Aggregation Service genera report di riepilogo di dati dettagliati sulle conversioni e misurazioni della copertura da report aggregabili non elaborati. I tecnici pubblicitari hanno due principali punti di ingresso aggregati sul lato client per generare report sulla canalizzazione al servizio di aggregazione, tramite l'API Attribution Reporting o l'API Private Aggregation.
Stato dell'implementazione
- Il servizio di aggregazione è ora stato spostato alla disponibilità generale.
- Il servizio di aggregazione può essere utilizzato con l'API Attribution Reporting e l'API Private Aggregation per l'API Protected Audience e l'API Shared Storage.
Disponibilità
| Proposal | Status |
|---|---|
| Aggregation Service support for Amazon Web Services (AWS) across Attribution Reporting API, Private Aggregation API
Explainer |
Available |
| Aggregation Service support for Google Cloud across Attribution Reporting API, Private Aggregation API Explainer |
Available |
| Aggregation Service site enrollment and multi-origin aggregation. Site enrollment includes mapping of a site to cloud accounts (AWS, or GCP). To aggregate multiple origins, they must be of the same site.
FAQs on GitHub Site aggregation API documentation |
Available |
| The Aggregation Service's epsilon value will be kept as a range of up to 64, to facilitate experimentation and feedback on different parameters.
Submit ARA epsilon feedback. Submit PAA epsilon feedback. |
Available. We will provide advanced notice to the ecosystem before the epsilon range values are updated. |
| More flexible contribution filtering for Aggregation Service queries
Explainer |
Available |
| Process for budget recovery post-disasters (errors, misconfigurations, and so on)
Explainer |
Available Mechanism to review the percentage of shared IDs recovered by an ad tech using budget recovery and suspend future recoveries for excessive recoveries planned for H1 2025 |
| Accenture operating as one of the Coordinators on AWS
Developer Blog |
Available |
| Independent party operating as one of the Coordinators on Google Cloud
Developer blog |
Available |
| Aggregation Service support for Aggregate Debug Reporting on Attribution Reporting API
Explainer |
Available |
Termini e concetti chiave
Se stai valutando la possibilità di utilizzare il servizio di aggregazione nel tuo flusso di lavoro ad tech, i seguenti termini e concetti dovrebbero fornirti ulteriori informazioni su cosa può offrire questo nuovo flusso di aggregazione al tuo team:
| Term | Description |
|---|---|
| Aggregation Service | An ad tech-operated service that processes aggregatable reports to create a summary report. |
| Aggregatable Reports |
I report aggregati sono report criptati inviati dai dispositivi dei singoli utenti. Questi report contengono dati sul comportamento degli utenti tra siti e sulle conversioni. Le conversioni (a volte chiamate eventi di attivazione dell'attribuzione) e le metriche associate sono definite dall'inserzionista o dalla tecnologia pubblicitaria. Ogni report è criptato per impedire a varie parti di accedere ai dati sottostanti. Learn more about aggregatable reports. |
| Aggregatable Report Accounting | A distributed ledger located in both coordinators that tracks allocated privacy budget and enforces the 'No Duplicates' rule. This is the privacy preserving mechanism, located and run within coordinators, that ensures that no report passes through Aggregation Service beyond the allocated privacy budget. Read more on batching strategies on how it relates to aggregatable reports. |
| Aggregatable Report Accounting Budget | References to the budget that ensures reports are not processed more than once. |
| Trusted Execution Environment (TEE) |
A trusted execution environment is a special configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the computer. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less. To learn more about TEEs used for the Privacy Sandbox proposals, read the Protected Audience API services explainer and the Aggregation Service explainer. |
| Coordinators |
Un coordinatore è un'entità responsabile della gestione delle chiavi e della contabilità dei report aggregabili. Il coordinatore gestisce un elenco di hash delle configurazioni dei servizi di aggregazione approvate e configura l'accesso alle chiavi di decriptazione. |
| Shared ID |
Computed value that consists of: shared_info, reporting_origin, destination_site (available for Attribution Reporting API only), source_registration-time (available for Attribution Reporting API only), scheduled_report_time, version.
This means that multiple reports belong to the same shared ID should they share the same attributes of the shared_info field. This plays an important role within Aggregatable Report Accounting.
