
Die Abfrageauswertung von Cloud Search interpretiert automatisch die Operatoren und Filter in der Suchanfrage eines Nutzers und wandelt diese Elemente in eine strukturierte, operatorbasierte Abfrage um. Bei der Abfrageauswertung werden die im Schema definierten Operatoren zusammen mit den indexierten Dokumenten verwendet, um die Bedeutung der Suchanfrage des Nutzers zu ermitteln. Mit dieser Funktion können Nutzer mit wenigen Keywords suchen und trotzdem präzise Ergebnisse erhalten.
Die tatsächlichen Ergebnisse, die dem Nutzer angezeigt werden, hängen vom Vertrauensniveau der Abfrageinterpretation ab. Die Zuverlässigkeit basiert auf mehreren Faktoren, unter anderem darauf, wo die Suchstrings in indexierten Dokumenten vorkommen. Ein String wie der Name des Schauspielers „Tom Hanks“, der regelmäßig in einem Schemafeld namens actors vorkommt, führt zu einer höheren Wahrscheinlichkeit. Wenn derselbe String („Tom Hanks“) in einem Absatz und nicht in einem Schemafeld erscheint, kann das zu einer geringeren Konfidenz führen. Bei hoher Wahrscheinlichkeit werden dem Nutzer nur Ergebnisse aus der Abfrageinterpretation angezeigt. Bei geringerer Sicherheit werden die Ergebnisse der Abfrageinterpretation mit den Ergebnissen einer normalen Keyword-Suche kombiniert.
Beispiel für die Interpretation einer Anfrage
Angenommen, Sie haben eine Datenquelle, z. B. eine Datenbank, die Informationen zu Filmen enthält. Abbildung 1 zeigt eine Beispielsuchanfrage und die daraus resultierende Interpretation.
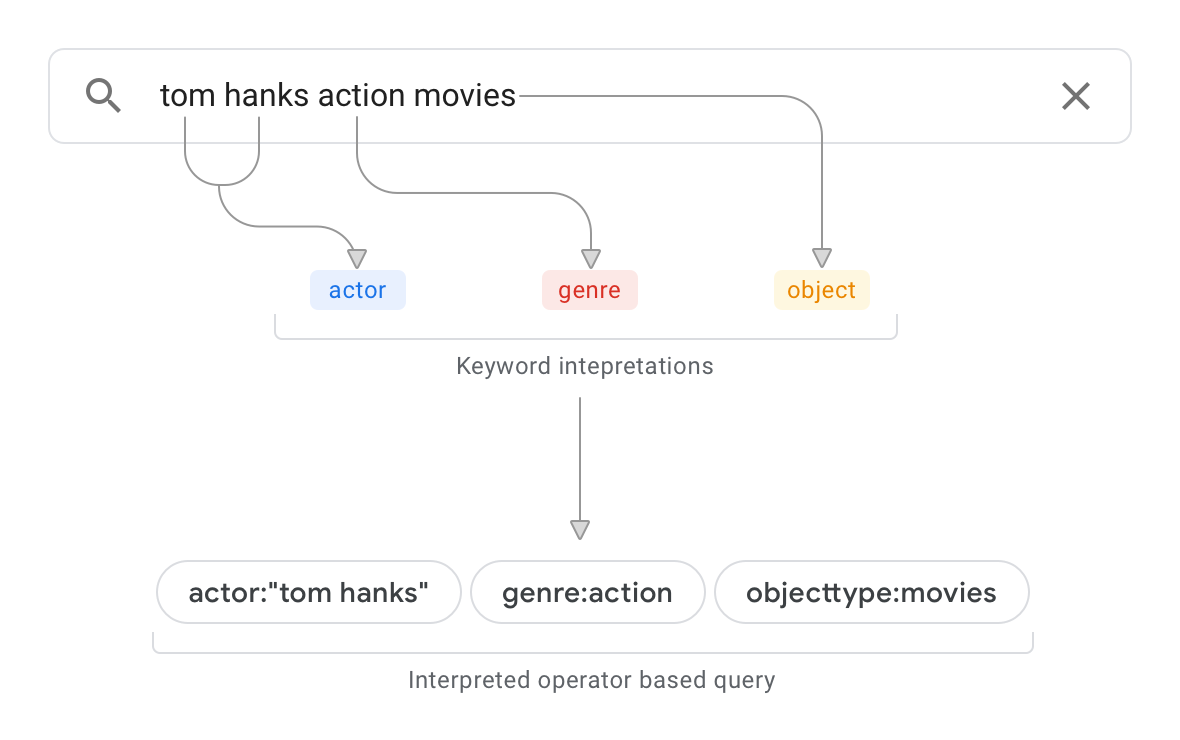
Bei dieser Beispielabfrage geschieht bei der Abfrageauswertung Folgendes:
Das Schema wird analysiert und es wird festgestellt, dass die Objekte der obersten Ebene in der Datenquelle als
objecttype:moviesklassifiziert sind. Die Abfrageauswertung weiß jetzt, dass „movies“ in der Abfrage ein Objekttyp ist.Es werden Dokumente in der Datenquelle in Verbindung mit dem Schema gescannt, um zu ermitteln, wo der String „Aktion“ vorkommt. Wenn der String hauptsächlich in einem bestimmten Datenquellenfeld „Genre“ vorkommt, ist bei der Abfrageauswertung die Wahrscheinlichkeit hoch, dass „Action“ ein Attributwert für das im Schema definierte Attribut „Genre“ ist. Wenn der String hauptsächlich im Kontext von Textabsätzen vorkommt, sinkt das Konfidenzniveau der Abfrageinterpretation.
