บริการรวบรวมข้อมูลจะสร้างรายงานสรุปของข้อมูล Conversion แบบละเอียดและการวัดการเข้าถึงจากรายงานดิบแบบรวมได้ เทคโนโลยีโฆษณามีจุดแรกเข้าแบบรวมข้อมูลหลัก 2 จุดฝั่งไคลเอ็นต์เพื่อส่งรายงานไปยังบริการรวบรวมข้อมูลผ่าน Attribution Reporting API หรือ Private Aggregation API
สถานะการติดตั้งใช้งาน
- บริการรวบรวมข้อมูลพร้อมให้บริการแก่ผู้ใช้ทั่วไปแล้ว
- บริการรวบรวมข้อมูลใช้ได้กับ Attribution Reporting API และ Private Aggregation API สําหรับ Protected Audience API และ Shared Storage API
ความพร้อมใช้งาน
| ข้อเสนอ | สถานะ |
|---|---|
| ผู้ประสานงานข้ามระบบคลาวด์แบบเต็มรูปแบบ (ทั้งบริการโฮสติ้งคีย์แบบหลายฝ่ายและบริการงบประมาณด้านความเป็นส่วนตัว) | ครึ่งหลังปี 2025 |
| บริการงบประมาณด้านความเป็นส่วนตัวข้ามระบบคลาวด์
คำอธิบาย |
ใช้งานได้ |
| การรองรับบริการรวบรวมข้อมูลสําหรับ Amazon Web Services (AWS) ใน Attribution Reporting API และ Private Aggregation API
คําอธิบาย |
ใช้งานได้ |
| การรองรับบริการรวบรวมข้อมูลสําหรับ Google Cloud ใน Attribution Reporting API, Private Aggregation API คําอธิบาย |
ใช้งานได้ |
| การลงทะเบียนเว็บไซต์บริการรวมข้อมูลและการรวมข้อมูลจากหลายแหล่งที่มา การลงทะเบียนเว็บไซต์รวมถึงการแมปเว็บไซต์กับบัญชีระบบคลาวด์ (AWS หรือ GCP) หากต้องการรวบรวมแหล่งที่มาหลายแห่ง แหล่งที่มาเหล่านั้นต้องเป็นของเว็บไซต์เดียวกัน
คําถามที่พบบ่อยใน GitHub เอกสารประกอบของ Site Aggregation API |
ใช้งานได้ |
| ระบบจะเก็บค่า epsilon ของบริการรวบรวมข้อมูลไว้เป็นช่วงสูงสุด 64 เพื่ออำนวยความสะดวกในการทดสอบและแสดงความคิดเห็นเกี่ยวกับพารามิเตอร์ต่างๆ
ส่งความคิดเห็นเกี่ยวกับ ARA epsilon ส่งความคิดเห็นเกี่ยวกับ PAA epsilon |
มีให้บริการ เราจะแจ้งให้ระบบนิเวศทราบล่วงหน้าก่อนที่จะอัปเดตค่าช่วง epsilon |
| การกรองข้อมูลที่ส่งเข้ามามีความยืดหยุ่นมากขึ้นสําหรับการค้นหาบริการรวมข้อมูล
คําอธิบาย |
ใช้งานได้ |
| กระบวนการกู้คืนงบประมาณหลังเกิดภัยพิบัติ (ข้อผิดพลาด การกำหนดค่าที่ไม่ถูกต้อง และอื่นๆ)
คำอธิบาย |
พร้อมใช้งาน กลไกในการตรวจสอบเปอร์เซ็นต์ของรหัสที่แชร์ซึ่งเทคโนโลยีโฆษณากู้คืนโดยใช้การกู้คืนงบประมาณและระงับการกู้คืนในอนาคตสำหรับการกู้คืนที่มากเกินไปซึ่งวางแผนไว้สำหรับครึ่งปีแรก 2025 |
| Accenture ดําเนินการในฐานะผู้ประสานงานรายหนึ่งใน AWS
บล็อกนักพัฒนาซอฟต์แวร์ |
ใช้งานได้ |
| บุคคลภายนอกที่ทำงานเป็นผู้ประสานงานใน Google Cloud
บล็อกนักพัฒนาซอฟต์แวร์ |
ใช้งานได้ |
| การรองรับบริการรวมข้อมูลสําหรับการรายงานการแก้ไขข้อบกพร่องแบบรวมใน Attribution Reporting API
คําอธิบาย |
ใช้งานได้ |
คําศัพท์และแนวคิดสําคัญ
