
Pakiet Connector SDK i interfejs Cloud Search API umożliwiają tworzenie kolejek indeksowania Cloud Search, które służą do wykonywania tych zadań:
Zachowanie stanu dokumentu (stanu, wartości haszowania itp.), który może być używany do synchronizowania indeksu z repozytorium.
Utrzymywanie listy elementów do zindeksowania, które zostały odkryte podczas procesu przeszukiwania.
ustalać priorytety elementów w kolejkach na podstawie ich stanu;
Przechowywanie dodatkowych informacji o stanie w celu sprawnej integracji, takich jak punkty kontrolne czy token zmiany.
Kolejka to etykieta przypisana do zindeksowanego elementu, np. „default” dla domyślnej kolejki lub „B” dla kolejki B.
Stan i priorytet
Priorytet dokumentu w kolejce zależy od jego kodu ItemStatus. Oto możliwe kody ItemStatus
uporządkowane według priorytetu (od najwyższego do najniższego):
ERROR– podczas indeksowania elementu wystąpił błąd asynchroniczny i należy go ponownie zindeksować.MODIFIED– element, który został wcześniej zindeksowany i został zmodyfikowany w repozytorium po ostatnim zindeksowaniu.NEW_ITEM– element, który nie został zindeksowany.ACCEPTED– dokument, który został wcześniej zindeksowany i nie zmienił się w repozytorium od czasu ostatniego zindeksowania.
Gdy 2 elementy w kolejce mają ten sam stan, wyższy priorytet ma ten, który znajduje się w kolejce najdłużej.
Omówienie korzystania z kolejek indeksowania do indeksowania nowego lub zmienionego elementu
Rysunek 1 przedstawia etapy indeksowania nowego lub zmienionego elementu za pomocą kolejki indeksowania. Te kroki pokazują wywołania interfejsu API REST. Odpowiednie wywołania pakietu SDK znajdziesz w artykule Operacje kolejki (pakiet SDK Connectora).
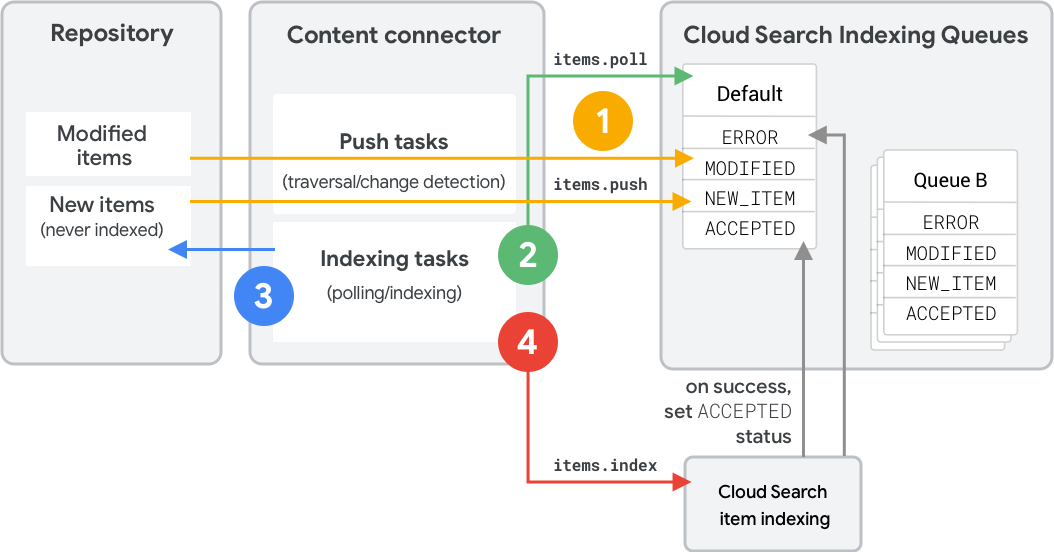
Pośrednik treści używa funkcji
items.push, aby przesyłać elementy (metadane i hasz) do kolejki indeksowania w celu ustalenia ich stanu (MODIFIED,NEW_ITEM,DELETED). W szczególności:- Podczas przesyłania danych usługa łączy się z usługą docelową, aby przesłać dane.
typecontentHash - Jeśli w oprogramowaniu sprzęgającym nie ma parametru
type, Cloud Search automatycznie używa parametrucontentHashdo określania stanu elementu. - Jeśli produkt jest nieznany, jego stan ma wartość
NEW_ITEM. - Jeśli element istnieje i wartości haszowania są zgodne, stan pozostaje taki sam (
ACCEPTED). - Jeśli element istnieje, ale łańcuchy haszowe się różnią, stan zmienia się na
MODIFIED.
Więcej informacji o tym, jak ustalany jest stan elementu, znajdziesz w przykładowym kodzie przeszukiwania repozytoriów GitHub w samouctniku wprowadzającym w Cloud Search.
Zwykle przesyłanie danych jest powiązane z procesami przeszukiwania treści lub wykrywania zmian w łączniku.
