의 직무 역할이나 부서와 같이 검색이 실행될 수 있는 보다 구체적인 컨텍스트를 나타내는지 고려하여 컨텍스트를 기반으로 자동 완성 제안을 제공할 수 있습니다. 예를 들어 영화 데이터베이스를 검색하는 사용자는 특정 장르의 영화에만 관심이 있을 수 있습니다. 사용자는 검색 결과로 반환되기를 원하는 장르를 정의할 수 있으며, 이는 사용자 프로필의 일부일 수 있습니다. 그런 다음 사용자가 영화 검색어를 입력하기 시작하면 '액션 영화'와 같이 선호하는 장르의 영화만 자동 완성 추천의 일부로 추천됩니다.
- 검색에 사용할 수 있는 이러한 객체, 속성, 예시 값의 목록 만들기. (이 목록을 사용하는 방법에 대한 자세한 내용은 연산자 옵션 정의 섹션을 참고하세요.)
데이터 소스 초기화
데이터 소스란 색인이 생성되어 Google Cloud에 저장된 저장소의 데이터를 나타냅니다. 데이터 소스를 초기화하는 방법은 서드 파티 데이터 소스 관리를 참고하세요.
사용자의 검색결과는 데이터 소스에서 반환됩니다. 사용자가 검색결과를 클릭하면 Cloud Search는 색인 생성 요청에 제공된 URL을 사용하여 사용자에게 실제 항목을 안내합니다.
객체 정의
스키마에서 데이터의 기본 단위는 객체이며, 데이터의 논리적 구조인 스키마 객체'라고도 합니다. 영화 데이터베이스에서 데이터의 논리적 구조는 'movie'입니다. 또 다른 객체로 영화에 참여한 배우와 제작진을 아우르는 'person'이 있을 수 있습니다.
스키마의 각 객체에는 객체를 나타내는 일련의 속성 또는 특성이 있습니다(예: 영화 제목이나 재생 시간 또는 사람의 이름 및 생년월일). 객체의 속성에는 기본 값이나 다른 객체가 포함될 수 있습니다.
그림 1은 영화 및 사람 객체와 관련 속성을 보여줍니다.
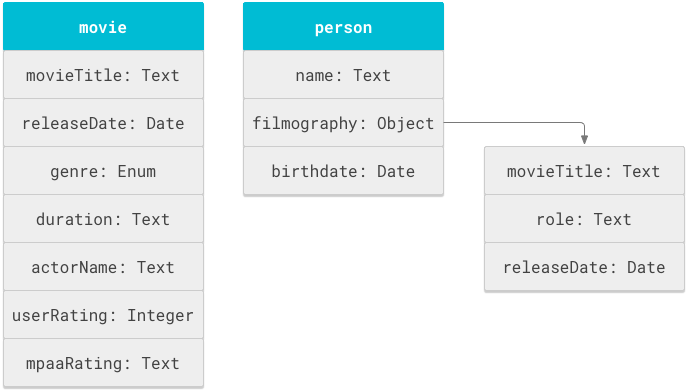
Cloud Search 스키마는 기본적으로 objectDefinitions 태그 내에 정의된 객체 정의 문의 목록입니다. 다음과 같은 스키마 스니펫은 movie 및 person 스키마 객체의 objectDefinitions 문을 보여줍니다.
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
스키마 객체를 정의할 때는 스키마의 다른 모든 객체에 걸쳐 고유한 객체의 name을 지정합니다. 일반적으로는 객체를 설명하는 name 값을 사용합니다(예: 영화 객체의 경우 movie). 스키마 서비스는 name 필드를 색인 생성 가능한 객체의 키 식별자로 사용합니다. name 필드에 대한 자세한 내용은 객체 정의를 참고하세요.
