Key concepts of the Private Aggregation API
Who is this document for?
The Private Aggregation API enables aggregate data collection from worklets with access to cross-site data. The concepts shared here are important for developers building reporting functions within Shared Storage and Protected Audience API.
- If you're a developer building a reporting system for cross-site measurement.
- If you're a marketer, data scientist, or other summary report consumer, understanding these mechanisms will help you make design decisions to retrieve an optimized summary report.
Key terms
Before reading this document, it will be helpful to familiarize yourself with key terms and concepts. Each of these terms will be described in-depth here.
- An aggregation key (also known as a bucket) is a predetermined collection of data points. For example, you may want to collect a bucket of location data where the browser reports the country name. An aggregation key may contain more than one dimension (for example, country and ID of your content widget).
- An aggregatable value is an individual data point
collected into an aggregation key. If you want to measure how many users
from France have seen your content, then
Franceis a dimension in the aggregation key, and theviewCountof1is the aggregatable value. - Aggregatable reports are generated and encrypted within a browser. For the Private Aggregation API, this contains data about a single event.
- The Aggregation Service processes data from aggregatable reports to create a summary report.
- A summary report is the final output of the Aggregation Service, and contains noisy aggregated user data and detailed conversion data.
- A worklet is a piece of infrastructure which lets you run specific JavaScript functions and return information back to the requester. Within a worklet, you can execute JavaScript but you cannot interact or communicate with the outside page.
Private Aggregation workflow
When you call the Private Aggregation API with an aggregation key and an aggregatable value, the browser generates an aggregatable report. The reports are sent to your server that batches the reports. The batched reports are processed later by the Aggregation Service, and a summary report is generated.
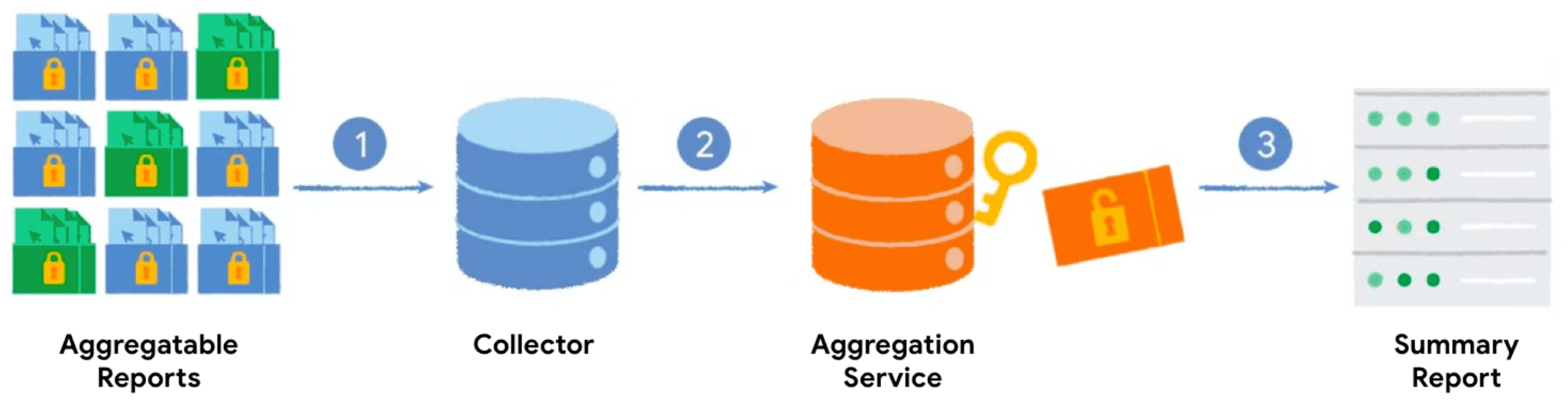
- When you call the Private Aggregation API, the client (browser) generates and sends the aggregatable report to your server to be collected.
- Your server collects the reports from the clients and batches them to be sent to the Aggregation Service.
- Once you've collected enough reports, you'll batch and send them to the Aggregation Service, running in a trusted execution environment, to generate a summary report.
