
Cloud Search의 검색어 해석은 사용자의 검색어에 있는 연산자와 필터를 자동으로 해석하여 이러한 요소를 구조화된 연산자 기반 검색어로 변환하는 기능입니다. 검색어 해석에서는 스키마에 정의된 연산자와 색인 생성된 문서를 함께 사용하여 사용자 검색어의 의미를 추론합니다. 사용자는 이 기능을 통해 최소한의 키워드로 검색하면서 정확한 결과를 얻을 수 있습니다.
사용자에게 실제로 제시되는 결과는 검색어 해석의 신뢰도에 좌우됩니다. 신뢰도는 색인 생성된 문서에서 검색어 문자열이 어디에 나오는지 등의 여러 가지 요소에 기초합니다. 예를 들어 배우 이름인 'Tom Hanks'와 같은 문자열은 actors라는 스키마 필드에 일관적으로 등장하므로 신뢰도가 높습니다. 같은 문자열('Tom Hanks')이 스키마 필드가 아닌 단락 내에 등장한다면 신뢰도가 떨어질 수 있습니다. 신뢰도가 높은 경우 검색어 해석의 결과만 사용자에게 표시됩니다. 신뢰도가 낮은 경우 검색어 해석의 결과가 일반 키워드 검색결과와 혼합됩니다.
검색어 해석의 예
데이터 소스의 예로서 영화 관련 정보를 수록한 데이터베이스가 있다고 가정해 보겠습니다. 그림 1에서는 샘플 검색어와 해석 결과를 보여줍니다.
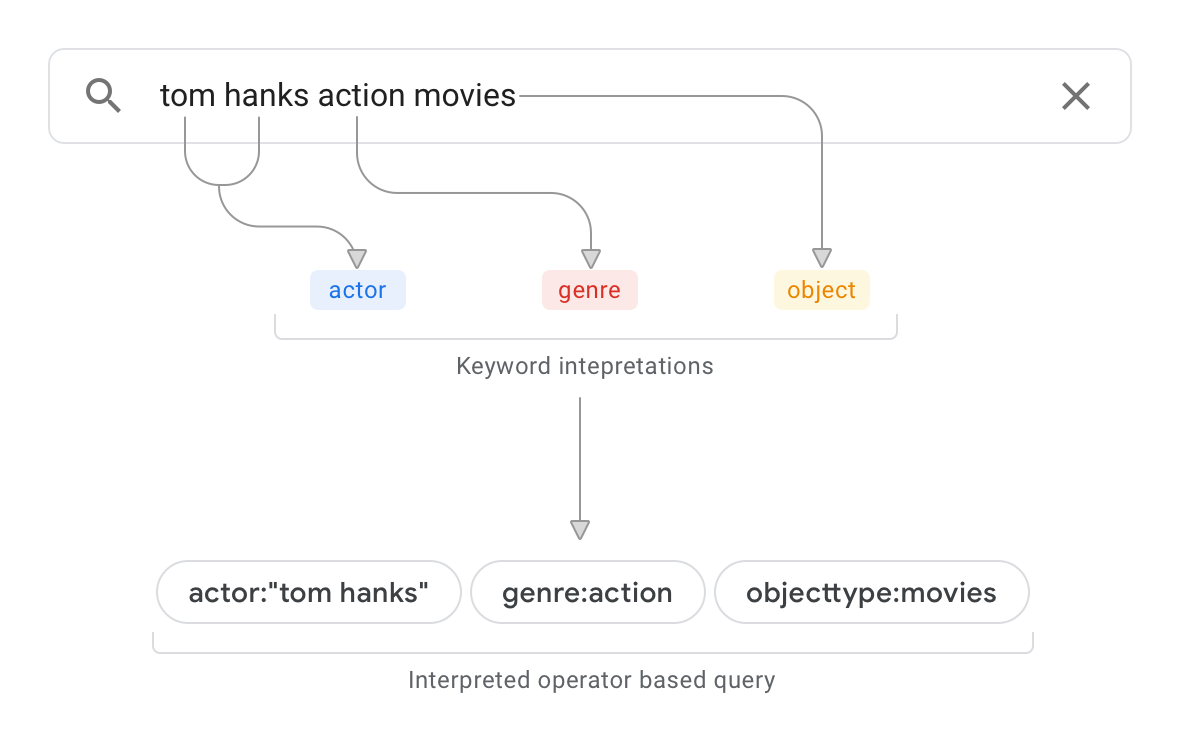
이 예에서 검색어 해석은 다음을 수행합니다.