หากคุณกำลังพิจารณาที่จะใช้บริการรวบรวมข้อมูลในเวิร์กโฟลว์เทคโนโลยีโฆษณา คำศัพท์และแนวคิดต่อไปนี้จะช่วยให้คุณทราบข้อมูลเพิ่มเติมเกี่ยวกับสิ่งที่เวิร์กโฟลว์การรวบรวมข้อมูลแบบใหม่นี้มอบให้ทีมของคุณได้
| Term | Description |
|---|---|
| Aggregation Service | An ad tech-operated service that processes aggregatable reports to create a summary report. |
| Aggregatable Reports |
รายงานที่รวบรวมได้คือรายงานที่เข้ารหัสซึ่งส่งจากอุปกรณ์ของผู้ใช้แต่ละเครื่อง รายงานเหล่านี้มีข้อมูลเกี่ยวกับพฤติกรรมของผู้ใช้ข้ามเว็บไซต์และ Conversion Conversion (บางครั้งเรียกว่าเหตุการณ์การระบุแหล่งที่มา) และเมตริกที่เกี่ยวข้องจะกำหนดโดยผู้ลงโฆษณาหรือเทคโนโลยีโฆษณา รายงานแต่ละฉบับจะได้รับการเข้ารหัสเพื่อป้องกันไม่ให้ฝ่ายต่างๆ เข้าถึงข้อมูลที่สําคัญ Learn more about aggregatable reports. |
| Aggregatable Report Accounting | A distributed ledger located in both coordinators that tracks allocated privacy budget and enforces the 'No Duplicates' rule. This is the privacy preserving mechanism, located and run within coordinators, that ensures that no report passes through Aggregation Service beyond the allocated privacy budget. Read more on batching strategies on how it relates to aggregatable reports. |
| Aggregatable Report Accounting Budget | References to the budget that ensures reports are not processed more than once. |
| Trusted Execution Environment (TEE) |
A trusted execution environment is a special configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the computer. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less. To learn more about TEEs used for the Privacy Sandbox proposals, read the Protected Audience API services explainer and the Aggregation Service explainer. |
| Coordinators |
A coordinator is an entity responsible for key management and aggregatable report accounting. The coordinator maintains a list of hashes of approved aggregation service configurations and configures access to decryption keys. |
| Shared ID |
Computed value that consists of: shared_info, reporting_origin, destination_site (available for Attribution Reporting API only), source_registration-time (available for Attribution Reporting API only), scheduled_report_time, version.
This means that multiple reports belong to the same shared ID should they share the same attributes of the shared_info field. This plays an important role within Aggregatable Report Accounting.
Read more about Trusted Servers.