The workflow described in this section is similar to the Attribution Reporting API. However, Attribution Reporting associates data gathered from an impression event and a conversion event, which happen at different times. Private Aggregation measures a single, cross-site event.
Aggregation key
An aggregation key ("key" for short) represents the bucket where the aggregatable values will be accumulated. One or more dimensions can be encoded into the key. A dimension represents some aspect that you want to gain more insight on, such as the age group of users or the impression count of an ad campaign.
For example, you may have a widget that is embedded across multiple sites and want to analyze the country of users who have seen your widget. You are looking to answer questions such as "How many of the users who have seen my widget are from Country X?" To report on this question, you can set up an aggregation key that encodes two dimensions: widget ID and country ID.
The key supplied to the Private Aggregation API is a
BigInt,
which consists of multiple dimensions. In this example, the dimensions are the
widget ID and country ID. Let's say that the widget ID can be up to 4 digits
long such as 1234, and each country is mapped to a number in alphabetical
order such as Afghanistan is 1, France is 61, and Zimbabwe is 195.
Therefore, the aggregatable key would be 7 digits long, where the first 4
characters are reserved for the WidgetID and the last 3 characters are
reserved for the CountryID.
Let's say the key represents the count of users from France (country ID 061)
who have seen the widget ID 3276, The aggregation key is 3276061.
| Aggregation key | |
| Widget ID | Country ID |
| 3276 | 061 |
The aggregation key can be also generated with a hashing mechanism, such as
SHA-256. For example, the string
{"WidgetId":3276,"CountryID":67} can be hashed and then converted to a
BigInt value of
42943797454801331377966796057547478208888578253058197330928948081739249096287n.
If the hash value has more than 128 bits, you can truncate it to ensure it won't
exceed the maximum allowed bucket value of 2^128−1.
Within a Shared Storage worklet, you can access the
crypto and
TextEncoder modules
that can help you generate a hash. To learn more on generating a hash, check out
SubtleCrypto.digest() on
MDN.
The following example describes how you can generate a bucket key from a hashed value:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Aggregatable value
Aggregatable values are summed per key across many users to generate aggregated insights in the form of summary values in summary reports.
Now, return to the example question posed previously: "How many of the users who have seen my widget are from France?" The answer to this question will look something like "Approximately 4881 users who have seen my Widget ID 3276 are from France." The aggregatable value is 1 for each user, and "4881 users" is the aggregated value that is the sum of all aggregatable values for that aggregation key.
| Aggregation key | Aggregatable value | |
| Widget ID | Country ID | View Count |
| 3276 | 061 | 1 |
For this example, we increment the value by 1 for each user who sees the widget. In practice, the aggregatable value can be scaled to improve signal-to-noise ratio.
Contribution budget
Each call to the Private Aggregation API is called a contribution. To protect user privacy, the number of contributions which can be collected from an individual are limited.
When you sum all aggregatable values across all aggregation keys, the sum must be less than the contribution budget. The budget is scoped per-worklet origin, per-day, and is separate for Protected Audience API and Shared Storage worklets. A rolling window of approximately the last 24 hours is used for the day. If a new aggregatable report would cause the budget to be exceeded, the report is not created.
The contribution budget is represented by the parameter L1, and is set to 216 (65,536) per ten minutes per day with a backstop of 220 (1,048,576). See the explainer to learn more about these parameters.
The value of the contribution budget is arbitrary, but noise is scaled to it. You can use this budget to maximize signal-to-noise ratio on the summary values (discussed further in the Noise and scaling section).
To learn more about contribution budgets, see the explainer. Also, refer to Contribution Budget for more guidance.
Contribution limit per report
Depending on the caller, the contribution limit may differ. At this time, reports generated for Shared Storage API callers are capped at 20 contributions per report. On the other hand, Protected Audience API callers are capped at 100 contributions per report. These limits were chosen to balance the number of contributions that can be embedded with the size of the payload.
For Shared Storage, contributions made within a single run() or selectURL()
operation are batched into one report. For Protected Audience, contributions made
by a single origin within an auction are batched together.
