集計レポートにおけるノイズの取り扱い方法、影響を考慮し、影響を軽減する方法を解説します。
始める前に
先に進む前に、ノイズの概要とその影響について詳しくは、概要レポートのノイズについてをご覧ください。
ノイズの管理
集計可能レポートに追加されるノイズを直接制御することはできませんが、いくつかの手順を実施することで影響を最小限に抑えることができます。以降のセクションでは、これらの戦略について説明します。
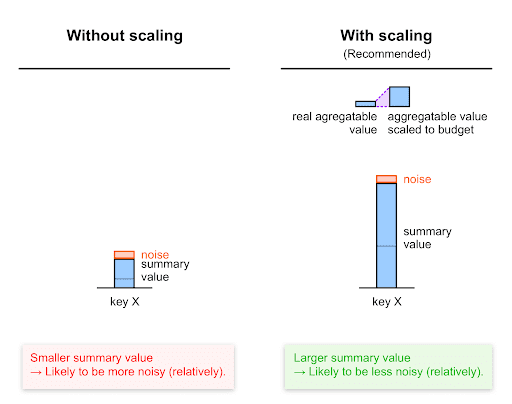
資金提供の予算までスケールアップする
「ノイズを理解する」で説明したように、各キーのサマリー値に適用されるノイズは、0 ~ 65,536 のスケール(0 ~CONTRIBUTION_BUDGET)に基づいています。

そのため、ノイズに対するシグナルを最大化するには、各値をスケールアップしてから、集計値として設定します。つまり、各値に特定の係数(スケーリング係数)を掛けて、貢献度の予算内に収まるようにする必要があります。
スケーリング ファクタの計算
スケーリング ファクタは、特定の集計可能値をどの程度スケーリングするかを表します。 この値は、寄与の予算を特定のキーの集計可能な最大値で割ったものである必要があります。
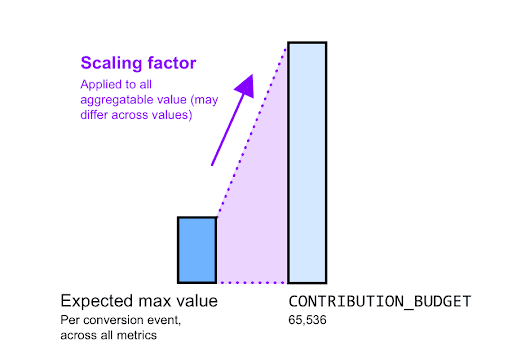
たとえば、広告主が合計購入額を知りたいとします。いくつかの外れ値を無視する例外を除き、個々の購入の予想購入額の最大値は $2,000 です。
- スケーリング ファクタを計算します。
<ph type="x-smartling-placeholder">
- </ph>
- SN 比を最大化するには、この値を 65,536(分担予算)に調整する必要があります。
- つまり、約 32x のスケーリング ファクタは 65,536 ÷ 2,000 になります。実際には、この係数を切り上げたり、切り上げたりできます。
- 集計の前に値をスケールアップします。購入が $1 ごとに、トラッキング対象の指標を 32 ずつ増やします。たとえば、12,000 円の購入の場合は、集計可能な値を 120 × 32 = 3,840 に設定します。
- 集計後に値をスケールダウンします。複数のユーザーにわたって合計された購入額を含む概要レポートを受け取ったら、集計前に使用したスケーリング ファクタを使用して概要値をスケールダウンします。この例では、事前集計でスケーリング ファクタを 32 にしたため、概要レポートで受け取った概要値を 32 で割る必要があります。したがって、概要レポートの特定のキーの総購入額が 76,800 の場合、総購入額(ノイズあり)は 76,800÷32 = $2,400 となります。
予算を配分する
購入回数と購入額など、測定の目標が複数ある場合は、それらの目標に予算を配分することをおすすめします。
この場合、所定の集計可能値に予想される最大値に応じて、集計可能値ごとにスケーリング ファクタが異なります。
詳しくは、集計キーについてをご覧ください。
たとえば、購入回数と購入額の両方をトラッキングしており、予算を均等に配分するとします。
65,536 ÷ 2 = 32,768 は、測定タイプとソースごとに割り当てることができます。