|
| Summary Report |
A summary report is an Attribution Reporting API and Private Aggregation API report type. A summary report includes aggregated user data and can contain detailed conversion data, with noise added. Summary reports are made up of aggregate reports. Summary reports allow for greater flexibility and a richer data model than event-level reporting, particularly for some use-cases like conversion values. |
| Reporting Origin |
The reporting origin is the entity that receives aggregatable reports—in other words, the ad tech that called the Attribution Reporting API. Aggregatable reports are sent from user devices to a well-known URL associated with the reporting origin. This reporting origin should be designated during enrollment. |
| Contribution Bonding | Aggregatable reports may contain an arbitrary number of counter increments. For example, a report may contain a count of products that a user has viewed on an advertiser's site. The sum of increments in all aggregatable reports related to a single source event must not exceed a given limit, `L1=2^16`. Learn more in the aggregatable reports explainer. |
| Noise & Scaling | A certain amount of statistical noise is added to summary reports as a part of the aggregation process that also functions to preserve privacy and ensure the final reports provide anonymized measurement information. Read more about additive noise mechanism, which is drawn from Laplace distribution. |
| Attestation |
Attestation is a mechanism to authenticate software identity, usually with cryptographic hashes or signatures. For the aggregation service proposal, attestation matches the code running in the ad tech-operated aggregation service with the open source code. Read more about attestation. |