- Podczas przesyłania danych usługa łączy się z usługą docelową, aby przesłać dane.
Połączenie treści używa interfejsu
items.polldo odczytywania kolejki w celu określenia elementów do zindeksowania. Cloud Search informuje złącze, które elementy najbardziej potrzebują indeksowania. Są one posortowane najpierw według kodu stanu, a potem według czasu oczekiwania w kolejce.Oprogramowanie sprzęgające pobiera te elementy z repozytorium i tworzy indeks żądań interfejsu API.
Łącznik używa do indeksowania elementów pliku
items.index. Element przechodzi w stanACCEPTEDdopiero po pomyślnym przetworzeniu go przez Cloud Search.
Oprogramowanie sprzęgające może też usunąć element, jeśli nie istnieje już w repozytorium, lub ponownie przesłać element, jeśli nie został zmodyfikowany lub wystąpił błąd w repozytorium źródłowym. Informacje o usuwaniu elementów znajdziesz w następnej sekcji.
Omówienie używania kolejek indeksowania do usuwania elementów
Strategia pełnego przeszukiwania używa procesu z 2 kolejami do indeksowania elementów i wykrywania usunięcia. Rysunek 2 przedstawia kroki związane z usunięciem elementu za pomocą 2 kolejek indeksowania. Rysunek 2 przedstawia drugi przeszukiwany graf wykonany przy użyciu strategii pełnego przeszukiwania. Te czynności wykorzystują wywołania interfejsu API REST. Aby uzyskać informacje o odpowiednich wywołaniach pakietu SDK, zapoznaj się z artykułem Operacje kolejki (Pakiet SDK usługi Connectors).
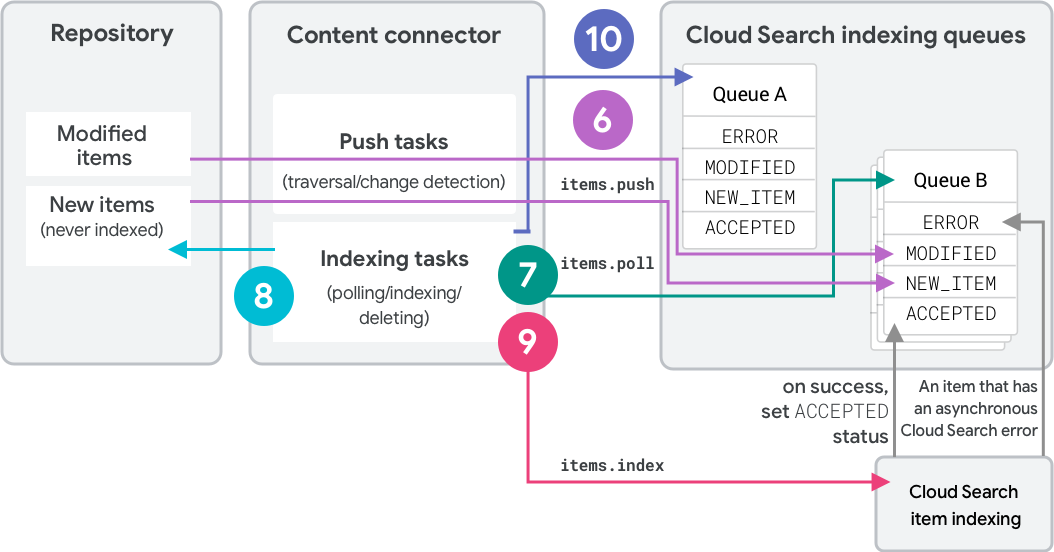
Podczas początkowego przetwarzania usługa Content Connector używa elementu
items.pushdo przesyłania elementów (metadanych i hasha) do kolejki indeksowania, czyli do „kolejki A”, ponieważ nie ma go w kolejce.NEW_ITEMKażdemu elementowi przypisana jest etykieta „A” oznaczająca „kolejka A”. Treści są indeksowane w Cloud Search.Połączenie treści używa
items.polldo odczytu kolejki A w celu określenia elementów do zindeksowania. Cloud Search informuje złącze, które elementy najbardziej potrzebują indeksowania. Są one posortowane najpierw według kodu stanu, a następnie według czasu oczekiwania w kolejce.Oprogramowanie sprzęgające pobiera te elementy z repozytorium i tworzy indeks żądań interfejsu API.