객체 속성 정의
ObjectDefinition 참조에 지정된 대로 객체 이름 뒤에는 options 집합과 propertyDefinitions 목록이 옵니다.
options는 freshnessOptions 및 displayOptions로 구성될 수 있습니다.
freshnessOptions는 항목의 최신 상태에 따라 검색 순위를 조정하는 데 사용됩니다. displayOptions는 객체의 검색 결과에 특정 라벨 및 속성이 표시되는지 여부를 정의하는 데 사용됩니다.
propertyDefinitions 섹션에는 객체의 속성(예: 영화 제목 및 개봉일)을 정의합니다.
다음 스니펫은 movieTitle 및 releaseDate라는 두 속성이 있는 movie 객체를 보여줍니다.
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
PropertyDefinition은 다음과 같은 항목으로 구성됩니다.
name문자열- 유형에 구애받지 않는 옵션의 목록(예: 이전 스니펫의
isReturnable) - 유형 및 유형 관련 옵션(예: 이전 스니펫의
textPropertyOptions및retrievalImportance) - 속성이 검색 연산자로 사용되는 방법을 설명하는
operatorOptions - 하나 이상의
displayOptions(예: 이전 스니펫의displayLabel)
속성의 name은 포함 객체 내에서 고유해야 하지만 다른 객체 및 하위 객체에서 동일한 이름을 사용할 수 있습니다.
그림 1에서 영화 제목과 개봉일은 movie 객체에서 한 번, person 객체의 filmography 하위 객체에서 다시 한 번, 총 두 번 정의되었습니다. 이 스키마는 다음과 같은 2가지 검색 동작을 지원할 수 있도록 movieTitle 필드를 재사용합니다.
- 사용자가 영화 제목을 검색할 때 영화 결과 표시
- 사용자가 특정 배우가 출연한 영화 제목을 검색할 때 사람 결과 표시
마찬가지로, 스키마는 두 movieTitle 필드에 동일한 의미가 있는 releaseDate 필드를 재사용합니다.
자체 스키마 개발 시에는 스키마에서 두 번 이상 선언하고자 하는 데이터가 포함되어 있는 관련 필드가 저장소에서 어떻게 포함될지를 생각해야 합니다.
유형에 구애받지 않는 옵션 추가
PropertyDefinition은 데이터 유형에 관계없이 모든 속성에 일반적인 검색 기능 옵션을 나열합니다.
isReturnable- 해당 속성이 Query API를 통해 검색 결과에 반환되어야 하는 데이터를 식별하는지를 나타냅니다. 모든 영화 속성 예시는 반품 가능합니다. 반환이 불가능한 속성은 사용자에게 반환되지 않고 결과를 검색하거나 순위를 매기는 데 사용될 수 있습니다.isRepeatable- 속성에 여러 값이 허용되는지 여부를 나타냅니다. 예를 들어 영화의 개봉일은 하나뿐이지만 배우는 여러 명 있을 수 있습니다.isSortable- 해당 속성이 정렬 기준으로 사용될 수 있음을 나타냅니다. 반복 가능한 속성의 경우 이 옵션이 true가 될 수 없습니다. 예를 들어 개봉일이나 시청자층 평점을 기준으로 영화 결과를 정렬할 수 있습니다.isFacetable- 패싯을 생성하는 데 속성을 사용할 수 있는지를 나타냅니다. 패싯은 사용자가 초기 결과를 확인한 다음 기준 또는 패싯을 추가하여 검색결과를 구체화하는 데 사용됩니다. 유형이 객체인 속성의 경우 이 옵션이 true가 될 수 없으며, 이 옵션을 설정하려면isReturnable이 true여야 합니다. 마지막으로 이 옵션은 열거형, 부울, 텍스트 속성에만 지원됩니다. 예를 들어 샘플 스키마에서는genre,actorName,userRating,mpaaRating을 패싯으로 만들어 검색 결과를 대화식으로 구체화하는 데 사용할 수 있습니다.isWildcardSearchable는 사용자가 이 속성에 대해 와일드 카드 검색을 실행할 수 있음을 나타냅니다. 이 옵션은 텍스트 속성에만 사용할 수 있습니다. 텍스트 필드에서 와일드 카드 검색이 작동하는 방식은 exactMatchWithOperator 필드에 설정된 값에 따라 다릅니다.exactMatchWithOperator이true로 설정된 경우 텍스트 값이 하나의 원자 값으로 토큰화되고 이에 대해 와일드 카드 검색이 실행됩니다. 예를 들어 텍스트 값이science-fiction이면 와일드 카드 쿼리science-*가 일치합니다.exactMatchWithOperator가false로 설정된 경우 텍스트 값이 토큰화되고 각 토큰에 대해 와일드 카드 검색이 실행됩니다. 예를 들어 텍스트 값이 'science-fiction'인 경우 와일드 카드 쿼리sci*또는fi*는 항목과 일치하지만science-*는 일치하지 않습니다.