อ่านข้อมูลเพิ่มเติมเกี่ยวกับเบื้องหลังของบริการรวบรวมข้อมูลได้ในคำอธิบายและรายการข้อกำหนดฉบับเต็ม
Use Case การรวมข้อมูล
พิจารณาเส้นทางของนักพัฒนาซอฟต์แวร์ต่อไปนี้สําหรับการวัดโฆษณาและไลบรารีไคลเอ็นต์การวัดที่สอดคล้องกัน
| กรณีการใช้งาน | จุดแรกเข้า | คำอธิบาย |
|---|---|---|
| การเพิ่มประสิทธิภาพการเสนอราคา | Attribution Reporting API (Chrome และ Android) | ใช้รายงานแบบรวมเพื่อส่งผ่านสัญญาณ Conversion เพื่อวัตถุประสงค์ในการเพิ่มประสิทธิภาพการเสนอราคา |
| การวัดผลข้ามแพลตฟอร์ม | Attribution Reporting API (Chrome และ Android) | ใช้ความสามารถในการวัดผลในเว็บและแอปต่างๆ เพื่อดูประสิทธิภาพใน Chrome และ Android |
| การรายงาน Conversion | Attribution Reporting API (Chrome และ Android) | สร้างการรายงาน Conversion แบบรวมที่ปรับให้เหมาะกับความต้องการแคมเปญของลูกค้า (รวมถึง CTC และ VTC) |
| การวัดการเข้าถึงแคมเปญ | Shared Storage API และ Private Aggregation API (Chrome) | ใช้ตัวแปรการแสดงโฆษณาข้ามเว็บไซต์เพื่อวัดการเข้าถึงของแคมเปญ |
| การรายงานข้อมูลประชากร | Shared Storage API และ Private Aggregation API (Chrome) | ใช้การแสดงโฆษณาข้ามเว็บไซต์และข้อมูลประชากรเพื่อวัดการเข้าถึงตามข้อมูลประชากร |
| การวิเคราะห์เส้นทาง Conversion | Shared Storage API และ Private Aggregation API (Chrome) | จัดเก็บการแสดงโฆษณาข้ามเว็บไซต์และตัวแปร Conversion เพื่อทําการวิเคราะห์เส้นทาง Conversion แบบรวม |
| Brand Lift และ Conversion Lift | Shared Storage API และ Private Aggregation API (Chrome) | การรายงานเกี่ยวกับกลุ่มทดสอบ/กลุ่มควบคุมและข้อมูลการสำรวจเพื่อวัด Brand Lift และส่วนเพิ่ม |
| การแก้ไขข้อบกพร่องของการประมูล | Protected Audience API และ Private Aggregation API (Chrome) | ใช้รายงานแบบรวมเพื่อแก้ไขข้อบกพร่อง |
| การกระจายราคาเสนอ | Protected Audience API และ Private Aggregation API (Chrome) | ใช้รายงานแบบรวมเพื่อบันทึกการแจกแจงมูลค่าการเสนอราคาสำหรับการประมูล |
ขั้นตอนจากต้นทางถึงปลายทาง
