
Cloud Search की क्वेरी के बारे में जानकारी देने वाली सुविधा, उपयोगकर्ता की क्वेरी में ऑपरेटर और फ़िल्टर का अपने-आप विश्लेषण करती है. साथ ही, उन एलिमेंट को ऑपरेटर पर आधारित क्वेरी में बदल देती है. क्वेरी का विश्लेषण करने के लिए, इंडेक्स किए गए दस्तावेज़ों के साथ-साथ स्कीमा में तय किए गए ऑपरेटर का इस्तेमाल किया जाता है. इससे यह पता चलता है कि उपयोगकर्ता की क्वेरी का क्या मतलब है. इस सुविधा की मदद से, उपयोगकर्ता कम से कम कीवर्ड का इस्तेमाल करके भी सटीक नतीजे पा सकता है.
उपयोगकर्ता को दिखाए जाने वाले असल नतीजे, क्वेरी के विश्लेषण के भरोसे पर निर्भर करते हैं. कॉन्फ़िडेंस कई बातों पर निर्भर करता है. जैसे, इंडेक्स किए गए दस्तावेज़ों में क्वेरी स्ट्रिंग कहां दिखती हैं. actors नाम के स्कीमा फ़ील्ड में, अभिनेता "टॉम हैंक्स" का नाम लगातार दिखने पर, कॉन्फ़िडेंस लेवल ज़्यादा होता है. स्कीमा फ़ील्ड के बजाय पैराग्राफ़ में दिखने वाली एक ही स्ट्रिंग ("टॉम हैंक्स") की वजह से, कॉन्फ़िडेंस लेवल कम हो सकता है. अगर क्वेरी के बारे में काफ़ी भरोसा है, तो उपयोगकर्ता को सिर्फ़ क्वेरी के हिसाब से दिए गए नतीजे दिखाए जाते हैं. कम भरोसे के मामले में, क्वेरी के हिसाब से दिए गए नतीजों को सामान्य कीवर्ड खोज के नतीजों के साथ ब्लेंड किया जाता है.
क्वेरी के विश्लेषण का उदाहरण
मान लें कि आपके पास डेटा सोर्स है, जैसे कि कोई डेटाबेस, जिसमें फ़िल्मों के बारे में जानकारी है. पहली इमेज में, खोज क्वेरी का सैंपल और उसके नतीजे के तौर पर मिले अनुमान को दिखाया गया है.
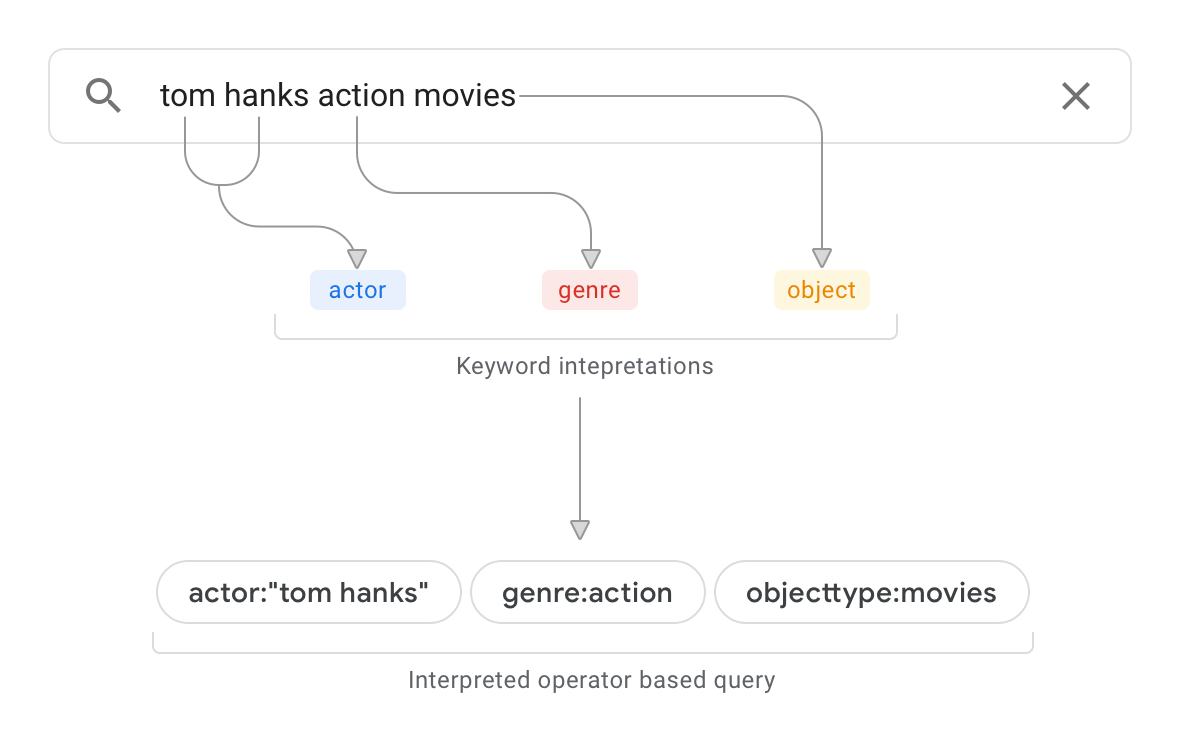
इस उदाहरण के तौर पर दी गई क्वेरी के लिए, क्वेरी का विश्लेषण करने की सुविधा ये काम करती है:
स्कीमा को पार्स करता है और यह तय करता है कि डेटा सोर्स में सबसे ऊपर के लेवल के ऑब्जेक्ट को
objecttype:moviesके तौर पर बांटा गया है. क्वेरी के बारे में जानकारी देने वाली सुविधा को अब पता है कि क्वेरी में "फ़िल्में" एक ऑब्जेक्ट टाइप है.