- 購入数:
<ph type="x-smartling-placeholder">
- </ph>
- トラッキングしている購入が 1 回のみであるため、1 回のコンバージョンあたりの購入回数の上限は 1 回とします。
- したがって、購入数のスケーリング ファクタを 32,768 ÷ 1 = 32,768 に設定します。
- 購入額:
<ph type="x-smartling-placeholder">
- </ph>
- 個々の購入の見込み購入額の最高値は $2,000 とします。
- したがって、購入額のスケーリング ファクタを 32,768 ÷ 2,000 = 16.384、つまり約 16 に設定します。
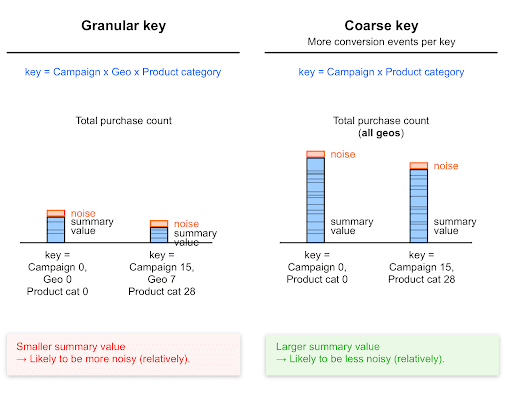
粗い集計キーにより信号雑音比が向上
大まかなキーよりも大まかなキーの方が多くのコンバージョン イベントを検出できるため、通常、大まかなキーを使用するとサマリー値が大きくなります。
サマリー値が高いほど、低い値よりもノイズの影響を受けにくくなります。これらの値のノイズは、この値よりも低くなる可能性があります。
粗いキーで収集された値は、粒度の細かいキーで収集された値よりもノイズが相対的に少なくなる可能性があります。
例
他の条件をすべて同じにすると、購入額をグローバルにトラッキングするキー(すべての国で合計)は、国レベルでコンバージョンをトラッキングするキーよりも、サマリーの購入額(およびサマリーのコンバージョン数)が多くなります。
そのため、特定の国の合計購入額に対する相対的なノイズは、すべての国の合計購入額に関する相対的なノイズよりも高くなります。
同様に、他の条件がすべて同じであれば、靴の合計購入額は、すべてのアイテム(靴を含む)の合計購入額よりも低くなります。
そのため、靴の合計購入額に対する相対的なノイズは、すべてのアイテムの合計購入額に対する相対的なノイズよりも高くなります。
サマリー値(ロールアップ)を合計すると、ノイズも合計されます
概要レポートの概要値を合計して上位レベルのデータにアクセスすることで、それらの概要値からのノイズも合計されます。
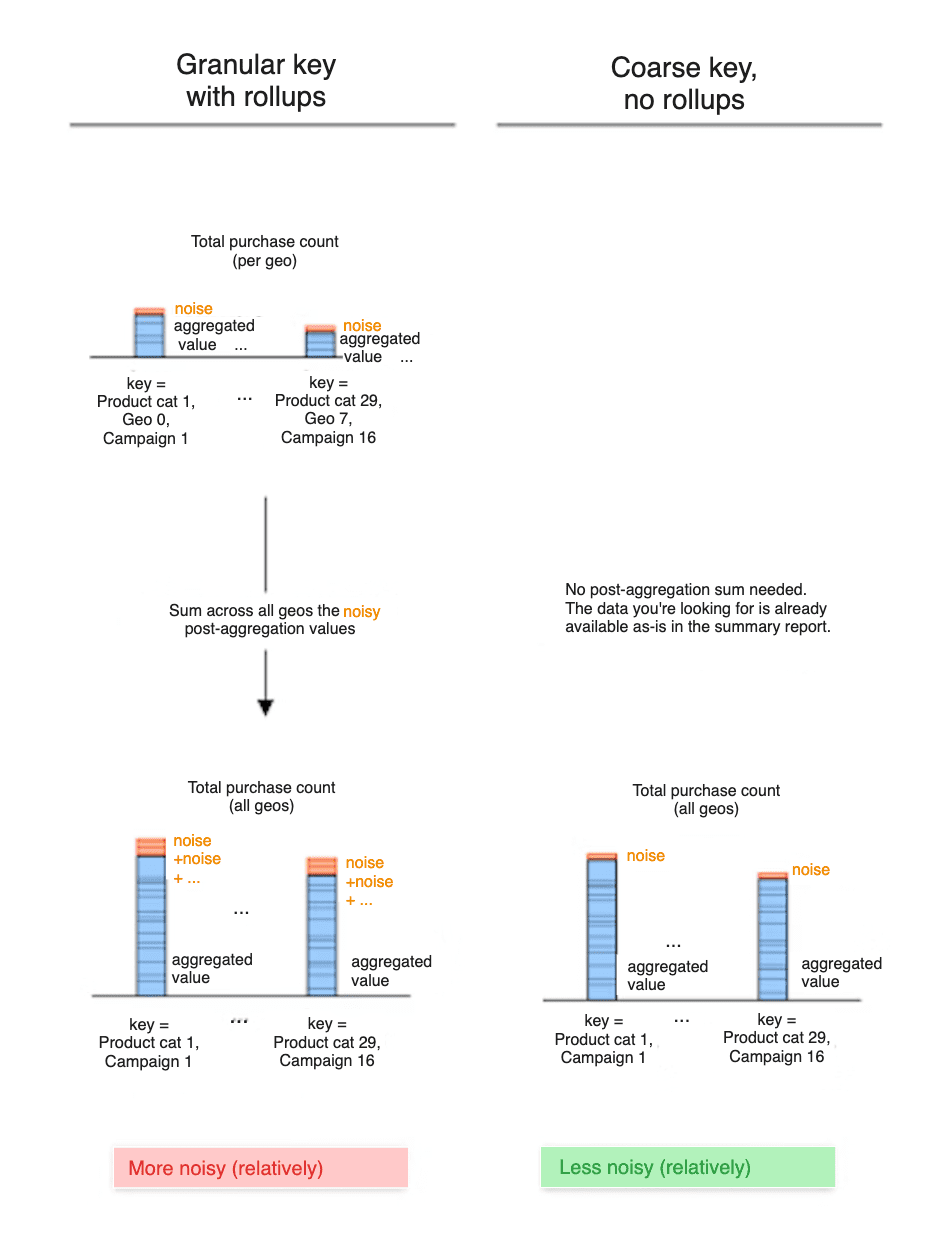
2 つの異なるアプローチを見てみましょう。 - アプローチ A: 鍵に地域 ID を含めます。概要レポートでは、地域 ID レベルのキーが公開され、各キーは特定の地域 ID レベルで概要の購入値と関連付けられています。 - アプローチ B: 鍵に地域 ID を含めない。概要レポートでは、すべての地域 ID と地域に関する購入の概要が直接表示されます。
国別の購入額を確認する方法は次のとおりです。 - 方法 A では、geo-ID レベルのサマリー値を合計するため、そのノイズも合計します。そのため、最終的な geo-ID レベルの購入額にノイズが追加される可能性があります。 - アプローチ B では、概要レポートで公開されているデータを直接確認します。ノイズがそのデータに追加されたのは 1 回だけです。
そのため、特定の地域 ID に対するサマリーの購入額は、アプローチ A のほうがノイズが多くなる可能性があります。