แผนภาพต่อไปนี้แสดงการทํางานของบริการรวบรวมข้อมูล เราจะมุ่งเน้นที่ขั้นตอนตั้งแต่ต้นจนจบ ตั้งแต่การรับรายงานจากเว็บและอุปกรณ์เคลื่อนที่ไปจนถึงการสร้างรายงานสรุปในบริการรวบรวมข้อมูล
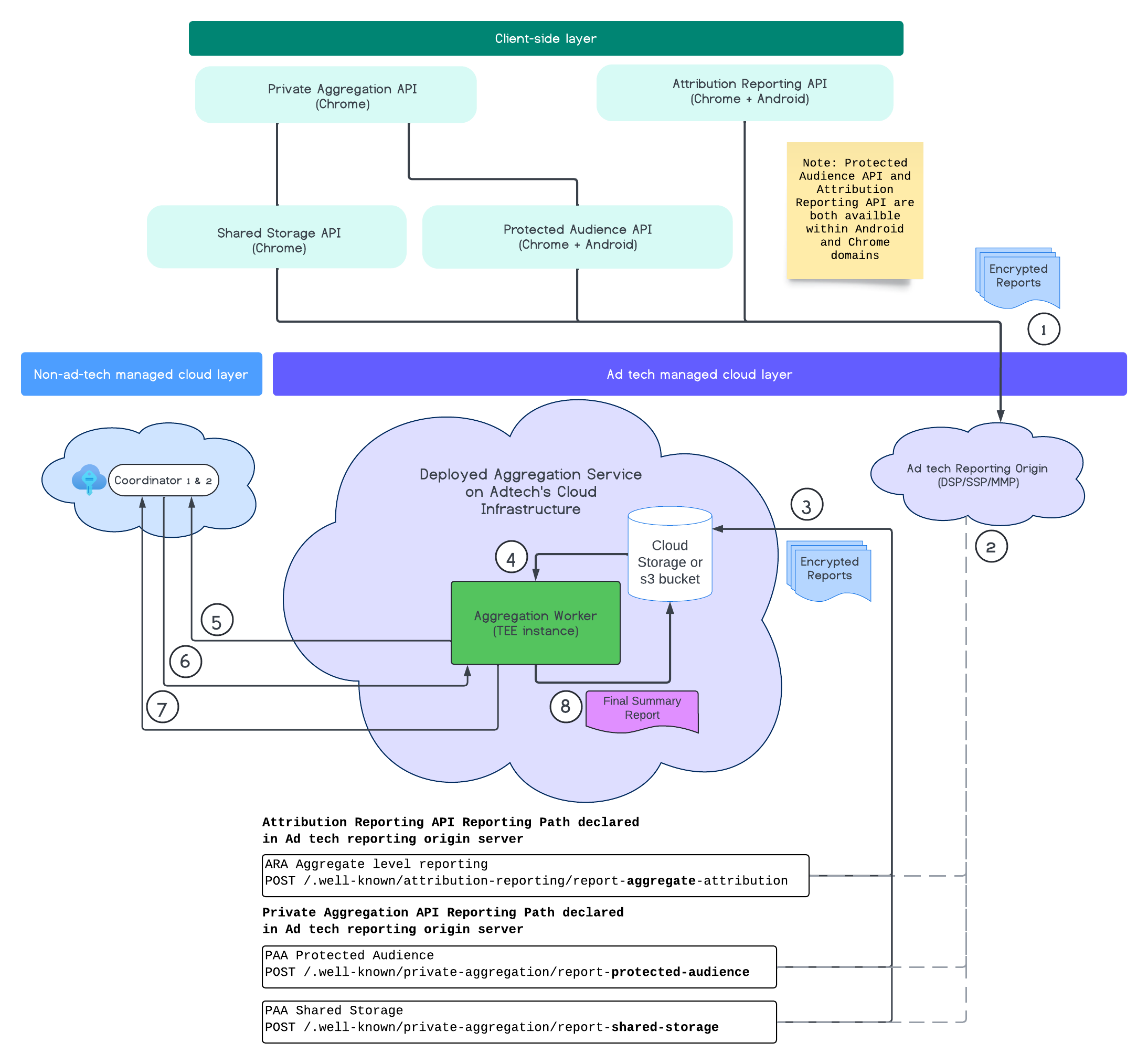
- ดึงข้อมูลคีย์สาธารณะเพื่อสร้างรายงานที่เข้ารหัส
- รายงานที่เข้ารหัสซึ่งรวบรวมได้ซึ่งส่งไปยังเซิร์ฟเวอร์เทคโนโลยีโฆษณาเพื่อรวบรวม เปลี่ยนรูปแบบ และจัดกลุ่ม
- เซิร์ฟเวอร์เทคโนโลยีโฆษณาจะจัดกลุ่มรายงาน (รูปแบบ avro) และส่งไปยังบริการรวบรวมข้อมูลที่ติดตั้งใช้งาน (ต้องดำเนินการโดยเทคโนโลยีโฆษณา)
- เรียกข้อมูลรายงานรวมเพื่อถอดรหัส
- เรียกข้อมูลคีย์การถอดรหัสจากผู้ประสานงาน
- บริการรวมข้อมูลจะถอดรหัสรายงานเพื่อรวบรวมข้อมูลและสร้างสัญญาณรบกวน
- บริการบัญชีของรายงานที่รวบรวมได้จะตรวจสอบว่ายังมีงบประมาณความเป็นส่วนตัวเหลืออยู่หรือไม่เพื่อสร้างรายงานสรุปสําหรับรายงานที่รวบรวมได้
- ส่งรายงานสรุปขั้นสุดท้าย
จากแผนภาพนี้ คุณจะเห็นว่าบริการรวบรวมข้อมูลมีความสัมพันธ์โดยรวมอย่างไรกับ API การวัดผลไคลเอ็นต์หลักอย่าง Attribution Reporting API, Private Aggregation API และผู้ประสานงาน
ขั้นตอนเริ่มต้นด้วย Measurement API ต่างๆ เช่น Attribution Reporting API หรือ Private Aggregation API ที่สร้างรายงานจากอินสแตนซ์เบราว์เซอร์หลายรายการ Chrome จะนำคีย์สาธารณะจากบริการโฮสติ้งคีย์ใน Coordinator มาใช้เข้ารหัสรายงานก่อนที่จะส่งไปยังต้นทางการรายงานของเทคโนโลยีโฆษณา คีย์สาธารณะจะหมุนเวียนทุก 7 วัน
เมื่อแหล่งที่มาของการรายงานของเทคโนโลยีโฆษณาได้รับรายงานเหล่านี้แล้ว คุณควรกําหนดค่าแหล่งที่มาของการรายงานให้รวบรวมและแปลงรายงานเหล่านั้นเป็นรูปแบบ avro และส่งไปยังอินสแตนซ์บริการรวบรวมข้อมูลที่ติดตั้งใช้งาน ดูกลยุทธ์การรวม
เมื่อเทคโนโลยีโฆษณาพร้อมที่จะส่งเป็นกลุ่มแล้ว เทคโนโลยีโฆษณาจะสร้างคําขอแบบเป็นกลุ่มไปยังบริการรวบรวมข้อมูล ซึ่งจะถอดรหัสรายงานโดยการดึงคีย์การถอดรหัสจากบริการโฮสติ้งคีย์ และรวบรวมข้อมูลและสร้างความสับสนเพื่อสร้างรายงานสรุป โปรดทราบว่าการดำเนินการนี้ขึ้นอยู่กับว่างบประมาณความเป็นส่วนตัวเพียงพอที่จะสร้างรายงานสรุปขั้นสุดท้ายหรือไม่