स्कीमा के साथ मिलकर, डेटा सोर्स में मौजूद दस्तावेज़ों को स्कैन करता है, ताकि यह पता लगाया जा सके कि स्ट्रिंग "कार्रवाई" कहां दिखती है. अगर स्ट्रिंग मुख्य रूप से किसी खास "genre" डेटा सोर्स फ़ील्ड में मौजूद है, तो क्वेरी के विश्लेषण से यह पता चलता है कि "action", स्कीमा में बताई गई प्रॉपर्टी "genre" की प्रॉपर्टी वैल्यू है. अगर स्ट्रिंग मुख्य रूप से कॉन्टेंट के पैराग्राफ़ के संदर्भ में होती है, तो क्वेरी के हिसाब से अनुमान लगाने के कॉन्फ़िडेंस लेवल में कमी आती है.
क्वेरी का यह मतलब है:
actor:“tom hanks” genre:action objecttype:movies
क्वेरी का विश्लेषण करने की सुविधा, Cloud Search के सभी ग्राहकों के लिए अपने-आप चालू हो जाती है. इसके लिए, उन्हें कुछ भी करने की ज़रूरत नहीं होती. हालांकि, क्वेरी को बेहतर तरीके से समझने के लिए, आपको इस दस्तावेज़ में दिए गए निर्देशों के मुताबिक अपना स्कीमा बनाना चाहिए.
क्वेरी के हिसाब से जानकारी देने के लिए, अपने स्कीमा को स्ट्रक्चर करना
आपको अपने स्कीमा को इस तरह से बनाना चाहिए कि आपको क्वेरी के विश्लेषण से फ़ायदा मिल सके.
डिसप्ले नेम के लिए अनुवाद की सुविधा चालू करना
Cloud Search में क्वेरी को समझने की सुविधा, किसी उपयोगकर्ता की क्वेरी को समझने और नतीजों को बेहतर बनाने के लिए, स्कीमा में objectDefinitions और propertyDefinitions का इस्तेमाल करती है. इन स्कीमा एलिमेंट का ज़्यादा से ज़्यादा फ़ायदा पाने के लिए, आपको प्रॉपर्टी के नामों के लिए displayLabel, ऑब्जेक्ट के नामों के लिए objectDisplayLabel, और ऑपरेटर के लिए operatorName का इस्तेमाल करके, आसानी से समझ आने वाले डिसप्ले नेम बनाने चाहिए.
नीचे दिया गया स्कीमा, किसी फ़िल्म ऑब्जेक्ट के लिए आसानी से समझ आने वाले डिसप्ले नेम दिखाता है:
{
"objectDefinitions": [
{
"name": "movie",
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
...
},
"propertyDefinitions": [
{
"name": "genre",
"isReturnable": true,
"isRepeatable": true,
"isFacetable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "genre"
}
},
"displayOptions": {
"displayLabel": "Category"
}
},
...
]
}
]
}
पिछले उदाहरण में:
फ़िल्म ऑब्जेक्ट की परिभाषा में “फ़िल्म”
objectDisplayLabelहै.शैली की प्रॉपर्टी की परिभाषा में “शैली”
operatorNameऔर “कैटगरी”displayLabelहै.
