Usługa agregacji generuje raporty podsumowujące szczegółowych danych o konwersjach i danych dotyczących zasięgu na podstawie nieprzetworzonych raportów podlegających agregacji. Technologie reklamowe mają po stronie klienta 2 główne zagregowane punkty wejścia, które umożliwiają przekazywanie raportów ścieżki do usługi agregacji – za pomocą Attribution Reporting API lub Private Aggregation API.
Stan wdrożenia
- Usługa agregacji została teraz ogólnie dostępna.
- Z usługi agregacji można korzystać w połączeniu z interfejsami Attribution Reporting API i Private Aggregation API w przypadku interfejsów Protected Audience API i Shared Storage API.
Dostępność
| Proposal | Status |
|---|---|
| Aggregation Service support for Amazon Web Services (AWS) across Attribution Reporting API, Private Aggregation API
Explainer |
Available |
| Aggregation Service support for Google Cloud across Attribution Reporting API, Private Aggregation API Explainer |
Available |
| Aggregation Service site enrollment and multi-origin aggregation. Site enrollment includes mapping of a site to cloud accounts (AWS, or GCP). To aggregate multiple origins, they must be of the same site.
FAQs on GitHub Site aggregation API documentation |
Available |
| The Aggregation Service's epsilon value will be kept as a range of up to 64, to facilitate experimentation and feedback on different parameters.
Submit ARA epsilon feedback. Submit PAA epsilon feedback. |
Available. We will provide advanced notice to the ecosystem before the epsilon range values are updated. |
| More flexible contribution filtering for Aggregation Service queries
Explainer |
Available |
| Process for budget recovery post-disasters (errors, misconfigurations, and so on)
Explainer |
Available Mechanism to review the percentage of shared IDs recovered by an ad tech using budget recovery and suspend future recoveries for excessive recoveries planned for H1 2025 |
| Accenture operating as one of the Coordinators on AWS
Developer Blog |
Available |
| Independent party operating as one of the Coordinators on Google Cloud
Developer blog |
Available |
| Aggregation Service support for Aggregate Debug Reporting on Attribution Reporting API
Explainer |
Available |
Kluczowe terminy i pojęcia
Jeśli zastanawiasz się nad wykorzystaniem usługi agregacji w swojej pracy związanej z technologią reklamową, z poniższych terminów i zagadnień dowiesz się, co nowy proces agregacji może Ci zaoferować:
| Term | Description |
|---|---|
| Aggregation Service | An ad tech-operated service that processes aggregatable reports to create a summary report. |
| Aggregatable Reports |
Aggregatable reports are encrypted reports sent from individual user devices. These reports contain data about cross-site user behavior and conversions. Conversions (sometimes called attribution trigger events) and associated metrics are defined by the advertiser or ad tech. Each report is encrypted to prevent various parties from accessing the underlying data. Learn more about aggregatable reports. |
| Aggregatable Report Accounting | A distributed ledger located in both coordinators that tracks allocated privacy budget and enforces the 'No Duplicates' rule. This is the privacy preserving mechanism, located and run within coordinators, that ensures that no report passes through Aggregation Service beyond the allocated privacy budget. Read more on batching strategies on how it relates to aggregatable reports. |
| Aggregatable Report Accounting Budget | References to the budget that ensures reports are not processed more than once. |
| Trusted Execution Environment (TEE) |
A trusted execution environment is a special configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the computer. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less. To learn more about TEEs used for the Privacy Sandbox proposals, read the Protected Audience API services explainer and the Aggregation Service explainer. |
| Coordinators |
A coordinator is an entity responsible for key management and aggregatable report accounting. The coordinator maintains a list of hashes of approved aggregation service configurations and configures access to decryption keys. |
| Shared ID |
Computed value that consists of: shared_info, reporting_origin, destination_site (available for Attribution Reporting API only), source_registration-time (available for Attribution Reporting API only), scheduled_report_time, version.