이러한 일반 검색 기능 매개변수는 모두 불리언 값입니다. 모두 기본값이 false이고 사용하려면 true로 설정해야 합니다.
다음 표는 movie 객체의 모든 속성에 대해 true로 설정된 불리언 매개변수를 보여줍니다.
| 속성 | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
true | true | |||
releaseDate |
true | true | |||
genre |
true | true | true | ||
duration |
true | ||||
actorName |
true | true | true | true | |
userRating |
true | true | |||
mpaaRating |
true | true |
genre와 actorName은 둘 다 isRepeatable이 true로 설정되어 있습니다. 영화는 둘 이상의 장르에 속할 수 있고, 배우가 두 명 이상 출연하는 것이 일반적이기 때문입니다. 그 자체가 반복될 수 있거나 반복이 가능한 하위 객체에 포함된 속성은 정렬할 수 없습니다.
유형 정의
PropertyDefinition 참조 섹션에는 몇 가지 xxPropertyOptions가 나열되며, 여기서 xx는 boolean과 같은 특정 유형을 말합니다. 속성의 데이터 유형 설정을 위해서는 적절한 데이터 유형 객체를 정의해야 합니다. 속성의 데이터 유형 객체를 정의하면 해당 속성의 데이터 유형이 설정됩니다. 예를 들어 movieTitle 속성에 textPropertyOptions를 정의하면 영화 제목이 텍스트 유형이라는 의미입니다. 다음 스니펫은 데이터 유형을 설정하는 textPropertyOptions가 있는 movieTitle 속성을 보여줍니다.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
속성에는 연관된 데이터 유형이 하나만 존재할 수도 있습니다. 예를 들어 영화 스키마에서 releaseDate는 날짜 (예: 2016-01-13) 또는 문자열(예: January 13, 2016) 중 하나를 지정할 수 있지만 둘 다 지정할 수는 없습니다.
다음은 샘플 영화 스키마에서 속성의 데이터 유형을 지정하는 데 사용되는 데이터 유형 객체입니다.
| 속성 | 데이터 유형 객체 |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
속성 데이터 유형 선택은 예상 사용 사례에 따라 달라집니다.
이 영화 스키마의 상상 속 시나리오에서는 사용자가 시간순으로 결과를 정렬할 것으로 예상되므로 releaseDate는 날짜 객체입니다.
예를 들어 연도에 상관없이 12월 개봉과 1월 개봉을 비교하는 예상 사용 사례가 있다면 문자열 형식이 유용할 수 있습니다.
유형 관련 옵션 구성
PropertyDefinition 참조 섹션에는 각 유형의 옵션에 대한 링크가 있습니다. 대부분의 유형 관련 옵션은 선택적입니다(enumPropertyOptions의 possibleValues 목록 제외). 또한 orderedRanking 옵션을 사용하면 값의 상대적 순위를 매길 수 있습니다. 다음 스니펫은 데이터 유형을 설정하는 textPropertyOptions와 retrievalImportance 유형 관련 옵션이 지정된 movieTitle 속성을 보여줍니다.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
다음은 샘플 스키마에서 사용되는 추가적인 유형 관련 옵션입니다.