इन डिसप्ले नेम की मदद से, Cloud Search इन क्वेरी का विश्लेषण कर सकता है:
- “ऐक्शन फ़िल्में,” “ऐक्शन शैली वाली फ़िल्में” या “फ़िल्में ऐक्शन शैली” को
genre:action object:moviesके तौर पर समझा जाता है. - “ऐक्शन या थ्रिलर शैली वाली फ़िल्में” को
objecttype:movies genre:(action OR thriller)के तौर पर समझा जाता है. - “ऐक्शन फ़िल्म” या “ऐक्शन फ़िल्में” को
genre:action objecttype:moviesके तौर पर समझा जाता है. - “कॉमेडी कैटगरी वाली फ़िल्में” को
genre:comedy objecttype:moviesके तौर पर समझा जाता है.
तारीख, संख्या, और क्रम से लगाने की सुविधा चालू करना
आपको तारीख और संख्या वाली सभी प्रॉपर्टी के लिए, IntegerOperatorOptions में बताई गई lessThanOperatorName और greaterThanOperatorName प्रॉपर्टी तय करनी चाहिए. इन सेटिंग की मदद से, तारीख और संख्याओं के अपने-आप होने वाले अनुवाद की सुविधा चालू होती है. इसके अलावा, क्रम से लगाने के तरीके को चालू करने के लिए,
तारीख और संख्या वाली प्रॉपर्टी के लिए isSortable विकल्प सेट करें. नीचे दिए गए स्कीमा में, इन विकल्पों को चालू करने का तरीका बताया गया है.
{
"objectDefinitions": [
{
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
},
"propertyDefinitions": [
{
"name": "runtime",
"isReturnable": true,
"isSortable": true,
"integerPropertyOptions": {
"orderedRanking": "DESCENDING",
"minimumValue": {
"value": 10
},
"maximumValue": {
"value": 500
},
"operatorOptions": {
"operatorName": "runtime",
"lessThanOperatorName": "runtimelessthan",
"greaterThanOperatorName": "runtimegreaterthan"
}
},
"displayOptions": {
"displayLabel": "Length"
}
},
{
"name": "releasedate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "releasedate",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}
]
}
पिछले उदाहरण में:
- अंकों वाली प्रॉपर्टी
runtimeसे, किसी फ़िल्म की अवधि का पता चलता है. इस प्रॉपर्टी के लिए,runtimelessthanऔरruntimegreaterthanसेट है. - तारीख की प्रॉपर्टी
releaseDateसे पता चलता है कि फ़िल्म को थिएटर में कब रिलीज़ किया गया था. इस प्रॉपर्टी के लिएreleasedbeforeऔरreleasedafterसेट है.
इन सेटिंग की मदद से, Cloud Search इन क्वेरी का विश्लेषण कर सकता है:
- मान लें कि साल 2019 है, तो “इस साल रिलीज़ हुई फ़िल्में” का मतलब
objecttype: movies releasedafter:2019-1-1 releasedbefore:2019-12-31है. - मान लें कि यह मार्च का तीसरा हफ़्ता है, तो “पिछले हफ़्ते रिलीज़ हुई फ़िल्में” का मतलब
objecttype: movies releasedafter:2019-3-10 releasedbefore:2019-3-16 - “90 मिनट से कम चलने वाली फ़िल्में” को
objjecttype: movies runtimelessthan:90के तौर पर समझा जाता है. - मान लें कि साल 2019 है, तो “इस साल रिलीज़ हुई और 120 मिनट से ज़्यादा अवधि वाली फ़िल्में” को
releasedafter:2019-1-1 releasedbefore:2019-12-31 objecttype:movies runtimegreaterthan:120के तौर पर समझा जाएगा. - “रिलीज़ की तारीख के हिसाब से फ़िल्में क्रम से लगाएं” से, “objecttype: movies” फ़िल्टर किया जाएगा. साथ ही, दिखाए गए नतीजों को रिलीज़ की तारीख के हिसाब से क्रम से लगाया जाएगा. डिफ़ॉल्ट रूप से, नतीजों को बढ़ते क्रम में लगाया जाएगा.