同様に、郵便番号レベルのディメンションをキーに含めると、地域レベルのディメンションで大まかなキーを使用するよりも、ノイズの多い結果が生じる可能性があります。
長期間にわたって集計することで、信号対雑音比が増加
概要レポートをリクエストする頻度が少ないと、レポートを頻繁にリクエストした場合よりも各概要の値が大きくなる可能性があります。より長い時間枠でコンバージョンが増える可能性が高い。
前述のように、サマリー値が高いほど、相対的なノイズは低い可能性が高くなります。そのため、概要レポートをリクエストする頻度を減らすと、SN 比が(向上)します。
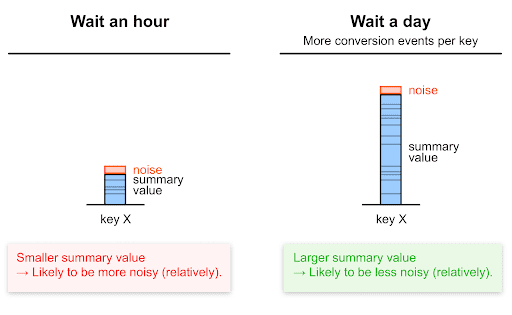
次に例を示します。
- 24 時間分の時間別サマリー レポートをリクエストし、各時間別レポートの概要値を合計して日単位のデータにアクセスする場合、ノイズが 24 回追加されます。
- 日次サマリー レポートでノイズが追加されるのは 1 回のみです。
イプシロンを大きくし、ノイズを小さくする
イプシロンの値が大きいほど、ノイズが小さくなり、プライバシー保護の強度が低くなります。
フィルタリングと重複除去を活用する
異なるキー間で予算を割り当てる際に重要なのは、特定のイベントが発生する可能性がある回数を把握することです。たとえば、クリック 1 回につき購入は 1 回のみであっても、「商品ページの閲覧」は 3 回までは関心がある場合がありますできます。このようなユースケースに対応するには、次の API 機能を利用して、生成されるレポートの数とカウントされるコンバージョンを制御することをおすすめします。
- フィルタ。フィルタリングの詳細
- 重複除去。重複除去の詳細を確認する。
イプシロンのテスト
広告テクノロジーは、イプシロンを 0 より大きく 64 以下の値に設定できます。この範囲により柔軟なテストが可能になります。イプシロンの値を小さくすると、プライバシー保護が強化されます。epsilon=10 から始めることをおすすめします。
テストの推奨事項
次のことをおすすめします。 - イプシロン = 10 から始めます。 - これによって顕著なユーティリティの問題が発生する場合は、イプシロンを段階的に増やします。 - データのユーザビリティに関して見つけた特定の転換点について、フィードバックを共有してください。
Engage and share feedback
You can participate and experiment with this API.
- Read about aggregatable reports and the aggregation service, ask questions, and suggest feedback.
- Read the Attribution reporting guides.
- Ask questions and join discussions on the Privacy Sandbox Developer Support repo.
次のステップ
- キャンペーン変数、バッチ処理頻度、ディメンションの粒度など、レポートに影響する要素について詳しくは、概要レポートの設計上の決定事項をテストするをご覧ください。
- ノイズラボを試す。