Die Abfrage wird so interpretiert:
actor:“tom hanks” genre:action objecttype:movies
Die Suchanfrage-Interpretation wird für alle Cloud Search-Kunden automatisch aktiviert. Für eine optimale Abfrageauswertung sollten Sie Ihr Schema jedoch gemäß der Anleitung in diesem Dokument strukturieren.
Schema für die Abfrageauswertung strukturieren
Sie sollten Ihr Schema so strukturieren, dass Sie von der Abfrageauswertung profitieren können.
Interpretationen von Anzeigenamen aktivieren
Bei der Abfrageauswertung von Cloud Search werden die Elemente objectDefinitions und propertyDefinitions in einem Schema verwendet, um die Suchanfrage eines Nutzers zu interpretieren und die Ergebnisse zu optimieren. Um diese Schemaelemente optimal zu nutzen, sollten Sie intuitive Anzeigenamen erstellen. Verwenden Sie dazu displayLabel für Eigenschaftsnamen, objectDisplayLabel für Objektnamen und operatorName für Operatoren.
Das folgende Schema zeigt intuitive Anzeigenamen für ein Filmobjekt:
{
"objectDefinitions": [
{
"name": "movie",
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
...
},
"propertyDefinitions": [
{
"name": "genre",
"isReturnable": true,
"isRepeatable": true,
"isFacetable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "genre"
}
},
"displayOptions": {
"displayLabel": "Category"
}
},
...
]
}
]
}
Im vorherigen Beispiel:
Die Filmobjektdefinition enthält ein „Film“-
objectDisplayLabel.Die Genre-PropertyDefinition hat ein „Genre“
operatorNameund eine „Kategorie“displayLabel.
Anhand dieser Anzeigenamen kann Cloud Search die folgenden Suchanfragen interpretieren:
- „Actionfilme“, „Actionfilme (Genre)“ oder „Filme (Genre: Action)“ werden als
genre:action object:moviesinterpretiert. - „Filme mit dem Genre Action oder Thriller“ wird als
objecttype:movies genre:(action OR thriller)interpretiert. - „Actionfilm“ oder „Actionfilme“ wird als
genre:action objecttype:moviesinterpretiert. - „Komödien – Filme“ wird als
genre:comedy objecttype:moviesinterpretiert.
Datums-, Zahlen- und Sortierinterpretationen aktivieren
Sie sollten lessThanOperatorName und greaterThanOperatorName, wie in IntegerOperatorOptions angegeben, für alle Datums- und numerischen Properties definieren. Mit diesen Einstellungen werden automatische Datums- und Zahleninterpretationen aktiviert. Wenn Sie Sortierinterpretationen aktivieren möchten, legen Sie für Datums- und numerische Properties die Option isSortable fest. Das folgende Schema zeigt, wie Sie diese Optionen aktivieren.
{
"objectDefinitions": [
{
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
},
"propertyDefinitions": [
{
"name": "runtime",
"isReturnable": true,
"isSortable": true,
"integerPropertyOptions": {
"orderedRanking": "DESCENDING",
"minimumValue": {
"value": 10
},
"maximumValue": {
"value": 500
},
"operatorOptions": {
"operatorName": "runtime",
"lessThanOperatorName": "runtimelessthan",
"greaterThanOperatorName": "runtimegreaterthan"
}
},
"displayOptions": {
"displayLabel": "Length"
}
},
{
"name": "releasedate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "releasedate",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}
]
}
Im vorherigen Beispiel:
- Die numerische Eigenschaft
runtimebezieht sich auf die Länge eines Films. Für diese Property sindruntimelessthanundruntimegreaterthanfestgelegt. - Das Datumsattribut
releaseDatebezieht sich auf das Datum, an dem ein Film in den Kinos veröffentlicht wird. Die Propertiesreleasedbeforeundreleasedaftersind für diese Property festgelegt.