| 속성 | 유형 | 유형 관련 옵션 |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking, maximumValue |
mpaaRating |
textPropertyOptions |
연산자 옵션 정의
각 유형에는 유형 관련 옵션 외에 선택적 operatorOptions 집합이 있습니다. 이러한 옵션은 속성이 검색 연산자로 사용되는 방법을 설명합니다. 다음 스니펫은 데이터 유형을 설정하는 textPropertyOptions와 retrievalImportance 및 operatorOptions 유형 관련 옵션이 지정된 movieTitle 속성을 보여줍니다.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
모든 operatorOptions에는 operatorName가 있습니다(예: movieTitle의 title). 연산자 이름은 속성의 검색 연산자입니다. 검색 연산자는 사용자가 검색 범위를 좁힐 때 사용할 것으로 예상되는 실제 매개변수입니다. 예를 들어 제목으로 영화를 검색할 때 사용자는 title:movieName을 입력합니다. 여기서 movieName은 영화 이름입니다.
연산자 이름은 속성 이름과 동일할 필요가 없지만, 해당 조직의 사용자들 사이에 가장 널리 쓰이는 단어를 반영해서 연산자 이름을 설정해야 합니다. 예를 들어 사용자가 영화 제목을 가리키는 용어에 'title' 대신 'name'이라는 단어를 선호한다면 연산자 이름을 'name'으로 설정해야 합니다.
모두 동일한 유형으로 확인되는 여러 속성에는 동일한 연산자 이름을 사용할 수 있습니다. 쿼리 중에 공유 연산자 이름을 사용하면 해당 연산자 이름을 사용하는 모든 속성이 검색됩니다. 예를 들어 영화 객체에 plotSummary 및 plotSynopsis 속성이 있고, 이러한 각 속성에 plot의 operatorName이 있다고 가정해 보겠습니다. 이러한 두 속성이 텍스트 (textPropertyOptions)라면 plot 검색 연산자를 사용한 단일 쿼리에서 두 속성이 모두 검색됩니다.
정렬 가능한 속성에는 operatorName 외에도 operatorOptions에 lessThanOperatorName 및 greaterThanOperatorName 필드가 포함될 수 있습니다.
사용자는 이러한 옵션을 사용하여 제출된 값과 비교한 결과에 기반을 둔 쿼리를 만들 수 있습니다.
마지막으로 textOperatorOptions에는 operatorOptions에 exactMatchWithOperator 필드가 있습니다. exactMatchWithOperator를 true로 설정하면 쿼리 문자열이 텍스트에 포함되어 있을 뿐만 아니라 전체 속성 값과 일치해야 합니다.
텍스트 값은 연산자 검색 및 패싯 일치 항목에서 하나의 원자 값으로 처리됩니다.
예를 들어 장르 속성을 사용하여 도서 또는 영화 개체의 색인을 생성하는 경우를 가정해 보겠습니다.
장르에는 'Science-Fiction', 'Science', 'Fiction'이 포함될 수 있습니다. exactMatchWithOperator가 false로 설정되거나 생략된 경우 장르를 검색하거나 'Science' 또는 'Fiction' 측면을 선택하면 텍스트가 토큰화되고 'Science-Fiction'에 'Science' 및 'Fiction' 토큰이 있으므로 'Science-Fiction' 결과도 반환됩니다.
exactMatchWithOperator가 true인 경우 텍스트가 단일 토큰으로 취급되므로 'Science' 또는 'Fiction'이 'Science-Fiction'과 일치하지 않습니다.
(선택사항) displayOptions 섹션 추가
propertyDefinition 섹션의 끝 부분에는 선택적 displayOptions 섹션이 있습니다. 이 섹션에는 displayLabel 문자열이 하나 있습니다.
displayLabel은 속성에 권장되는 사용자 친화적인 텍스트 라벨입니다. ObjectDisplayOptions를 사용하여 속성을 표시하도록 구성하면 이 라벨이 속성 앞에 표시됩니다. 속성을 표시하도록 구성하고 displayLabel을 정의하지 않으면 속성 값만 표시됩니다.