This means that multiple reports belong to the same shared ID should they share the same attributes of the shared_info field. This plays an important role within Aggregatable Report Accounting.
Read more about Trusted Servers.
|
| Summary Report |
A summary report is an Attribution Reporting API and Private Aggregation API report type. A summary report includes aggregated user data and can contain detailed conversion data, with noise added. Summary reports are made up of aggregate reports. Summary reports allow for greater flexibility and a richer data model than event-level reporting, particularly for some use-cases like conversion values. |
| Reporting Origin |
Źródło raportowania to podmiot, który otrzymuje raporty podlegające agregacji, czyli inaczej technologia reklamowa, która wywołała interfejs Attribution Reporting API. Raporty podlegające agregacji są wysyłane z urządzeń użytkowników na znany adres URL powiązany z miejscem pochodzenia raportu. To źródło raportowania należy określić podczas rejestracji. |
| Contribution Bonding | Aggregatable reports may contain an arbitrary number of counter increments. For example, a report may contain a count of products that a user has viewed on an advertiser's site. The sum of increments in all aggregatable reports related to a single source event must not exceed a given limit, `L1=2^16`. Learn more in the aggregatable reports explainer. |
| Noise & Scaling | A certain amount of statistical noise is added to summary reports as a part of the aggregation process that also functions to preserve privacy and ensure the final reports provide anonymized measurement information. Read more about additive noise mechanism, which is drawn from Laplace distribution. |
| Attestation |
Attestation is a mechanism to authenticate software identity, usually with cryptographic hashes or signatures. For the aggregation service proposal, attestation matches the code running in the ad tech-operated aggregation service with the open source code. Read more about attestation. |
Przeczytaj więcej o historii usługi agregacji w naszym objaśnieniu i na pełnej liście warunków.
Przypadki użycia agregacji
Zapoznaj się z podanymi niżej ścieżkami dewelopera związanymi z pomiarem skuteczności reklam i odpowiadającymi im bibliotekami klienta do pomiaru.
| Przypadek użycia | Punkt wejścia | Opis |
|---|---|---|
| Optymalizacja stawek | Attribution Reporting API (Chrome i Android) | Używaj raportów zbiorczych do pozyskiwania sygnałów konwersji na potrzeby optymalizacji określania stawek. |
| Pomiar na wielu platformach | Attribution Reporting API (Chrome i Android) | Korzystaj z możliwości pomiaru skuteczności w internecie i aplikacjach, aby mieć wgląd w skuteczność w Chrome i na Androidzie. |
| Raportowanie konwersji | Attribution Reporting API (Chrome i Android) | tworzenie raportów o konwersjach zbiorczych dostosowanych do potrzeb kampanii klientów (w tym CTC i VTC); |
| Pomiar zasięgu kampanii | Shared Storage API i Private Aggregation API(Chrome) | Używaj zmiennych widoku reklamy w wielu witrynach do pomiaru zasięgu kampanii. |
| Raporty demograficzne | Shared Storage API i Private Aggregation API (Chrome) | Używaj danych o wyświetleniach reklam w wielu witrynach i danych demograficznych do pomiaru zasięgu według danych demograficznych. |
| Analiza ścieżki konwersji | Shared Storage API i Private Aggregation API (Chrome) | Przechowuj dane o wyświetleniach reklam w różnych witrynach i zmienne konwersji, aby przeprowadzać zagregowaną analizę ścieżki konwersji. |
| Wyniki marki i zwiększenie liczby konwersji | Shared Storage API i Private Aggregation API(Chrome) | Raportowanie na temat grup testowych/kontrolnych oraz informacji z ankiet służących do pomiaru wyników marki i przyrostu wartości. |
| Debugowanie aukcji | Protected Audience API i Private Aggregation API (Chrome) | Używaj raportów zbiorczych do debugowania. |
| Rozkład stawek | Protected Audience API & Private Aggregation API (Chrome) | Korzystaj z raportów zbiorczych, by rejestrować rozkład wartości stawek w aukcjach. |
Kompleksowy proces
Poniższy diagram pokazuje działanie usługi agregacji. Skupimy się na całym procesie – od otrzymywania raportów z internetu i aplikacji mobilnych po tworzenie raportów podsumowujących w usłudze agregacji.