Contributions with padding
Contributions are further modified with a padding feature. The act of padding the
payload safeguards information about the true number of contributions embedded in
the aggregatable report. The padding augments the payload with null contributions
(i.e with value of 0) to reach a fixed length.
Aggregatable reports
Once the user invokes the Private Aggregation API, the browser generates
aggregatable reports to be processed by the Aggregation Service at a later point
in time to generate summary
reports. An
aggregatable report is JSON-formatted and contains an encrypted list of
contributions, each one being an {aggregation key, aggregatable value} pair.
Aggregatable reports are sent with a random delay up to one hour.
The contributions are encrypted and not readable outside of Aggregation Service. The Aggregation Service decrypts the reports and generates a summary report. The encryption key for the browser and the decryption key for the Aggregation Service are issued by the coordinator, which acts as the key management service. The coordinator keeps a list of binary hashes of the service image to verify that the caller is allowed to receive the decryption key.
An example aggregatable report with debug mode enabled:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
The aggregatable reports can be inspected from the
chrome://private-aggregation-internals page:

For testing purposes, the "Send Selected Reports" button can be used to send the report to the server immediately.
Collect and batch aggregatable reports
The browser sends the aggregatable reports to the origin of the worklet containing the call to the Private Aggregation API, using the listed well-known path:
- For Shared Storage:
/.well-known/private-aggregation/report-shared-storage - For Protected Audience:
/.well-known/private-aggregation/report-protected-audience
At these endpoints, you will need to operate a server — acting as a collector — that receives the aggregatable reports sent from the clients.
The server should then batch reports and send the batch to the Aggregation
Service. Create batches based on the information available in the unencrypted
payload of the aggregatable report, such as the shared_info field. Ideally,
the batches should contain 100 or more reports per batch.
You may decide to batch on a daily or weekly basis. This strategy is flexible, and you can change your batching strategy for specific events where you expect more volume—for example, days of the year when more impressions are expected. Batches should include reports from the same API version, reporting origin, and schedule report time.