Read more about Trusted Servers.
|
| Summary Report |
A summary report is an Attribution Reporting API and Private Aggregation API report type. A summary report includes aggregated user data and can contain detailed conversion data, with noise added. Summary reports are made up of aggregate reports. Summary reports allow for greater flexibility and a richer data model than event-level reporting, particularly for some use-cases like conversion values. |
| Reporting Origin |
L'origine segnalante è l'entità che riceve report aggregabili, ovvero l'API Attribution Reporting. I report aggregabili vengono inviati dai dispositivi degli utenti a un URL noto associato all'origine dei report. Questa origine di segnalazione deve essere designata durante la registrazione. |
| Contribution Bonding | Aggregatable reports may contain an arbitrary number of counter increments. For example, a report may contain a count of products that a user has viewed on an advertiser's site. The sum of increments in all aggregatable reports related to a single source event must not exceed a given limit, `L1=2^16`. Learn more in the aggregatable reports explainer. |
| Noise & Scaling | A certain amount of statistical noise is added to summary reports as a part of the aggregation process that also functions to preserve privacy and ensure the final reports provide anonymized measurement information. Read more about additive noise mechanism, which is drawn from Laplace distribution. |
| Attestation |
L'attestazione è un meccanismo per autenticare l'identità del software, in genere con hash di crittografia o firme. Per la proposta del servizio di aggregazione, l'attestazione abbina il codice in esecuzione nel servizio di aggregazione gestito dalla tecnologia pubblicitaria al codice open source. Read more about attestation. |
Scopri di più sulla storia del Servizio di aggregazione nel nostro articolo esplicativo e nell'elenco completo dei termini.
Casi d'uso di aggregazione
Considera i seguenti percorsi per gli sviluppatori per la misurazione degli annunci e le relative librerie client di misurazione.
| Caso d'uso | Punto di ingresso | Descrizione |
|---|---|---|
| Ottimizzazione dell'offerta | API Attribution Reporting (Chrome e Android) | Utilizza i report aggregati per importare gli indicatori di conversione a fini di ottimizzazione delle offerte. |
| Misurazione multipiattaforma | API Attribution Reporting (Chrome e Android) | Utilizza le funzionalità di misurazione su più piattaforme web e app per avere visibilità sul rendimento su Chrome e Android. |
| Report sulle conversioni | API Attribution Reporting (Chrome e Android) | Creare report sulle conversioni aggregati e personalizzati in base alle esigenze delle campagne dei clienti (incluse le conversioni CTC e le conversioni view-through). |
| Misurazione della copertura della campagna | API Shared Storage e API Private Aggregation (Chrome) | Utilizza le variabili di visualizzazione dell'annuncio cross-site per misurare la copertura della campagna. |
| Report sulle categorie demografiche | API Shared Storage e API Private Aggregation (Chrome) | Utilizza la visualizzazione degli annunci in più siti e i dati demografici per misurare la copertura in base ai gruppi demografici. |
| Analisi del percorso di conversione | API Shared Storage e API Private Aggregation (Chrome) | Memorizza le visualizzazioni di annunci e le variabili di conversione cross-site per eseguire l'analisi aggregata del percorso di conversione. |
| Impatto del brand e sulle conversioni | API Shared Storage e API Private Aggregation (Chrome) | Report sui gruppi di test/controllo e informazioni sui sondaggi per misurare l'impatto del brand e l'incrementalità. |
| Debug dell'asta | API Protected Audience e API Private Aggregation (Chrome) | Utilizza report aggregati per il debug. |
| Distribuzione delle offerte | API Protected Audience e API Private Aggregation (Chrome) | Utilizza i report aggregati per acquisire la distribuzione dei valori di offerta per le aste. |
Flusso end-to-end
Il seguente diagramma mostra il servizio di aggregazione in azione. Ci concentreremo sul flusso end-to-end, dalla ricezione dei report dal web e dai dispositivi mobili alla creazione dei report di riepilogo nei servizi di aggregazione.