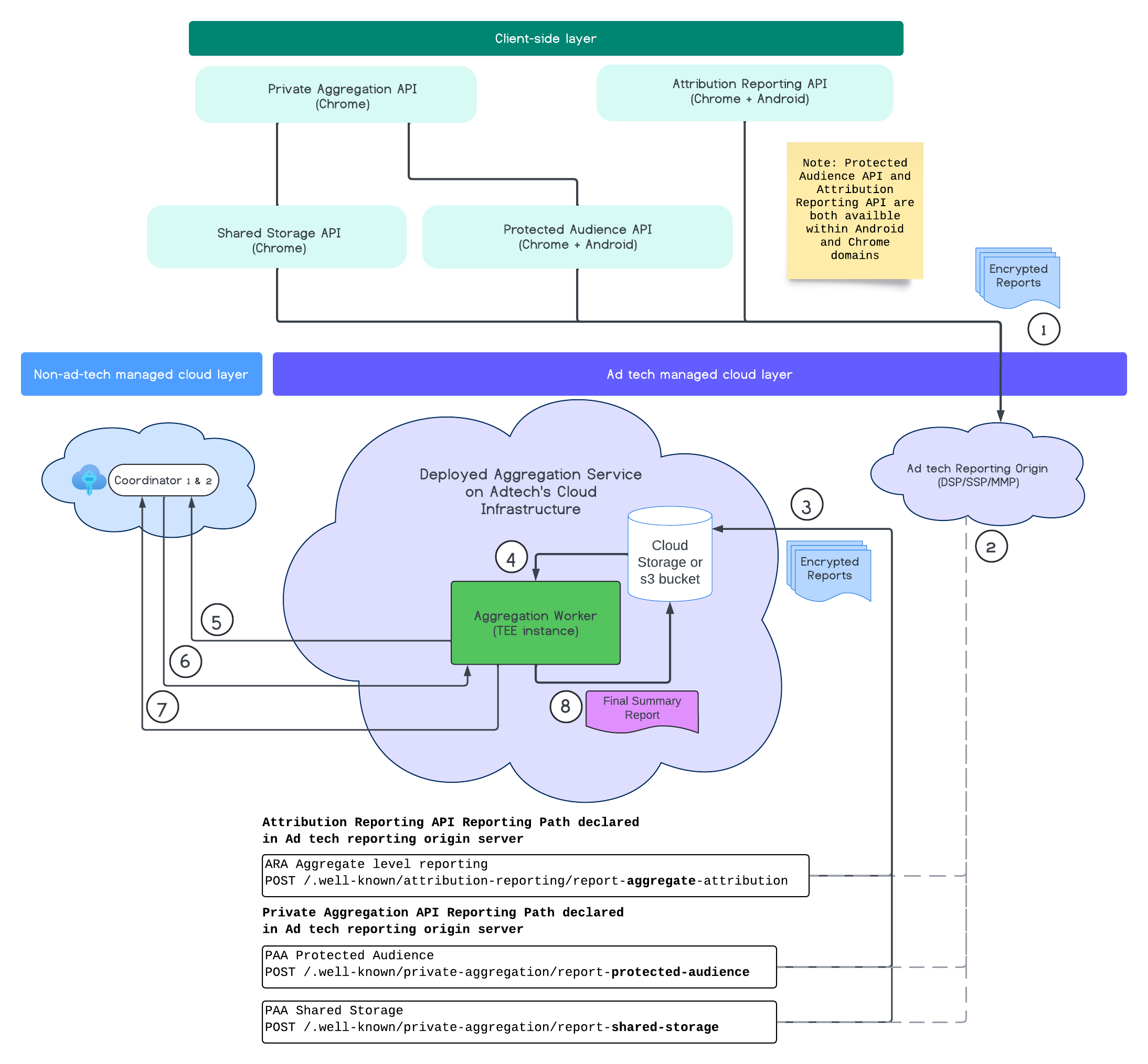
- Pobierz klucz publiczny, aby generować zaszyfrowane raporty.
