
1. 1. المتطلبات الأساسية
الوقت المقدّر لإنهاء الدرس: ساعة إلى ساعتَين
هناك وضعان لإجراء هذا الدرس التطبيقي حول الترميز: الاختبار المحلي أو خدمة التجميع. يتطلب وضع "الاختبار المحلي" استخدام جهاز محلي ومتصفّح Chrome (بدون إنشاء أو استخدام موارد Google Cloud). يتطلّب وضع "خدمة التجميع" نشرًا كاملاً لخدمة التجميع على Google Cloud.
لتنفيذ هذا الدرس التطبيقي حول الترميز في أي من الوضعَين، يجب استيفاء بعض المتطلبات الأساسية. ويتم وضع علامة على كل متطلب وفقًا لذلك ما إذا كان مطلوبًا للاختبار المحلي أو خدمة التجميع.
1-1- إكمال التسجيل والمصادقة (خدمة التجميع)
لاستخدام واجهات برمجة تطبيقات "مبادرة حماية الخصوصية"، تأكَّد من إكمال عملية التسجيل والمصادقة لكلّ من Chrome وAndroid.
1.2. تفعيل واجهات برمجة التطبيقات للخصوصية في عرض الإعلانات (خدمة الاختبار والتجميع المحلية)
بما أنّنا سنستخدم "مبادرة حماية الخصوصية"، ننصحك بتفعيل واجهات برمجة التطبيقات للإعلانات في "مبادرة حماية الخصوصية".
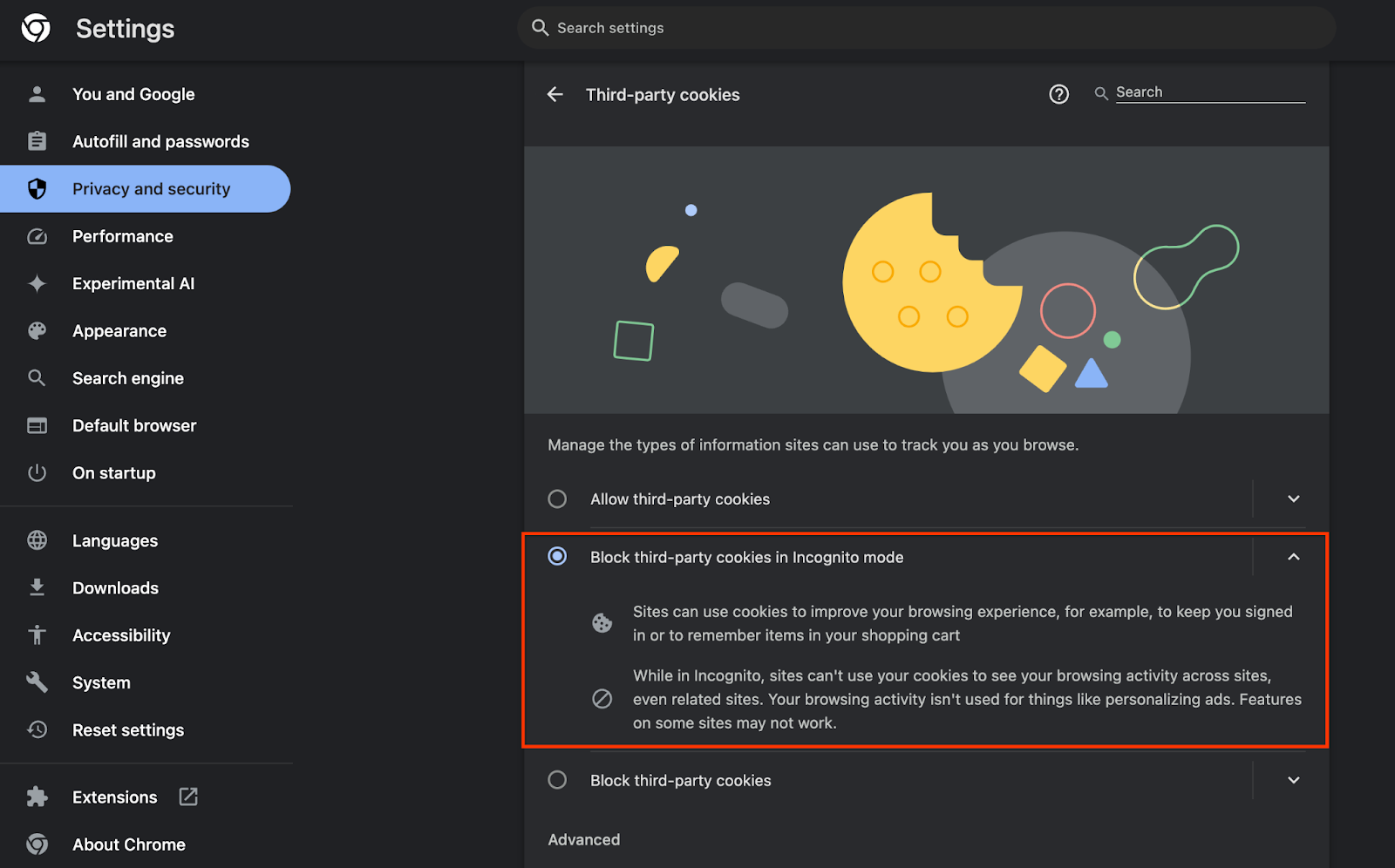
على المتصفّح، انتقِل إلى chrome://settings/adPrivacy وفعِّل جميع واجهات برمجة التطبيقات Ad Privacy API.
تأكَّد أيضًا من تفعيل ملفات تعريف الارتباط التابعة لجهات خارجية.
من chrome://settings/cookies، تأكَّد من عدم حظر ملفات تعريف الارتباط التابعة لجهات خارجية. بناءً على إصدار Chrome، قد تظهر لك خيارات مختلفة في قائمة الإعدادات هذه، ولكن تتضمن الإعدادات المقبولة ما يلي:
- "حظر جميع ملفات تعريف الارتباط التابعة لجهات خارجية" = متوقّف
- "حظر ملفات تعريف الارتباط التابعة لجهات خارجية" = متوقّف