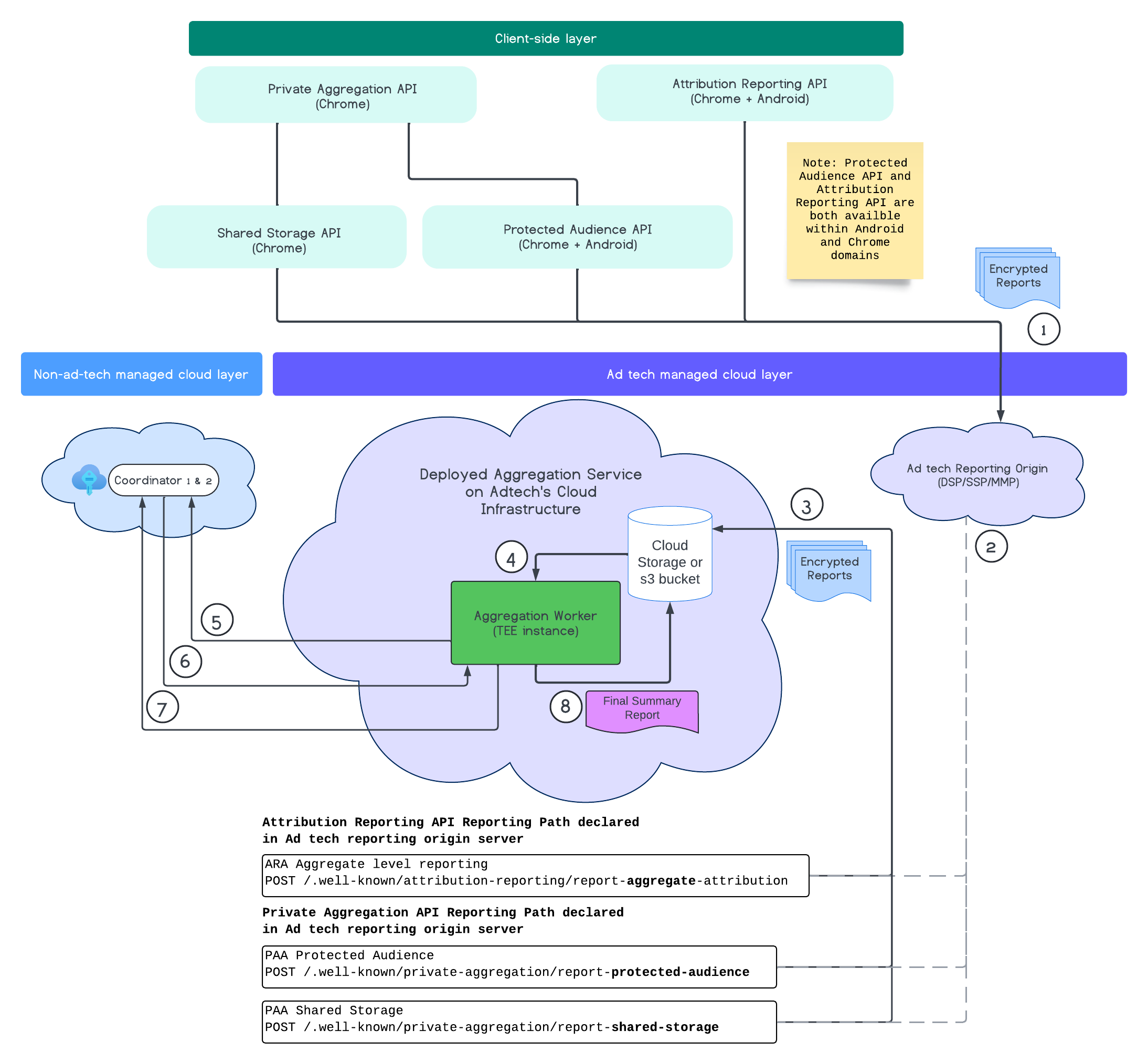
- Recupera la chiave pubblica per generare report criptati.
- Report aggregabili criptati inviati ai server di ad tech per essere raccolti, trasformati e raggruppati.
- Il server ad tech raggruppa in batch i report (in formato avro) e li invia al servizio di aggregazione di cui è stato eseguito il deployment. (da compilare da parte della tecnologia pubblicitaria).
- Recupera i report aggregati da decriptare.
- Recupera le chiavi di decriptazione dai coordinatori.
- Il servizio di aggregazione decripta i report per l'aggregazione e l'aggiunta di rumore.
- Il servizio di contabilità dei report aggregabili controlla se è rimasto del budget per la privacy per generare un report di riepilogo per i report aggregabili specificati.
- Invia il report di riepilogo finale.
Dal diagramma puoi vedere la relazione complessiva del servizio di aggregazione con le API di misurazione dei clienti principali API Attribution Reporting, API Private Aggregation e i coordinatori.
Il flusso inizia con diverse API di misurazione, come l'API Attribution Reporting o l'API Private Aggregation che generano report da più istanze del browser. Chrome recupera la chiave pubblica dal servizio di hosting delle chiavi in Coordinator per criptare i report prima che vengano inviati all'origine report dell'ad tech. Le chiavi pubbliche vengono ruotate ogni sette giorni.
Una volta che l'origine report della tecnologia pubblicitaria riceve questi report, deve essere configurata per raccogliere e convertirli in formato avro e inviarli all'istanza del servizio di aggregazione di cui è stato eseguito il deployment. Consulta le strategie di raggruppamento.