- Szyfrowane raporty podlegające agregacji wysyłane na serwery technologii reklamowych w celu zebrania, przekształcenia i zbiorowego przetwarzania.
- Serwer technologii reklamowych tworzy raporty zbiorcze (w formacie avro) i wysyła je do wdrożonej usługi agregacji. (musi zostać wypełniony przez dostawcę technologii reklamowych).
- Pobieranie zagregowanych raportów do odszyfrowania.
- Pobieranie kluczy odszyfrowywania od koordynatorów.
- Usługa do agregacji odszyfrowuje raporty na potrzeby agregacji i dodawania szumu.
- Usługa księgowania raportów agregowanych sprawdza, czy pozostały budżet związany z prywatnością do wygenerowania raportu podsumowującego dane zbiorcze.
- Prześlij końcowy raport podsumowujący.
Na diagramie widać ogólne relacje usługi agregacji z głównymi interfejsami API pomiarów klienta: Attribution Reporting API, Private Aggregation API i koordynatorami.
Proces rozpoczyna się od różnych interfejsów Measurement API, takich jak Attribution Reporting API czy Private Aggregation API, które generują raporty z wielu instancji przeglądarki. Chrome pobiera klucz publiczny z usługi hostingu kluczy w koordynatorze, aby zaszyfrować raporty, zanim trafią one do źródła raportowania technologii reklamowych. Klucze publiczne są poddawane rotacji co 7 dni.
Gdy usługa raportowania otrzyma te raporty, powinna je zebrać i przekształcić w format avro, a potem przesłać do wdrożonej instancji usługi agregacji. Zapoznaj się z strategiami zbiorczego ustalania stawek.
Gdy technologia reklamowa jest gotowa do przetwarzania wsadowego, tworzy żądanie zbiorcze do usługi agregacji, w której raporty są odszyfrowywane przez pobranie kluczy odszyfrowywania z usługi hostingu kluczy, a następnie zagregowanie i zaszumianie w celu utworzenia raportu podsumowującego. Pamiętaj, że zależy to od tego, czy masz wystarczający budżet na prywatność, aby wygenerować końcowe raporty podsumowania.
Punkt końcowy punktu początkowego raportowania dotyczącego technologii reklamowych, w którym są zbierane raporty, jest hostowany przez technologię reklamową, a usługa agregacji jest wdrożona w chmurze technologii reklamowej.
grupowanie raportów zbiorczych.
Raportowanie nie byłoby pełne bez pomocy wyznaczonego serwera źródła zgłoszeń. To jest źródło, które firma zajmująca się technologią reklamową przesłałaby w ramach procesu rejestracji. Główne działania, za które odpowiada źródło raportowania, to gromadzenie, przekształcanie i grupowanie otrzymanych raportów zbiorczych oraz przygotowywanie ich do wysłania do wdrożonej w danej technologii reklamowej usługi agregacji w Google Cloud lub Amazon Web Services. Dowiedz się więcej o przygotowywaniu raportów zbiorczych.
Teraz gdy masz już ogólne założenie, przyjrzyj się komponentom, które zostaną wdrożone w Twojej usłudze agregacji.
Komponenty Cloud
Usługa agregacji składa się z różnych komponentów usług w chmurze. Udostępnione skrypty Terraform udostępniają i konfigurują wszystkie niezbędne komponenty usługi w chmurze.