- "حظر ملفات تعريف الارتباط التابعة لجهات خارجية في وضع التصفّح المتخفي" = مفعَّل
1.3. تنزيل أداة الاختبار المحلي (الاختبار المحلي)
سيتطلب الاختبار المحلي تنزيل "أداة الاختبار المحلي". ستنشئ الأداة تقارير موجزة من تقارير تصحيح الأخطاء غير المشفَّرة.
أداة الاختبار المحلي متاحة للتنزيل في أرشيفات Cloud Function JAR في GitHub. ويجب تسميتها باسم LocalTestingTool_{version}.jar.
1.4. التأكّد من تثبيت JAVA JRE (خدمة الاختبار والتجميع المحلية)
افتح "Terminal" واستخدِم java --version لمعرفة ما إذا كان جهازك مثبتًا عليه Java أو openJDK.

إذا لم يكن التطبيق مثبتًا، يمكنك تنزيله وتثبيته من موقع Java أو موقع openJDK الإلكتروني.
1.5. تنزيل aggregatable_report_converter (خدمة الاختبار المحلي والتجميع)
يمكنك تنزيل نسخة من aggregatable_report_converter من مستودع GitHub التجريبي ضمن "مبادرة حماية الخصوصية". يذكر مستودع GitHub باستخدام IntelliJ أو Eclipse، لكن لا يلزم أي منهما. في حال عدم استخدام هذه الأدوات، يمكنك تنزيل ملف JAR على بيئتك المحلية بدلاً من ذلك.
1.6. إعداد بيئة Google Cloud Platform (خدمة التجميع)
تتطلّب "خدمة التجميع" استخدام بيئة تنفيذ موثوقة تستخدم أحد مقدّمي خدمات السحابة الإلكترونية. في هذا الدرس التطبيقي حول الترميز، سيتم نشر خدمة التجميع في Google Cloud Platform، ولكن تتوفّر خدمة AWS أيضًا.
يُرجى اتّباع تعليمات النشر في GitHub لإعداد واجهة سطر الأوامر gcloud CLI، وتنزيل البرامج الثنائية والوحدات من Terraform، وإنشاء موارد GCP لخدمة التجميع.
الخطوات الرئيسية في تعليمات النشر:
- إعداد "gcloud" CLI وTeraform في بيئتك.