Aggregation Service
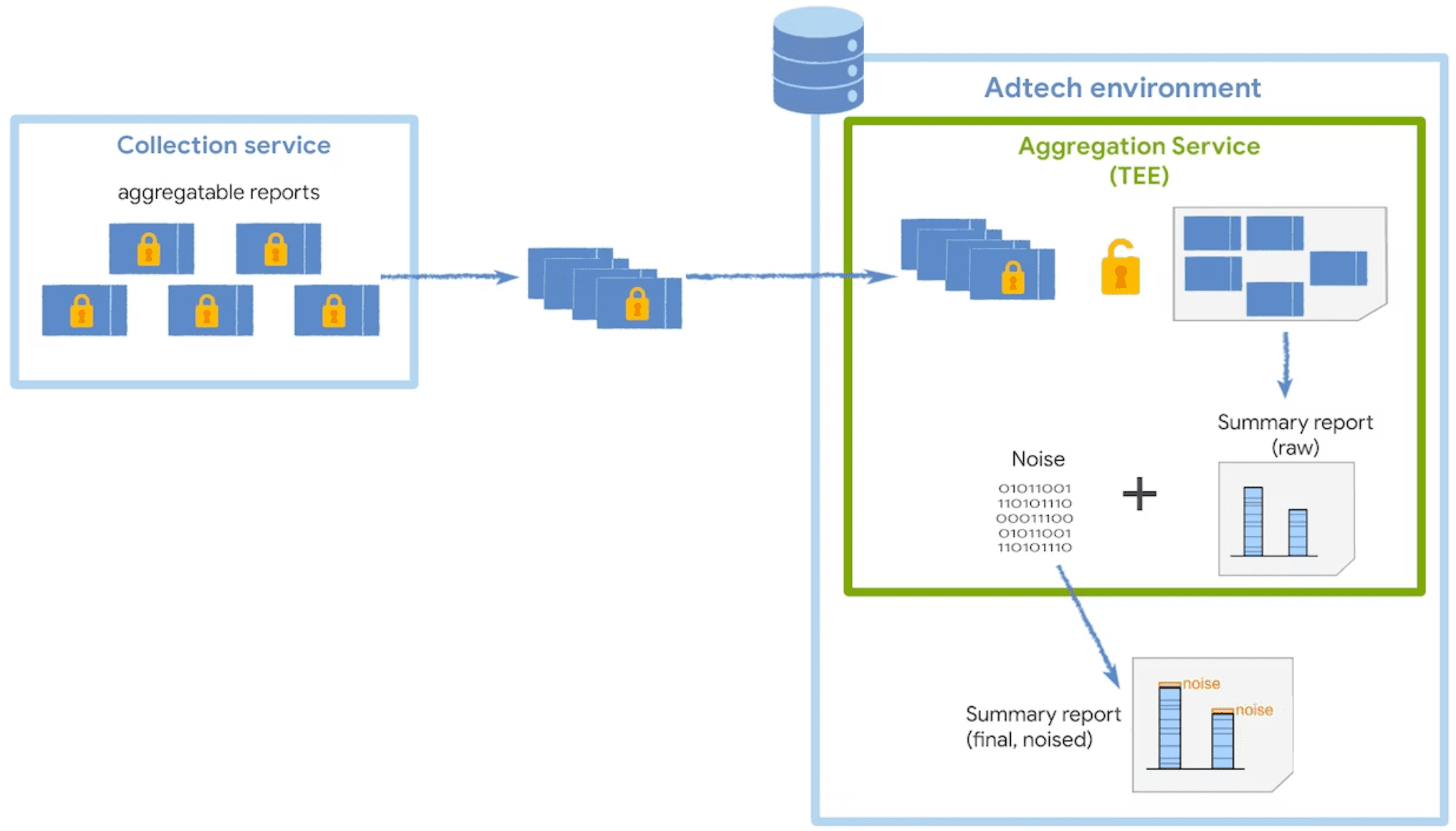
The Aggregation Service receives encrypted aggregatable reports from the collector and generates summary reports.
To decrypt the report payload, the Aggregation Service fetches a decryption key from the coordinator. The service runs in a trusted execution environment (TEE), which provides a level of assurance for data integrity, data confidentiality, and code integrity. Though you own and operate the service, you will not have visibility into the data being processed inside the TEE.
Summary reports
Summary reports allow you to see the data you have collected with noise added. You can request summary reports for a given set of keys.
A summary report contains a JSON dictionary-style set of key-value pairs. Each pair contains:
bucket: the aggregation key as a binary number string. If the aggregation key used is "123", then the bucket is "1111011".value: the summary value for a given measurement goal, summed up from all available aggregatable reports with noise added.
For example:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Noise and scaling
To preserve user privacy, the Aggregation Service adds noise once to each summary value every time a summary report is requested. The noise values are randomly drawn from a Laplace probability distribution. While you are not in direct control of the ways noise is added, you can influence the impact of noise on its measurement data.
The noise distribution is the same regardless of the sum of all aggregatable values. Therefore, the higher the aggregatable values, the less impact the noise is likely to have.
For example, let's say the noise distribution has a standard deviation of 100 and is centered at zero. If the collected aggregatable report value (or "aggregatable value") is only 200, then the noise's standard deviation would be 50% of the aggregated value. But, if the aggregatable value is 20,000, then the noise's standard deviation would only be 0.5% of the aggregated value. So, the aggregatable value of 20,000 would have a much higher signal-to-noise ratio.
Therefore, multiplying your aggregatable value by a scaling factor can help reduce noise. The scaling factor represents how much you want to scale a given aggregatable value.

Scaling the values up by choosing a larger scaling factor reduces the relative noise. However, this also causes the sum of all contributions across all buckets to reach the contribution budget limit faster. Scaling the values down by choosing a smaller scaling factor constant increases relative noise, but reduces the risk of reaching the budget limit.