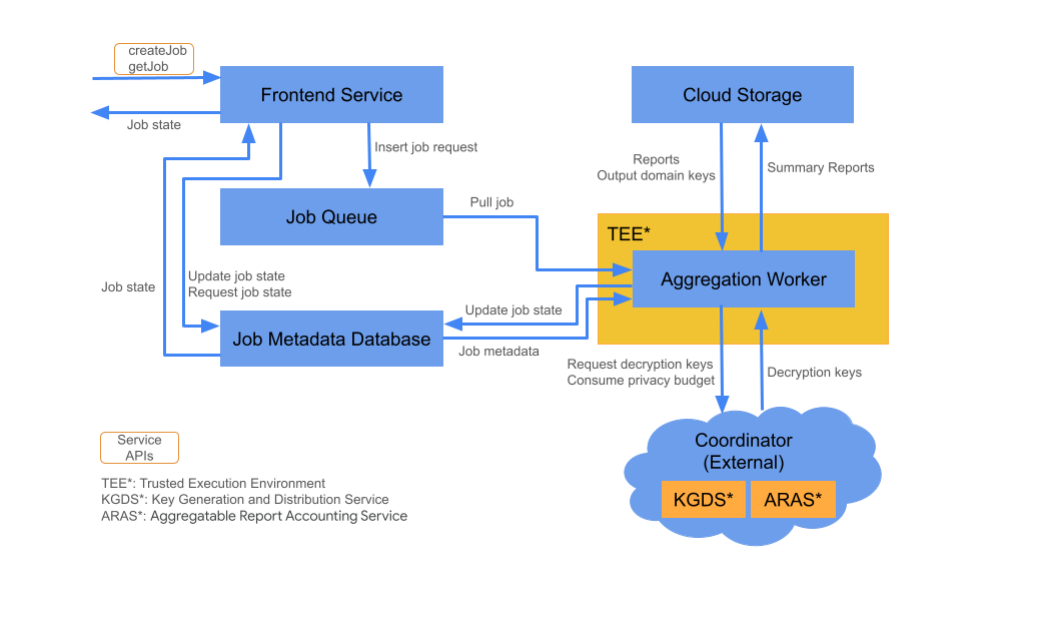
Usługa frontendu
Usługa w chmurze zarządzanej: Cloud Functions (Google Cloud) / API Gateway (usługi internetowe Amazon)
Usługa frontendu to bezserwerowa brama, która służy jako punkt wejścia dla wywołań interfejsu Aggregation API na potrzeby tworzenia i pobierania stanu zadania. Odpowiada za odbieranie żądań od użytkowników usługi agregacji, weryfikowanie parametrów wejściowych i inicjowanie procesu planowania zadań agregacji.
W usłudze frontendu dostępne są 2 interfejsy API:
| Punkt końcowy | Opis |
|---|---|
createJob |
Ten interfejs API uruchamia zadanie usługi do agregacji. Do aktywowania zadania wymagane są takie informacje jak identyfikator zadania, dane wejściowe miejsca na dane, szczegóły miejsca wyjściowego, źródło raportowania itp. |
getJob |
Ten interfejs API zwraca stan zadania o określonym identyfikatorze. Zawiera informacje o stanie zadania, takie jak „Otrzymano”, „W toku” lub „Ukończono”. Dodatkowo, jeśli zadanie zostało ukończone, wyświetla się jego wynik, w tym komunikaty o błędach, które wystąpiły podczas jego wykonywania. |
Zapoznaj się z dokumentacją interfejsu API usługi do agregacji.
Kolejka zadań
Usługa w chmurze zarządzanej: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
Kolejka zadań to kolejka wiadomości, w której przechowywane są żądania zadań dotyczące usługi agregacji. Usługa frontendu wstawia do kolejki komunikaty o żądaniach zadań, które są następnie wykorzystywane przez instancję roboczą agregacji do przetworzenia żądania zadania.
Cloud Storage
Zarządzana usługa w chmurze: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services) Cloud Storage służy do przechowywania plików wejściowych i wyjściowych używanych przez usługę agregacji (np. zaszyfrowane pliki raportów, podsumowania wyjściowe itp.).