Quando la tecnologia pubblicitaria è pronta per il batch, crea una richiesta batch al servizio di aggregazione, dove i report vengono decriptati mediante il recupero delle chiavi di decrittografia dal servizio di hosting delle chiavi, aggregate e con rumore in più per creare un report di riepilogo. Tieni presente che ciò dipende dal fatto che il budget per la privacy sia sufficiente per generare i report di riepilogo finali.
L'endpoint di origine report della tecnologia pubblicitaria in cui vengono raccolti i report è ospitato dalla tecnologia pubblicitaria e il servizio di aggregazione viene implementato nel cloud della tecnologia pubblicitaria.
Raggruppamento dei report aggregati
Il flusso di reporting non sarebbe completo senza l'aiuto del server di origine della segnalazione designato. Si tratta dell'origine che un ad tech avrebbe inviato durante la procedura di registrazione. Le azioni principali di cui è responsabile l'origine segnalante consisteranno nel raccogliere, trasformare e raggruppare i report aggregabili ricevuti e prepararli per l'invio al servizio di aggregazione di cui è stato eseguito il deployment in Google Cloud o Amazon Web Services. Scopri di più su come preparare i report aggregabili.
Ora che conosci il concetto generale, dai un'occhiata più da vicino ai componenti di cui verrà eseguito il deployment nel tuo servizio di aggregazione.
Componenti cloud
Il servizio di aggregazione è costituito da vari componenti di servizi cloud. Esegui il provisioning degli script Terraform forniti e configura tutti i componenti del servizio cloud necessari.
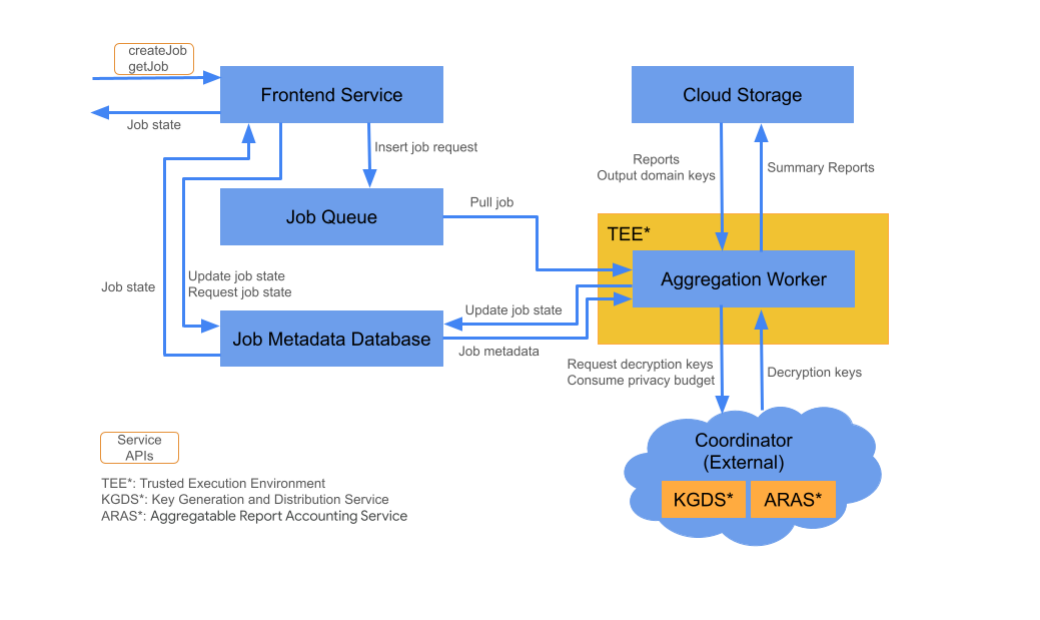
Servizio frontend
Servizio Cloud gestito: funzione Cloud Functions (Google Cloud) / API Gateway (Amazon Web Services)
Il servizio frontend è un gateway serverless che funge da punto di contatto per le chiamate all'API Aggregation per la creazione e il recupero dello stato dei job. È responsabile della ricezione delle richieste dagli utenti del servizio di aggregazione, della convalida dei parametri di input e dell'avvio del processo di pianificazione del job di aggregazione.
Nel servizio frontend sono disponibili due API:
| Endpoint | Descrizione |
|---|---|
createJob |
Questa API attiva un job del Servizio di aggregazione. Richiede informazioni per attivare un job, come l'ID job, l'input dei dettagli di archiviazione, i dettagli dello spazio di archiviazione di output, l'origine dei report e altro ancora. |
getJob |
Questa API restituisce lo stato di un job per un ID job specificato. Fornisce informazioni sullo stato del job, ad esempio "Ricevuto", "In corso" o "Terminato". Inoltre, se il job viene completato, viene visualizzato il risultato del job, inclusi eventuali messaggi di errore riscontrati durante l'esecuzione del job. |
Consulta la documentazione dell'API Service Aggregation.