- يمكنك إنشاء حزمة Cloud Storage لتخزين حالة Terraform.
- تنزيل التبعيات.
- حدِّث
adtech_setup.auto.tfvarsوشغِّلadtech_setupTerraform. راجِع الملحق للاطّلاع على مثال لملفadtech_setup.auto.tfvars. لاحِظ اسم حزمة البيانات التي يتم إنشاؤها هنا، حيث سيتم استخدام هذا الاسم في الدرس التطبيقي حول الترميز لتخزين الملفات التي ننشئها. - عليك تحديث
dev.auto.tfvars، وانتحال هوية حساب الخدمة، وتشغيلdevTerraform. راجِع الملحق للاطّلاع على مثال لملفdev.auto.tfvars. - بعد اكتمال النشر، التقط
frontend_service_cloudfunction_urlمن ناتج Terraform، وهو مطلوب لإرسال طلبات إلى خدمة التجميع في خطوات لاحقة.
1.7. إكمال عملية إعداد خدمة التجميع (خدمة التجميع)
تتطلب خدمة التجميع إعدادًا للمنسقين ليتمكنوا من استخدام الخدمة. املأ نموذج إعداد خدمة التجميع من خلال تقديم "موقع الإبلاغ عن المحتوى" ومعلومات أخرى، واختيار "Google Cloud"، وإدخال عنوان حساب الخدمة. يتم إنشاء حساب الخدمة هذا وفقًا للشرط الأساسي السابق (1.6. إعداد بيئة Google Cloud Platform). (تلميح: إذا كنت تستخدم الأسماء التلقائية المقدّمة، سيبدأ حساب الخدمة هذا بـ "worker-sa@ ").
يُرجى الانتظار لمدة تصل إلى أسبوعَين حتى تكتمل عملية منح إمكانية الوصول إلى التطبيق.
1.8. تحديد طريقتك لطلب نقاط نهاية واجهة برمجة التطبيقات (خدمة التجميع)
يوفّر هذا الدرس التطبيقي خيارَين لطلب نقطتَي نهاية Aggregation Service API: cURL وPostman. يشكّل cURL الطريقة الأسرع والأسهل لطلب نقاط نهاية واجهة برمجة التطبيقات من الوحدة الطرفية، لأنّها تتطلّب الحد الأدنى من عملية الإعداد ولا تتطلّب أي برامج إضافية. مع ذلك، إذا كنت لا تريد استخدام cURL، يمكنك استخدام Postman بدلاً من ذلك لتنفيذ طلبات البيانات من واجهة برمجة التطبيقات وحفظها لاستخدامها في المستقبل.
في الفقرة 3.2. لاستخدام خدمة التجميع، يمكنك العثور على تعليمات تفصيلية لاستخدام كلا الخيارين. يمكنك معاينتها الآن لتحديد الطريقة التي ستستخدمها. إذا اخترت Postman، يمكنك إجراء الإعداد الأوّلي التالي.
1.8.1. إعداد مساحة العمل
اشترِك لإنشاء حساب على Postman. بعد الاشتراك، يتم إنشاء مساحة عمل تلقائيًا.
في حال لم يتم إنشاء مساحة عمل لك، انتقِل إلى "مساحات العمل". عنصر التنقّل العلوي واختيار "إنشاء مساحة عمل"
اختَر "مساحة عمل فارغة"، وانقر على "التالي" واسمها "مبادرة حماية خصوصية Google Cloud Platform". اختيار "الإعدادات الشخصية" وانقر على "إنشاء".
نزِّل ضبط JSON لمساحة العمل التي تم ضبطها مسبقًا وملفات البيئة العالمية.
استيراد ملفَّي JSON إلى "مساحة العمل" من خلال زر "الاستيراد" .

سيؤدي ذلك إلى إنشاء "مبادرة حماية الخصوصية على Google Cloud Platform". المجموعة إلى جانب طلبَي HTTP createJob وgetJob.