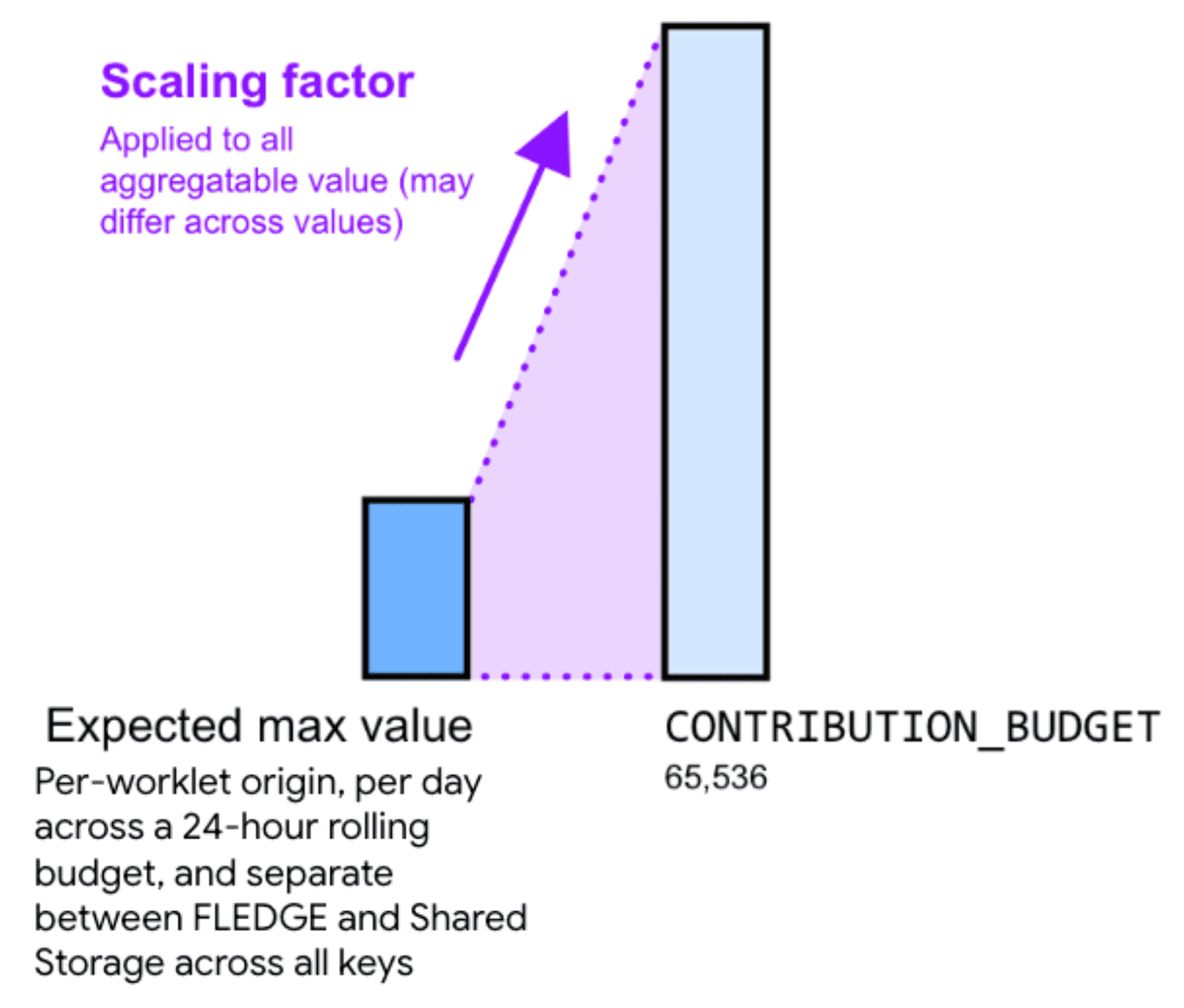
To calculate an appropriate scaling factor, divide the contribution budget by the maximum sum of aggregatable values across all keys.
See the Contribution budget documentation to learn more.
Engage and share feedback
The Private Aggregation API is under active discussion and subject to change in the future. If you try this API and have feedback, we'd love to hear it.
- GitHub: Read the explainer, raise questions and participate in discussion. * Developer support: Ask questions and join discussions on the Privacy Sandbox Developer Support repo. * Join the Shared Storage API group and the Protected Audience API group for the latest announcements related to Private Aggregation.