ปลายทางแหล่งที่มาของการรายงานเทคโนโลยีโฆษณาที่รวบรวมรายงานจะโฮสต์โดยเทคโนโลยีโฆษณา และบริการรวบรวมข้อมูลจะติดตั้งใช้งานในระบบคลาวด์ของเทคโนโลยีโฆษณา
การรวมรายงานที่รวมได้
ขั้นตอนการรายงานจะไม่สมบูรณ์หากไม่มีความช่วยเหลือจากเซิร์ฟเวอร์ต้นทางการรายงานที่กําหนด นี่คือต้นทางที่เทคโนโลยีโฆษณาจะส่งในกระบวนการลงทะเบียน การดำเนินการหลักที่แหล่งที่มาของการรายงานมีหน้าที่รับผิดชอบคือรวบรวม เปลี่ยนรูปแบบ และจัดกลุ่มรายงานที่รวบรวมได้ และเตรียมรายงานดังกล่าวเพื่อส่งไปยังบริการรวบรวมข้อมูลของเทคโนโลยีโฆษณาที่ติดตั้งใช้งานใน Google Cloud หรือ Amazon Web Services อ่านเพิ่มเติมเกี่ยวกับวิธีเตรียมรายงานที่รวบรวมได้
เมื่อทราบแนวคิดทั่วไปแล้ว ให้ดูองค์ประกอบที่จะติดตั้งใช้งานในบริการรวบรวมข้อมูลอย่างละเอียด
คอมโพเนนต์ระบบคลาวด์
บริการรวบรวมข้อมูลประกอบด้วยคอมโพเนนต์บริการระบบคลาวด์ต่างๆ สคริปต์ Terraform ที่ระบุจะจัดสรรและกําหนดค่าคอมโพเนนต์บริการระบบคลาวด์ที่จําเป็นทั้งหมด
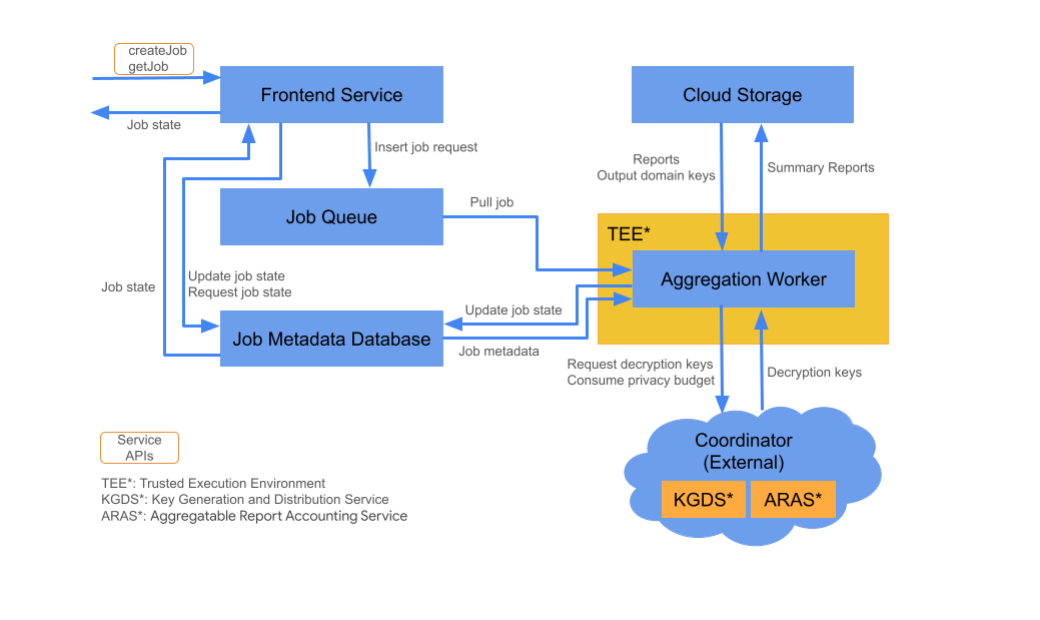
บริการ Frontend
บริการระบบคลาวด์ที่มีการจัดการ: Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
บริการส่วนหน้าคือเกตเวย์แบบ Serverless ที่ทำหน้าที่เป็นจุดแรกเข้าสำหรับการเรียก Aggregation API เพื่อสร้างงานและดึงข้อมูลสถานะงาน โดยมีหน้าที่รับผิดชอบในการรับคําขอจากผู้ใช้บริการรวบรวมข้อมูล ตรวจสอบพารามิเตอร์อินพุต และเริ่มกระบวนการกําหนดเวลาการทํางานของการเก็บรวบรวมข้อมูล
บริการฟรอนต์เอนด์มี API 2 รายการ ได้แก่
| ปลายทาง | คำอธิบาย |
|---|---|
createJob |
API นี้จะทริกเกอร์งานบริการรวมข้อมูล โดยต้องใช้ข้อมูลเพื่อทริกเกอร์งาน เช่น รหัสงาน รายละเอียดพื้นที่เก็บข้อมูลอินพุต รายละเอียดพื้นที่เก็บข้อมูลเอาต์พุต ต้นทางการรายงาน และอื่นๆ |
getJob |
API นี้จะแสดงสถานะของงานสำหรับรหัสงานที่ระบุ ซึ่งจะแสดงข้อมูลเกี่ยวกับสถานะของงาน เช่น "ได้รับแล้ว" "อยู่ระหว่างดำเนินการ" หรือ "เสร็จสิ้นแล้ว" นอกจากนี้ หากงานเสร็จสิ้นแล้ว ระบบจะแสดงผลลัพธ์ของงาน รวมถึงข้อความแสดงข้อผิดพลาดที่พบระหว่างการดำเนินการของงาน |