रिज़र्व किए गए ऑपरेटर का मतलब समझने की सुविधा चालू करना
क्वेरी के विश्लेषण को बेहतर बनाने के लिए, type, before, after, objecttype के लिए रिज़र्व किए गए पहले से मौजूद ऑपरेटर का भी इस्तेमाल किया जा सकता है. किसी दस्तावेज़ को इंडेक्स करते समय, ये काम करें:
beforeऔरafterऑपरेटर का इस्तेमाल करने के लिए,ItemMetadataमेंupdateTimeफ़ील्ड को पॉप्युलेट करें. इन सेटिंग की मदद से, Cloud Search इन क्वेरी का विश्लेषण कर सकता है:- “पिछले हफ़्ते की फ़िल्में” से, उन सभी फ़िल्मों की सूची दिखेगी जिन्हें पिछले हफ़्ते इंडेक्स में अपडेट किया गया था.
- “movies before jan 2019” से, जनवरी 2019 से पहले इंडेक्स की गई सभी मूवी की सूची दिखेगी.
टाइप का अपने-आप पता चलने की सुविधा का इस्तेमाल करने के लिए,
ItemMetadataमेंmimeTypeफ़ील्ड को पॉप्युलेट करें. “ऐक्शन वीडियो” क्वेरी से,application/mp4,application/mpeg4,application/x-shockwave-flash,video/, औरapplication/vnd.google-apps.videoMIME टाइप वाली ऐक्शन मूवी के सभी दस्तावेज़ दिखेंगे.
क्वेरी के हिसाब से जानकारी देने की सुविधा की सीमाएं
क्वेरी के मतलब का पता लगाने की सुविधा की ये सीमाएं हैं.
- क्वेरी का मतलब समझने की सुविधा, सिर्फ़ इन डेटा सोर्स के एसीएल के लिए काम करती है:
- सभी दस्तावेज़ डोमेन के लिए सार्वजनिक होते हैं. इसका मतलब है कि डोमेन में मौजूद कोई भी व्यक्ति उन्हें ऐक्सेस कर सकता है.
- सभी दस्तावेज़, डेटा सोर्स के लिए सार्वजनिक होते हैं. इसका मतलब है कि जिन लोगों के पास डेटा सोर्स के ऐक्सेस कंट्रोल (एसीएल) का ऐक्सेस होता है वे सभी दस्तावेज़ ऐक्सेस कर सकते हैं.
- डेटा सोर्स के ज़्यादातर दस्तावेज़ों में एक ही एसीएल होता है. सभी दस्तावेज़, एक ही कंटेनर आइटम से एसीएल इनहेरिट करते हैं. साथ ही, इनमें कोई अन्य रीडर तय नहीं किया जाता.
- अगर कई स्कीमा ऑपरेटर की वैल्यू एक जैसी है, तो क्वेरी के लिए ऑपरेटर के इंटेंट के तौर पर उस वैल्यू का विश्लेषण, क्वेरी के विश्लेषण के सिस्टम से मिले कुल कॉन्फ़िडेंस फ़ैक्टर पर निर्भर करता है. उदाहरण के लिए, मान लें कि आपके पास स्कीमा में तय किए गए ऑपरेटर के एक ही नाम वाली
priorityऔरseverityप्रॉपर्टी हैं. मान लें कि दोनों ऑपरेटर की वैल्यू 0, 1, 2 या 3 हो सकती है. इस उदाहरण में, क्वेरी में "0" का मतलबpriorityयाseverityमें से किसी एक ऑपरेटर की वैल्यू से हो सकता है. ये वैल्यू अस्पष्ट होती हैं और कॉन्फ़िडेंस लेवल कम होता है. - डिफ़ॉल्ट रूप से, Cloud Search की क्वेरी के हिसाब से फ़ील्ड की वैल्यू को छोटा कर दिया जाता है. हालांकि,
exactMatchWithOperatorविकल्पों के साथ तय किए गए टेक्स्ट ऑपरेटर के लिए ऐसा नहीं किया जाता. sourceऑपरेटर, क्वेरी में काम नहीं करता.- ऑपरेटर पर आधारित शब्दों और फ़्री टेक्स्ट शब्दों को जोड़ने वाली क्वेरी का विश्लेषण नहीं किया जाता. उदाहरण के लिए, क्वेरी "p0 priority cases severity:s0" काम नहीं करेगी, क्योंकि "p0 priority cases" एक फ़्री टेक्स्ट-टर्म है, जबकि "severity:s0" एक ऑपरेटर-आधारित टर्म है.
- क्वेरी के हिसाब से जानकारी देने की रणनीति, हमेशा सामान्य (बिना जानकारी दिए, काम के हिसाब से रैंक किए गए) नतीजों के साथ, जानकारी वाले नतीजों को ब्लेंड करती है. यह नतीजों के पूरे पेज को बदलने का काम नहीं करता.