Baza danych metadanych zadania
Zarządzana usługa w chmurze: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
Baza danych zadań przechowuje i śledzi stan zadań agregacji. Baza danych rejestruje metadane, takie jak czas utworzenia, czas zgłoszenia, czas aktualizacji i stan (np. Otrzymano, W toku, Zakończono itp.). Procesor agregacji aktualizuje bazę danych metadanych zadań w miarę ich przetwarzania.
Skrypt roboczy agregacji
Usługa w chmurze zarządzana: Compute Engine z przestrzenią poufną (Google Cloud) / Amazon Web Services EC2 z Nitro Enclave (Amazon Web Services)
Skrypt roboczy agregacji przetwarza żądania zadań zainicjowane przez żądanie w kolejce zadań, odszyfrowywając zaszyfrowane dane wejściowe za pomocą kluczy pobranych z usługi generowania i dystrybucji kluczy (KGDS) w ramach koordynatorów. Aby zminimalizować opóźnienie przetwarzania zadania, klucze odszyfrowywania są przechowywane w pamięci podręcznej w instancji roboczej agregacji przez 8 godzin i mogą być używane w przypadku zadań przetwarzanych przez tę instancję roboczą.
Pracownik działa w środowisku Trusted Execution Environment (TEE). Każda instancja robocza obsługuje tylko jedno zadanie naraz. Technologia reklamowa może skonfigurować wiele instancji roboczych do równoległego przetwarzania zadań przez ustawienie konfiguracji autoskalowania. Dzięki automatycznemu skalowaniu liczba instancji roboczych jest dostosowywana dynamicznie do liczby wiadomości pozostających w kolejce zadań. Minimalną i maksymalną liczbę instancji roboczych do automatycznego skalowania można skonfigurować w pliku środowiska Terraform. Więcej informacji o autoskalowaniu znajdziesz w tych skryptach terraforma. [Amazon Web Services / Google Cloud]
Zasób roboczy agregacji wywołuje usługę księgowania raportów agregacji w celu księgowania raportów agregacji. Usługa księgowania raportów umożliwiająca agregację zapewni, że zadania będą wykonywane tylko do momentu przekroczenia limitu budżetu na potrzeby prywatności. (Patrz reguła „Brak duplikatów”). Jeśli budżet jest dostępny, na podstawie zbiorczych danych o wysokiej zmienności jest generowany raport podsumowujący. Dowiedz się więcej o rachunkowości w raportach możliwych do zsumowania.
Skrypt roboczy agregacji aktualizuje metadane zadań w bazie danych metadanych zadań, w tym odpowiednie kody zwrotne zadań i zgłasza liczniki błędów w przypadku częściowych błędów raportu. Użytkownicy mogą pobierać stan za pomocą interfejsu Retrieval API (getJob).
Bardziej szczegółowy opis usługi agregacji znajdziesz w naszym objaśnieniu.
Dalsze kroki
Teraz, gdy znasz najważniejsze informacje o usłudze agregacji, możesz wdrożyć własną instancję tej usługi za pomocą Google Cloud lub Amazon Web Services. Zapoznaj się z sekcją Wprowadzenie. Jeśli potrzebujesz więcej informacji o działaniu wdrożonej usługi agregacji, kliknij ten link, aby dowiedzieć się więcej o działaniu usługi agregacji.
Rozwiązywanie problemów
Szczegółowe opisy komunikatów o błędach, przyczyny napotkanego błędu i opisy działań naprawczych znajdziesz w dokumencie Typowe kody błędów i środki zaradcze.
Uzyskiwanie pomocy i przesyłanie opinii
- W przypadku problemów technicznych, pytań o usługi, opinii i propozycji funkcji utwórz problem w naszym repozytorium GitHub.
- Jeśli na potrzeby rozwiązywania problemów musisz podać informacje poufne lub zastrzeżone, napisz na adres aggregation-service-support@google.com
- Sprawdź panel stanu usługi Google Analytics, aby dowiedzieć się, czy wystąpiły znane problemy.