Mit diesen Einstellungen kann Cloud Search die folgenden Suchanfragen interpretieren:
- Angenommen, das Jahr ist 2019, wird „in diesem Jahr veröffentlichte Filme“ als
objecttype: movies releasedafter:2019-1-1 releasedbefore:2019-12-31interpretiert. - Angenommen, es ist die dritte Woche im März, wird „in der letzten Woche veröffentlichte Filme“ als
objecttype: movies releasedafter:2019-3-10 releasedbefore:2019-3-16interpretiert. - „Filme mit einer Laufzeit von weniger als 90 Minuten“ wird als
objjecttype: movies runtimelessthan:90interpretiert. - Angenommen, das Jahr ist 2019, wird „Filme, die in diesem Jahr veröffentlicht wurden und eine Länge von mehr als 120 Minuten haben“ als
releasedafter:2019-1-1 releasedbefore:2019-12-31 objecttype:movies runtimegreaterthan:120interpretiert. - Mit „filme nach Veröffentlichungsdatum sortieren“ wird nach „objecttype: movies“ gefiltert und die Ergebnisse werden nach dem Veröffentlichungsdatum sortiert. Die Standardsortierung ist aufsteigend.
Interpretation reservierter Operatoren aktivieren
Sie können auch die reservierten vordefinierten Operatoren type, before, after und objecttype verwenden, um die Abfrageauswertung zu verbessern. Gehen Sie so vor, wenn Sie ein Dokument indexieren möchten:
Geben Sie einen Wert in das Feld
updateTimeinItemMetadataein, um die Operatorenbeforeundafterzu verwenden. Mit diesen Einstellungen kann Cloud Search die folgenden Suchanfragen interpretieren:- Mit „Filme der letzten Woche“ werden alle Filme aufgelistet, die in der Vorwoche im Index aktualisiert wurden.
- Mit „filme vor jan 2019“ werden alle Filme aufgelistet, die vor Januar 2019 indexiert wurden.
Fülle das Feld
mimeTypeimItemMetadataaus, um die automatische Typerkennung zu verwenden. Bei der Abfrage „Actionvideos“ werden alle Dokumente mit dem Mime-Typapplication/mp4,application/mpeg4,application/x-shockwave-flash,video/undapplication/vnd.google-apps.videoaufgelistet.
Einschränkungen bei der Abfrageauswertung
Die Funktion zur Abfrageauswertung weist die folgenden Einschränkungen auf:
- Die Abfrageauswertung funktioniert nur für die folgenden ACLs für Datenquellen:
- Alle Dokumente sind öffentlich für die Domain (alle Nutzer in der Domain können darauf zugreifen).
- Alle Dokumente sind öffentlich zugänglich (alle Nutzer, die Zugriff auf die ACL der Datenquelle haben).
- Die meisten Dokumente in der Datenquelle haben dieselbe ACL (alle Dokumente übernehmen die ACL vomselben Containerelement) und es sind keine zusätzlichen Leser definiert.
- Wenn mehrere Schemaoperatoren denselben Wert haben, hängt die Interpretation dieses Werts als Operatorabsicht für eine Abfrage vom Gesamtvertrauensfaktor ab, der vom System zur Abfrageinterpretation zurückgegeben wird. Angenommen, Sie haben die Attribute
priorityundseveritymit denselben im Schema definierten Operatornamen. Angenommen, beide Operatoren können die Werte 0, 1, 2 oder 3 haben. In diesem Beispiel kann „0“ in einer Abfrage auf den Operatorwert fürpriorityoderseverityverweisen. Diese Werte sind mehrdeutig und der Konfidenzgrad ist niedriger. - Standardmäßig werden bei der Abfrageauswertung in Cloud Search Feldwerte in Kleinbuchstaben geschrieben, mit Ausnahme von Textoperatoren, die mit
exactMatchWithOperator-Optionen definiert sind. - Der Operator
sourcewird in Abfragen nicht unterstützt. - Abfragen, die operatorbasierte Begriffe und Begriffe aus dem freien Text kombinieren, werden nicht interpretiert. Die Suchanfrage „p0 priority cases severity:s0“ wird beispielsweise nicht unterstützt, da „p0 priority cases“ ein kostenloser Textbegriff ist, während „severity:s0“ ein operatorbasierter Begriff ist.
- Bei der Strategie zur Abfrageinterpretation werden die interpretierten Ergebnisse immer mit normalen (nicht interpretierten, nach Relevanz sortierten) Ergebnissen kombiniert. Es wird keine vollständige Seitenauslagerung der Ergebnisse durchgeführt.