다음 스니펫은 displayLabel이 'Title'로 설정된 movieTitle 속성을 보여줍니다.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
다음은 샘플 스키마에 있는 movie 객체의 모든 속성에 대한 displayLabel 값입니다.
| 속성 | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(선택사항) suggestionFilteringOperators[] 섹션 추가
propertyDefinition 섹션의 끝 부분에는 선택적 suggestionFilteringOperators[] 섹션이 있습니다. 이 섹션을 사용하여 자동 완성 추천을 필터링하는 데 사용되는 속성을 정의합니다. 예를 들어 사용자의 선호하는 영화 장르를 기반으로 추천을 필터링하도록 genre 연산자를 정의할 수 있습니다. 그런 다음 사용자가 검색어를 입력하면 선호하는 장르와 일치하는 영화만 자동 완성 추천의 일부로 표시됩니다.
스키마 등록
Cloud Search 쿼리에서 구조화된 데이터가 반환되도록 하려면 Cloud Search 스키마 서비스에 스키마를 등록해야 합니다. 스키마를 등록하려면 데이터 소스 초기화 단계에서 받은 데이터 소스 ID가 필요합니다.
이 데이터 소스 ID를 사용하여 UpdateSchema 요청을 실행하고 스키마를 등록합니다.
UpdateSchema 참조 페이지에 자세히 설명된 것처럼, 다음과 같은 HTTP 요청을 실행하여 스키마를 등록합니다.
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
요청 본문에는 다음 내용이 포함되어야 합니다.
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
스키마를 실제로 등록하지 않고 유효성을 테스트하려면 validateOnly 옵션을 사용합니다.
데이터 색인 생성
스키마가 등록되면 색인 호출을 사용하여 데이터 소스를 채웁니다. 색인 생성은 일반적으로 콘텐츠 커넥터 내에서 수행됩니다.
영화 스키마를 사용할 경우 단일 영화의 REST API 색인 생성 요청은 다음과 유사합니다.
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
objectType 필드의 movie 값이 스키마의 객체 정의 이름과 어떻게 일치하는지 확인하세요. Cloud Search는 이 두 값을 일치시켜서 색인 생성 시 사용할 스키마 객체를 파악합니다.
또한 스키마 속성 releaseDate의 색인은 datePropertyOptions를 사용하여 date 데이터 유형으로 정의되었기 때문에 year, month, day라는 하위 속성을 상속하는데, 이를 어떻게 사용하는지도 확인하세요.
하지만 year, month, day는 스키마에 정의되어 있지 않으므로 이러한 속성 중 하나 (예: year)를 개별적으로 설정할 수 있습니다.
또한 값 목록을 사용하여 반복 가능한 속성 actorName의 색인을 생성하는 방법도 확인하세요.
잠재적 색인 생성 문제 식별
스키마 및 색인 생성과 관련된 가장 일반적인 2가지 문제는 다음과 같습니다.
스키마 서비스에 등록되지 않은 스키마 객체 또는 속성 이름이 색인 생성 요청에 포함된 경우. 이 문제가 있으면 속성 또는 객체가 무시됩니다.
스키마에 등록된 유형과 다른 유형 값을 가진 속성이 색인 생성 요청에 있는 경우. 이 문제가 있으면 Cloud Search가 색인 생성 시 오류를 반환합니다.
여러 쿼리 유형을 사용하여 스키마 테스트
대규모 프로덕션 데이터 저장소에 스키마를 등록하기 전에 소규모 테스트 데이터 저장소로 테스트해 보세요. 소규모 테스트 저장소로 테스트하면 대규모 색인이나 기존 프로덕션 색인에 영향을 주지 않고 스키마를 빠르게 조정하고 색인이 생성된 데이터를 삭제할 수 있습니다. 테스트 데이터 저장소의 경우 다른 사용자가 검색 결과에서 이 데이터를 볼 수 없도록 테스트 사용자에게만 권한을 부여하는 ACL을 만듭니다.