Coda di job
Servizi Cloud gestiti: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
La coda di job è una coda di messaggi che memorizza le richieste di job per il servizio di aggregazione. Il servizio frontend inserisce nella coda i messaggi di richiesta di job, che vengono poi utilizzati dall'Aggregation Worker per elaborare la richiesta di job.
Cloud Storage
Servizio cloud gestito: Google Cloud Storage (Google Cloud)/Amazon S3 (Amazon Web Services) Cloud Storage viene utilizzato per archiviare i file di input e di output utilizzati dal servizio di aggregazione (ad es. file di report criptati, report di riepilogo dell'output e così via).
Database metadati job
Servizio Cloud gestito: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
Il database dei metadati dei job archivia e monitora lo stato dei job di aggregazione. Il database registra metadati come data e ora di creazione, data e ora di richiesta, data e ora di aggiornamento e stato (ad es. Ricevuto, In corso, Completato e così via). Il Worker di aggregazione aggiorna il database dei metadati del job man mano che il job procede.
Worker aggregazione
Servizio cloud gestito: Compute Engine con spazio riservato (Google Cloud)/Amazon Web Services EC2 con Nitro Enclave (Amazon Web Services)
Il worker di aggregazione elabora le richieste di job avviate da una richiesta di job nella coda dei job, decriptando gli input criptati utilizzando le chiavi recuperate da Key Generation and Distribution Service (KGDS) in Coordinators. Per ridurre al minimo la latenza di elaborazione dei job, le chiavi di decrittografia vengono memorizzate nella cache in Aggregation Worker per un periodo di 8 ore, utilizzabili tra i job elaborati dall'istanza worker in questione.
Il worker opera all'interno di un'istanza Trusted Execution Environment (TEE). Ogni worker gestisce un solo job alla volta. La tecnologia pubblicitaria può configurare più worker per elaborare i job in parallelo impostando la configurazione della scalabilità automatica. Tramite la scalabilità automatica, il numero di worker viene regolato dinamicamente in base al numero di messaggi restanti nella coda dei job. Il numero minimo e massimo di worker per la scalabilità automatica possono essere configurati tramite il file di ambiente Terraform. Ulteriori informazioni sulla scalabilità automatica sono disponibili nei seguenti script Terraform. [Amazon Web Services / Google Cloud]
Il worker di aggregazione chiama il servizio Aggregatable Report Accounting per la contabilità dei report aggregabili. Il servizio di contabilità per report aggregabili garantirà che i job vengano eseguiti solo a condizione che non abbia ancora superato il limite di budget per la privacy. (Vedi la regola "Nessun duplicato"). Se il budget è disponibile, viene generato un report di riepilogo utilizzando i dati aggregati sul rumore. Leggi ulteriori informazioni sulla conteatura dei report aggregabili.
Il worker di aggregazione aggiorna i metadati del job nel database dei metadati dei job, inclusi i codici di ritorno appropriati dei job e i contatori degli errori dei report in caso di errori dei report parziali. Gli utenti possono recuperare lo stato utilizzando l'API Job State Retrieval (getJob).
Per una descrizione più dettagliata del servizio di aggregazione, consulta il nostro spiegatore.
Passaggi successivi
Ora che conosci le caratteristiche principali di Aggregation Service, è il momento di eseguire il deployment della tua istanza tramite Google Cloud o Amazon Web Services. Consulta la sezione Per iniziare. Se invece hai bisogno di maggiori informazioni su come gestire un servizio di aggregazione di cui è stato eseguito il deployment, segui questo link per scoprire di più su come operare il servizio di aggregazione.
Risoluzione dei problemi
Per descrizioni più dettagliate dei messaggi di errore, di cosa potrebbe aver causato l'errore riscontrato e dei passaggi successivi per la mitigazione, consulta il documento Codici di errore e mitigazioni comuni.
Ricevere assistenza e fornire feedback
- Per problemi tecnici, domande sul prodotto, feedback e richieste di funzionalità, crea un problema nel nostro repository GitHub.
- Per domande in cui devi fornire informazioni sensibili o proprietarie per la risoluzione dei problemi, scrivi all'indirizzo aggregation-service-support@google.com
- Controlla la Public Status Dashboard per conoscere i problemi noti.