스키마를 파싱하여 데이터 소스의 최상위 객체가
objecttype:movies로 분류되었음을 확인합니다. 검색어 해석에서는 이제 검색어 중 'movies'가 객체 유형임을 알게 되었습니다.스키마와 연계하여 데이터 소스의 문서를 검색하고 문자열 'action'이 나오는 위치를 판단합니다. 문자열이 특정 'genre' 데이터 소스 필드에 주로 등장한다면 검색어 해석에서는 'action'이 스키마에 정의된 'genre' 속성의 속성 값이라고 확신합니다. 문자열이 콘텐츠의 단락 맥락에서 주로 등장한다면 검색어 해석의 신뢰도 수준은 하락합니다.
검색어 해석 결과는 다음과 같습니다.
actor:“tom hanks” genre:action objecttype:movies
검색어 해석은 별도의 작업 없이 모든 Cloud Search 고객에게 자동으로 사용 설정됩니다. 그러나 검색어 해석을 최적화하려면 이 문서의 안내에 따라 스키마를 구조화해야 합니다.
검색어 해석을 지원하도록 스키마 구조화
검색어 해석의 이점을 누릴 수 있도록 스키마를 구조화해야 합니다.
표시 이름 해석 사용 설정
Cloud Search의 검색어 해석은 스키마에서 objectDefinitions 및 propertyDefinitions를 사용하여 사용자의 검색어를 해석하고 결과를 조정합니다. 이러한 스키마 요소의 이점을 극대화하려면 속성 이름에 displayLabel, 객체 이름에 objectDisplayLabel, 연산자에 operatorName을 사용하여 직관적인 표시 이름을 만들어야 합니다.
다음 스키마는 movie 객체의 직관적인 표시 이름을 보여줍니다.
{
"objectDefinitions": [
{
"name": "movie",
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
...
},
"propertyDefinitions": [
{
"name": "genre",
"isReturnable": true,
"isRepeatable": true,
"isFacetable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "genre"
}
},
"displayOptions": {
"displayLabel": "Category"
}
},
...
]
}
]
}
위 예시에 대한 설명은 다음과 같습니다.
movie 객체 정의에 'Film'
objectDisplayLabel이 있습니다.genre propertyDefinition의
operatorName은 'genre'이고displayLabel은 'Category'입니다.
Cloud Search는 이러한 표시 이름을 통해 다음과 같은 검색어 해석을 수행합니다.
- 'action movies', 'genre action type movies' 또는 'movies genre action'은
genre:action object:movies로 해석됩니다. - 'movies with genre action or thriller'는
objecttype:movies genre:(action OR thriller)로 해석됩니다. - 'action film' 또는 'action films'는
genre:action objecttype:movies로 해석됩니다. - 'comedy category movies'는
genre:comedy objecttype:movies로 해석됩니다.
날짜, 숫자, 정렬 해석 사용 설정
모든 날짜 및 숫자 속성에 대해 IntegerOperatorOptions에 지정된 lessThanOperatorName 및 greaterThanOperatorName를 정의해야 합니다. 이러한 설정을 통해 날짜 및 숫자를 자동으로 해석할 수 있습니다. 또한 정렬 해석을 사용 설정하려면 날짜 및 숫자 속성에 isSortable 옵션을 사용 설정합니다. 다음 스키마는 이러한 옵션을 사용 설정하는 방법을 보여줍니다.
{
"objectDefinitions": [
{
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
},
"propertyDefinitions": [
{
"name": "runtime",
"isReturnable": true,
"isSortable": true,
"integerPropertyOptions": {
"orderedRanking": "DESCENDING",
"minimumValue": {
"value": 10
},
"maximumValue": {
"value": 500
},
"operatorOptions": {
"operatorName": "runtime",
"lessThanOperatorName": "runtimelessthan",
"greaterThanOperatorName": "runtimegreaterthan"
}
},
"displayOptions": {
"displayLabel": "Length"
}
},
{
"name": "releasedate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "releasedate",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}
]
}
위 예시에 대한 설명은 다음과 같습니다.