검색어를 확인하기 위해 검색 인터페이스를 만들려면 검색 인터페이스를 참조하세요.
이 섹션에는 영화 스키마를 테스트하는 데 사용할 수 있는 여러 가지 예시 쿼리가 포함되어 있습니다.
일반 쿼리로 테스트
일반 쿼리는 특정 문자열을 포함하는 데이터 소스의 모든 항목을 반환합니다. 검색 인터페이스를 사용하여 'titanic'이라는 단어를 입력하고 Return 키를 눌러 영화 데이터 소스에 대한 일반 쿼리를 실행할 수 있습니다. 그러면 'titanic'이라는 단어가 포함된 모든 영화가 검색 결과에 반환됩니다.
연산자로 테스트
쿼리에 연산자를 추가하면 해당 연산자 값과 일치하는 항목으로 결과가 제한됩니다. 예를 들어 actor 연산자를 사용하여 특정 배우가 주연으로 출연한 모든 영화를 찾을 수 있습니다. 검색 인터페이스에서 'actor:Zane'과 같은 연산자=값 쌍을 입력하고 Return 키만 누르면 이 연산자 쿼리를 실행할 수 있습니다. 그러면 Zane이 출연한 모든 영화가 검색 결과에 반환됩니다.
스키마 미세 조정
스키마와 데이터가 사용되기 시작했다면 사용자에게 효과적인 것과 그렇지 않은 것을 계속 모니터링하세요. 다음과 같은 경우 스키마를 조정해야 합니다.
- 이전에 색인을 생성한 적이 없는 필드의 색인을 생성하는 경우. 예를 들어 사용자가 감독 이름을 기준으로 영화를 반복해서 검색할 수 있으므로 감독 이름을 연산자로 사용하도록 스키마를 조정할 수 있습니다.
- 사용자 의견에 따라 검색 연산자 이름을 변경하는 경우. 연산자 이름은 사용자 친화적이어야 합니다. 사용자가 잘못된 연산자 이름을 계속 '기억'하는 경우 연산자 이름을 변경하는 것이 좋습니다.
스키마 변경 후 색인 재생성
스키마에서 다음 값을 변경하는 경우에도 데이터의 색인을 재생성할 필요가 없습니다. 새로운 UpdateSchema 요청을 제출하기만 하면 색인이 계속 작동합니다.
- 연산자 이름
- 정수 최솟값 및 최댓값
- 정수 및 열거형 순위
- 최신 상태 옵션
- 표시 옵션
다음과 같은 변경의 경우 이전에 등록된 스키마에 따라 이전에 색인이 생성된 데이터가 계속 작동합니다. 그러나 다음과 같은 변경사항이 있는 경우 업데이트된 스키마에 따른 변경사항을 보려면 기존 항목의 색인을 다시 만들어야 합니다.
- 새 속성이나 객체 추가 또는 제거
isReturnable,isFacetable또는isSortable를false에서true로 변경합니다.
분명한 사용 사례와 요구 사항이 있는 경우에만 isFacetable 또는 isSortable을 true로 설정해야 합니다.
마지막으로 속성을 isSuggestable로 표시하여 스키마를 업데이트할 때는 데이터의 색인을 다시 생성해야 하므로 해당 속성에 자동 완성을 사용하는 데 지연이 발생합니다.
허용되지 않는 속성 변경
일부 스키마 변경사항은 색인을 손상시키거나, 부정확하거나 일관성 없는 검색 결과를 생성하므로 데이터의 색인을 재생성하더라도 허용되지 않습니다. 여기에는 다음에 대한 변경사항이 포함됩니다.
- 속성 데이터 유형
- 속성 이름
exactMatchWithOperator설정retrievalImportance설정
그러나 이러한 한계를 극복하는 방법이 있습니다.