1.8.2. إعداد التفويض
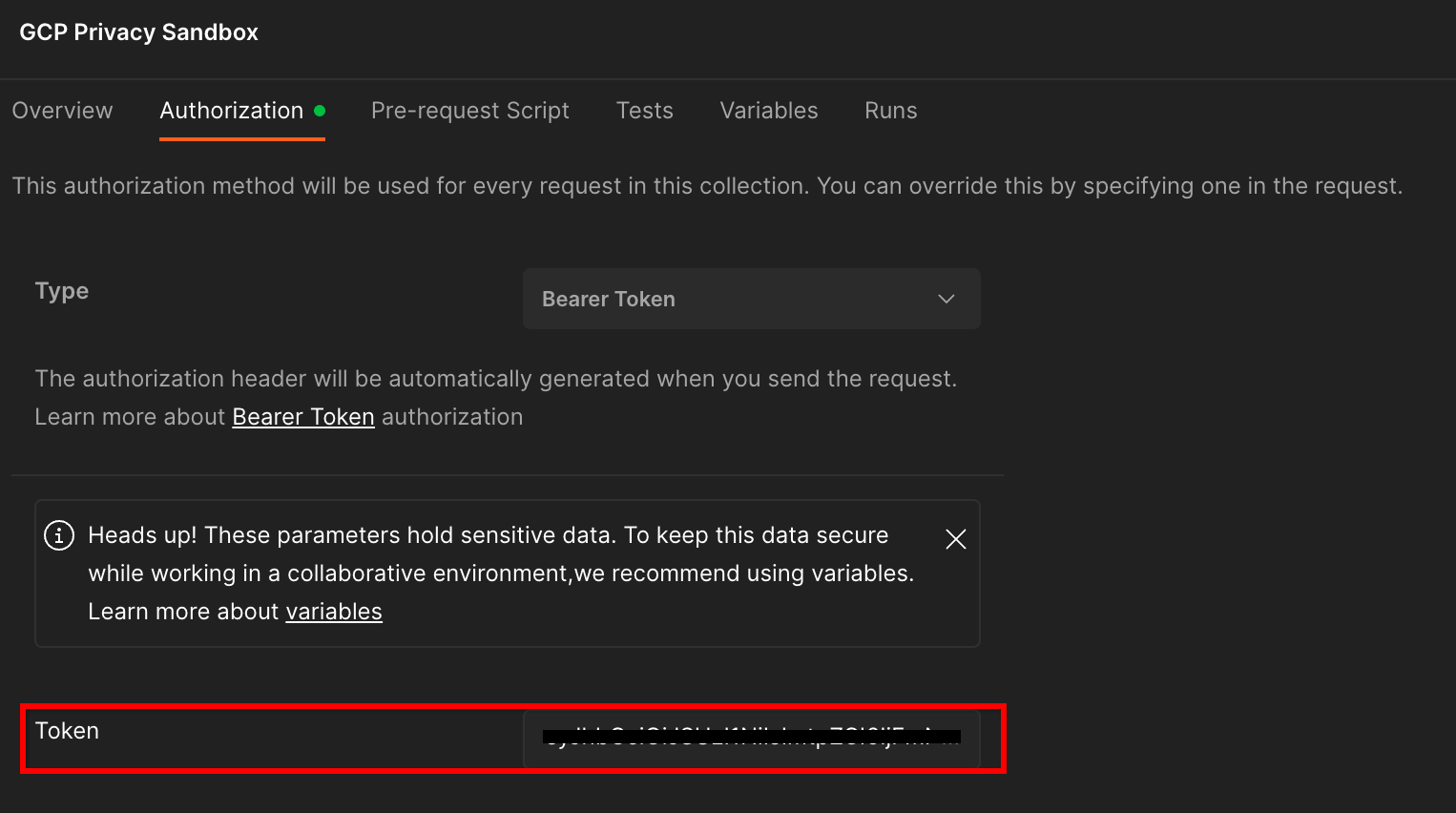
انقر على "مبادرة حماية الخصوصية في Google Cloud Platform". المجموعة والانتقال إلى قسم "التفويض" .