- 숫자 속성
runtime은 영화의 길이를 나타냅니다. 이 속성에는runtimelessthan및runtimegreaterthan이 설정됩니다. - 날짜 속성
releaseDate는 영화의 극장 개봉일을 나타냅니다. 이 속성에는releasedbefore및releasedafter이 설정됩니다.
Cloud Search는 이러한 설정을 통해 다음과 같은 검색어 해석을 수행합니다.
- 지금이 2019년이라고 가정하면 'movies released this year'는
objecttype: movies releasedafter:2019-1-1 releasedbefore:2019-12-31로 해석됩니다. - 지금이 3월 셋째 주라고 가정하면 'movies released last week'는
objecttype: movies releasedafter:2019-3-10 releasedbefore:2019-3-16 - 'movies with runtime less than 90'는
objjecttype: movies runtimelessthan:90으로 해석됩니다. - 지금이 2019년이라고 가정하면 'movies released this year and length more than 120'은
releasedafter:2019-1-1 releasedbefore:2019-12-31 objecttype:movies runtimegreaterthan:120으로 해석됩니다. - 'sort movies by release date'는 'objecttype: movies'로 필터링하고 결과를 개봉일에 따라 기본 정렬 순서인 오름차순으로 정렬하여 제시합니다.
예약된 연산자 해석 사용 설정
type, before, after, objecttype 예약된 기본 제공 연산자를 사용하여 검색어 해석을 개선할 수도 있습니다. 문서를 색인 생성할 때 다음을 수행하세요.
before및after연산자를 사용하려면ItemMetadata에서updateTime필드를 채우세요. Cloud Search는 이러한 설정을 통해 다음과 같은 검색어 해석을 수행합니다.- 'movies from last week'는 색인에서 지난 주에 업데이트된 모든 영화를 나열합니다.
- 'movies before jan 2019'는 2019년 1월 이전에 색인 생성된 모든 영화를 나열합니다.
유형 자동 감지를 사용하려면
ItemMetadata의mimeType필드를 채웁니다. 검색어 'action videos'는 MIME 유형이application/mp4,application/mpeg4,application/x-shockwave-flash,video/,application/vnd.google-apps.video인 모든 액션 영화 문서를 나열합니다.
검색어 해석 제한사항
검색어 해석 기능에는 다음과 같은 제한사항이 있습니다.
- 검색어 해석은 다음과 같은 데이터 소스 ACL에만 유효합니다.
- 모든 문서가 도메인 공용임(도메인의 모든 사용자가 액세스 가능)
- 모든 문서가 데이터 소스 공용임(데이터 소스 ACL에 액세스 가능한 모든 사용자)
- 데이터 소스의 문서 중 대부분이 동일한 ACL을 가지며(모든 문서가 같은 컨테이너 항목의 ACL을 상속함) 추가적인 리더가 정의되지 않음
- 값이 동일한 여러 스키마 연산자가 있으면 검색어에서 해당 값의 연산자 인텐트 해석은 검색어 해석 시스템이 반환하는 전체적인 신뢰도 요소에 좌우됩니다. 예를 들어 스키마에 연산자 이름이 동일한
priority및severity속성이 정의되어 있으며 두 연산자가 0, 1, 2 또는 3 값을 가질 수 있다고 가정해 보겠습니다. 이 예에서 검색어의 '0'이 나타내는 연산자 값은priority일 수도,severity일 수도 있습니다. 이러한 값에 모호성이 있으므로 신뢰도 수준이 하락합니다. - 기본적으로 Cloud Search의 검색어 해석은 검색어를 해석할 때 필드 값을 소문자로 변환하지만,
exactMatchWithOperator옵션과 함께 정의된 텍스트 연산자는 예외입니다. source연산자는 검색어에서 지원되지 않습니다.- 연산자 기반 용어와 자유 텍스트 용어를 조합한 검색어는 해석되지 않습니다. 예를 들어 'p0 priority cases'는 자유 텍스트 용어이고 'severity:s0'은 연산자 기반 용어이므로 'p0 priority cases severity:s0'은 지원되지 않습니다.
- 검색어 해석 전략에서는 항상 해석된 결과와 일반 결과(해석 없이 관련성 순위를 적용한 결과)가 혼합되며 결과 페이지 전체를 대체하지는 않습니다.