복잡한 스키마 변경 수행
Cloud Search는 부정확한 검색 결과 또는 손상된 검색 색인을 생성하는 변경을 방지하기 위해 저장소의 색인이 생성된 후 UpdateSchema 요청에서 특정 변경 유형을 차단합니다. 예를 들어 속성의 데이터 유형 또는 이름이 설정된 후에는 변경할 수 없습니다. 단순히 UpdateSchema 요청을 했다고 해서 이러한 변경사항이 구현될 수는 없습니다(데이터의 색인을 다시 생성하더라도 불가능).
스키마에 달리 허용되지 않는 변경을 수행해야 하는 상황에서 동일한 효과를 얻을 수 있는 일련의 허용된 변경을 수행할 수 있는 경우가 많습니다. 일반적으로 이를 위해서는 먼저 이전 객체 정의에서 색인이 생성된 속성을 최신 객체 정의로 이전한 후 최신 속성만 사용하는 색인 생성 요청을 보냅니다.
다음은 속성의 데이터 유형 또는 이름을 변경하는 방법을 보여주는 단계입니다.
- 스키마의 객체 정의에 새 속성을 추가합니다. 변경하려는 속성과 다른 이름을 사용합니다.
- 새 정의를 사용하여 UpdateSchema 요청을 실행합니다. 요청에 새 속성과 이전 속성을 모두 포함한 전체 스키마를 보내는 것을 잊지 마세요.
데이터 저장소에서 색인을 백필합니다. 색인을 백필하려면 이전 속성이 아닌 새 속성을 사용하여 모든 색인 생성 요청을 보내세요. 이전 속성을 사용하면 쿼리 일치 항목이 이중으로 계수되기 때문입니다.
- 색인 백필 중에는 새 속성을 확인하고 이전 속성으로 기본 설정하여 일관성 없는 동작을 방지합니다.
- 백필이 완료되면 테스트 쿼리를 실행하여 확인합니다.
이전 속성을 삭제합니다. 이전 속성 이름이 없는 또 다른 UpdateSchema 요청을 실행하고 향후 색인 생성 요청에서 이전 속성 이름의 사용을 중단합니다.
이전 속성의 사용법을 새 속성으로 이전합니다. 예를 들어 속성 이름을 제작자에서 저자로 변경하는 경우 쿼리 코드를 업데이트 해야만 이전에 제작자가 참조되었던 위치에서 새로 변경된 저자가 참조될 수 있습니다.
Cloud Search는 삭제된 속성이나 객체가 재사용되면서 예기치 않은 색인 생성 결과가 발생하지 않도록 이러한 속성이나 객체에 대한 기록을 30일 동안 보관합니다. 30일 동안 삭제된 객체나 속성을 향후 색인 요청에서 제외하는 것은 물론 이러한 객체나 속성의 모든 사용법을 이전해야 합니다. 그러면 나중에 해당 속성이나 객체를 다시 시작하기로 결정한 경우 색인의 정확성을 유지할 수 있습니다.
크기 제한 파악
Cloud Search는 구조화된 데이터 객체 및 스키마 크기에 제한을 둡니다. 이러한 제한은 다음과 같습니다.
- 최상위 객체의 최대 수는 10개입니다.
- 구조화된 데이터 계층 구조의 최대 깊이는 10레벨입니다.
- 객체의 총 필드 수는 1,000개로 제한되며, 여기에는 기본 필드 수와 각 중첩 개체의 필드 수 합계가 포함됩니다.
다음 단계
다음과 같은 몇 가지 단계를 진행할 수 있습니다.
스키마를 테스트할 검색 인터페이스를 만듭니다.
스키마를 조정하여 검색 품질을 개선합니다.
_dictionaryEntry스키마를 활용하여 회사에서 자주 사용되는 용어의 동의어를 정의하는 방법을 알아봅니다._dictionaryEntry스키마를 사용하려면 동의어 정의를 참고하세요.커넥터를 만듭니다.