ดูเอกสารประกอบของ Aggregation Service API
คิวงาน
บริการระบบคลาวด์ที่มีการจัดการ: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
คิวงานคือคิวข้อความที่จัดเก็บคําของานสําหรับบริการรวบรวมข้อมูล บริการส่วนหน้าจะแทรกข้อความคําของานลงในคิว จากนั้น Aggregation Worker จะใช้ข้อความดังกล่าวเพื่อประมวลผลคําของาน
Cloud Storage
บริการระบบคลาวด์ที่มีการจัดการ: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services) ใช้พื้นที่เก็บข้อมูลระบบคลาวด์เพื่อจัดเก็บไฟล์อินพุตและเอาต์พุตที่บริการรวบรวมข้อมูลใช้ (เช่น ไฟล์รายงานที่เข้ารหัส รายงานสรุปเอาต์พุต ฯลฯ)
ฐานข้อมูลข้อมูลเมตาของงาน
บริการระบบคลาวด์ที่มีการจัดการ: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
ฐานข้อมูลข้อมูลเมตาของงานจะจัดเก็บและติดตามสถานะงานการรวม ฐานข้อมูลจะบันทึกข้อมูลเมตา เช่น เวลาสร้าง เวลาขอ เวลาอัปเดต และสถานะ (เช่น ได้รับ อยู่ระหว่างดำเนินการ เสร็จสิ้น ฯลฯ) Aggregation Worker จะอัปเดตฐานข้อมูลข้อมูลเมตาของงานเมื่องานดำเนินการ
ผู้ปฏิบัติงานการรวมข้อมูล
บริการระบบคลาวด์ที่มีการจัดการ: Compute Engine ที่มีพื้นที่เก็บข้อมูลลับ (Google Cloud) / Amazon Web Services EC2 ที่มี Nitro Enclave (Amazon Web Services)
ผู้ปฏิบัติงานการรวมจะประมวลผลคําของานซึ่งเริ่มต้นโดยคําของานในคิวงาน โดยถอดรหัสอินพุตที่เข้ารหัสโดยใช้คีย์ที่ดึงมาจากบริการสร้างและจัดจำหน่ายคีย์ (KGDS) ในผู้ประสานงาน ระบบจะแคชคีย์การถอดรหัสไว้ในผู้ปฏิบัติงานการรวมข้อมูลเป็นเวลา 8 ชั่วโมงเพื่อให้ใช้กับงานต่างๆ ที่ประมวลผลโดยอินสแตนซ์ผู้ปฏิบัติงานนั้นได้ เพื่อลดเวลาในการตอบสนองของการประมวลผลงาน
เวิร์กเกอร์จะทํางานภายในอินสแตนซ์ Trusted Execution Environment (TEE) ผู้ปฏิบัติงานแต่ละคนจะจัดการงานได้ครั้งละ 1 งานเท่านั้น เทคโนโลยีโฆษณาสามารถกําหนดค่าผู้ปฏิบัติงานหลายรายให้ประมวลผลงานพร้อมกันได้โดยการตั้งค่าการปรับขนาดอัตโนมัติ การปรับขนาดอัตโนมัติจะปรับจำนวนผู้ปฏิบัติงานตามจำนวนข้อความที่เหลืออยู่ในคิวงาน คุณสามารถกำหนดค่าจำนวนผู้ปฏิบัติงานขั้นต่ำและสูงสุดสำหรับการปรับขนาดอัตโนมัติผ่านไฟล์สภาพแวดล้อม Terraform ดูข้อมูลเพิ่มเติมเกี่ยวกับการปรับขนาดอัตโนมัติได้ในสคริปต์ Terraform ต่อไปนี้ [Amazon Web Services / Google Cloud]