Łącznik używa do indeksowania elementów pliku
items.index. Element przechodzi w stanACCEPTEDdopiero po pomyślnym przetworzeniu go przez Cloud Search.Metoda
deleteQueueItemsjest wywoływana w przypadku kolejki „queue B”. Żadne elementy nie zostały jednak przesłane do kolejki B, więc nie można niczego usunąć.Podczas drugiego pełnego przejścia łącze treści używa
items.pushdo przesyłania elementów (metadanych i haszowania) do kolejki B:- Podczas przesyłania danych usługa łączy się z usługą docelową, aby przesłać dane.
typecontentHash - Jeśli w oprogramowaniu sprzęgającym nie ma parametru
type, Cloud Search automatycznie używa parametrucontentHashdo określania stanu elementu. - Jeśli element jest nieznany, jego stan jest ustawiany na
NEW_ITEM, a etykieta kolejki zmienia się na „B”. - Jeśli element istnieje i wartości skrótu są zgodne, stan pozostaje taki sam (
ACCEPTED), a etykieta kolejki zmienia się na „B”. - Jeśli element istnieje, ale hasze są różne, stan zmienia się na
MODIFIED, a etykieta kolejki na „B”.
- Podczas przesyłania danych usługa łączy się z usługą docelową, aby przesłać dane.
Połączenie treści używa interfejsu
items.polldo odczytywania kolejki w celu określenia elementów do zindeksowania. Cloud Search informuje złącze, które elementy najbardziej potrzebują indeksowania. Są one posortowane najpierw według kodu stanu, a następnie według czasu oczekiwania w kolejce.Oprogramowanie sprzęgające pobiera te elementy z repozytorium i tworzy indeks żądań interfejsu API.
Łącznik używa do indeksowania elementów pliku
items.index. Element przechodzi w stanACCEPTEDdopiero po pomyślnym przetworzeniu go przez Cloud Search.Wreszcie
deleteQueueItemsjest wywoływany w kolejce A, aby usunąć wszystkie wcześniej zindeksowane elementy CCloud Search, które nadal mają etykietę kolejki „A”.W przypadku kolejnych pełnych przejść kolejka używana do indeksowania i kolejka używana do usuwania są zamieniane.
Operacje kolejki (pakiet SDK łącznika)
Pakiet SDK Content Connector umożliwia przesyłanie elementów do kolejki i pobieranie ich z niej.
Aby spakować i przekazać element do kolejki, użyj klasy konstruktora pushItems.
Nie musisz wykonywać żadnych konkretnych czynności, aby pobrać elementy z kolejki do przetwarzania. Zamiast tego pakiet SDK automatycznie pobiera elementy z kolejki według kolejności priorytetów za pomocą metody klasy Repository getDoc.
Operacje kolejki (interfejs API REST)
Interfejs REST API udostępnia 2 metody przesyłania elementów do kolejki i wybierania elementów z niej:
- Aby dodać element do kolejki, użyj
Items.push. - Aby przeprowadzić ankietę dotyczącą elementów w kolejce, użyj elementu
Items.poll.
Możesz też użyć polecenia Items.index, aby dodać elementy do kolejki podczas indeksowania. Elementy dodane do kolejki podczas indeksowania nie wymagają stanu type i automatycznie otrzymują stan ACCEPTED.
Items.push
Metoda Items.push dodaje identyfikatory do kolejki. Ta metoda może być wywoływana z określoną wartością type, która określa wynik operacji push. Lista wartości type jest dostępna w polu item.type w metodzie Items.push.
Przesłanie nowego identyfikatora spowoduje dodanie nowego wpisu z kodem NEW_ITEM
ItemStatus.
Opcjonalny ładunek jest zawsze przechowywany, traktowany jako nieprzezroczysta wartość i zwracany z Items.poll.
Gdy element jest pobierany, jest zarezerwowany, co oznacza, że nie może zostać zwrócony przez inny wywołanie funkcji Items.poll.
Użycie funkcji Items.push z type zamiast NOT_MODIFIED, REPOSITORY_ERROR lub REQUEUE powoduje odblokowanie odczytanych wpisów. Więcej informacji o zarezerwowanych i niezarezerwowanych wpisach znajdziesz w sekcji Items.poll.
Items.push z haszami
Interfejs API Google Cloud Search umożliwia określenie wartości metadanych i wartości haszowanych treści w żądaniach Items.index. Zamiast podawać wartość type, wartości metadanych lub hasz treści można określić za pomocą żądania push. Kolejka indeksowania Cloud Search porównuje podane wartości haszowania z wartościami zapisanymi w źródle danych dla danego elementu. Jeśli nie ma zgodności, wpis jest oznaczony jako MODIFIED. Jeśli odpowiedni element nie istnieje w indeksie, stan to NEW_ITEM.
Items.poll
Metoda Items.poll pobiera z kolejki wpisy o najwyższym priorytecie. Wartości stanu żądane i zwracane wskazują stan żądanych kolejek priorytetowych lub stan zwróconych identyfikatorów.
Domyślnie zwracane są wpisy z dowolnej sekcji kolejki, zgodnie z priorytetem. Każdy zwrócony wpis jest zarezerwowany i nie jest zwracany przez inne wywołania funkcji Items.poll, dopóki nie wystąpi jeden z tych przypadków:
- Rezerwacja wygasa.
- Wpis jest ponownie dodawany do kolejki przez
Items.index. Items.pushjest wywoływany z parametremtypeo wartościNOT_MODIFIED,REPOSITORY_ERRORlubREQUEUE.