Aggregation Worker จะเรียกใช้บริการการบัญชีรายงานแบบรวมสำหรับการบัญชีรายงานแบบรวม บริการบัญชีรายงานแบบรวมจะตรวจสอบว่าระบบจะเรียกใช้งานเฉพาะในกรณีที่ยังไม่ใช้งบประมาณความเป็นส่วนตัวเกินขีดจํากัดเท่านั้น (ดูกฎ"ไม่ซ้ำกัน") หากมีงบประมาณ ระบบจะสร้างรายงานสรุปโดยใช้ข้อมูลสรุปรวมที่มีสัญญาณรบกวน อ่านรายละเอียดเพิ่มเติมเกี่ยวกับการบัญชีรายงานแบบรวม
Aggregation Worker จะอัปเดตข้อมูลเมตาของงานในฐานข้อมูลข้อมูลเมตาของงาน รวมถึงรหัสผลลัพธ์ของงานที่เหมาะสมและตัวนับข้อผิดพลาดของรายงานในกรณีที่รายงานบางส่วนไม่สำเร็จ ผู้ใช้สามารถดึงข้อมูลสถานะได้โดยใช้ API การดึงข้อมูลสถานะงาน (getJob)
ดูคำอธิบายโดยละเอียดของบริการรวบรวมข้อมูลได้ที่คำอธิบาย
ขั้นตอนถัดไป
เมื่อทราบไฮไลต์ของบริการรวบรวมข้อมูลแล้ว ก็ถึงเวลาที่คุณจะนำอินสแตนซ์ของบริการรวบรวมข้อมูลของคุณเองไปใช้งานผ่าน Google Cloud หรือ Amazon Web Services โปรดดูส่วนเริ่มต้นใช้งาน หรือหากต้องการข้อมูลเพิ่มเติมเกี่ยวกับวิธีใช้งานบริการรวบรวมข้อมูลที่ติดตั้งใช้งานแล้ว ให้ไปที่ลิงก์นี้เพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับการใช้งานบริการรวบรวมข้อมูล
การแก้ปัญหา
โปรดอ่านเอกสารรหัสข้อผิดพลาดที่พบบ่อยและการบรรเทาเพื่อดูคำอธิบายโดยละเอียดเพิ่มเติมเกี่ยวกับข้อความแสดงข้อผิดพลาด สาเหตุที่อาจทำให้เกิดข้อผิดพลาดที่คุณพบ และขั้นตอนถัดไปในการบรรเทา
รับการสนับสนุนและแสดงความคิดเห็น
- หากมีคำถาม ความคิดเห็น และคำขอฟีเจอร์เกี่ยวกับผลิตภัณฑ์ โปรดสร้างปัญหาในที่เก็บ GitHub
- หากต้องการขอรับการสนับสนุนด้านการแก้ปัญหาทางเทคนิคเมื่อพบข้อผิดพลาดขณะติดตั้งใช้งาน ดูแลรักษา หรือเรียกใช้งานด้วยบริการรวบรวมข้อมูล ให้ใช้แบบฟอร์มการสนับสนุนด้านเทคนิคนี้
- ตรวจสอบปัญหาที่ทราบในหน้าแดชบอร์ดสถานะสาธารณะ