ستستخدم "رمز الحامل المميز" . من البيئة الطرفية، شغِّل هذا الأمر وانسخ الناتج.
gcloud auth print-identity-token
ثم ألصِق قيمة الرمز المميّز هذه في "الرمز المميّز" في علامة تبويب تفويض Postman:
1.8.3. إعداد البيئة
الانتقال إلى "النظرة السريعة للبيئة" في أعلى الجانب الأيسر:
النقر على "تعديل" وتعديل "القيمة الحالية" لكل من "environment" و"region" و"cloud-function-id":
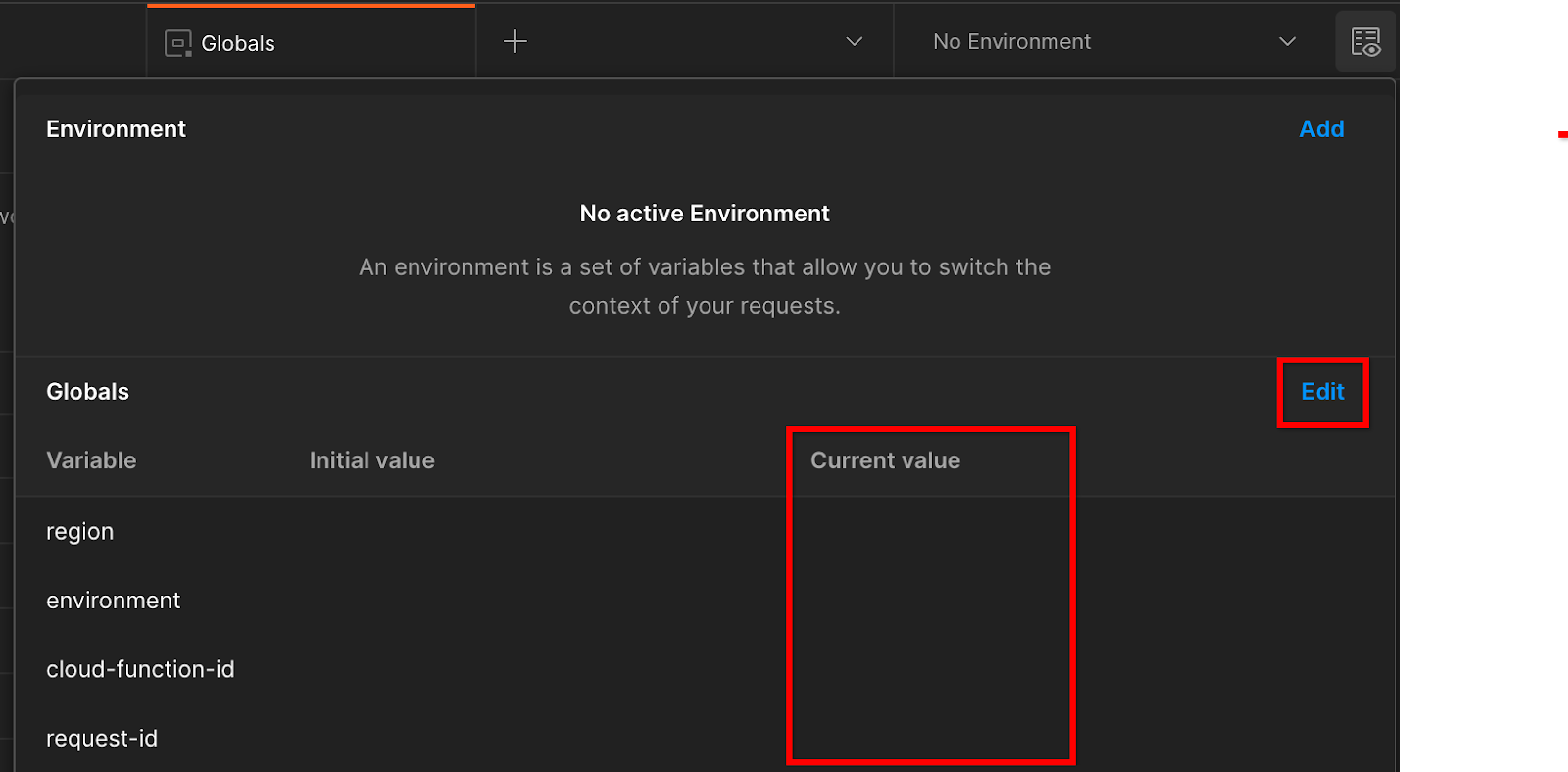
يمكنك ترك "request-id" فارغًا في الوقت الحالي، حيث سنقوم بملئه لاحقًا. بالنسبة إلى الحقول الأخرى، استخدِم القيم من frontend_service_cloudfunction_url، والتي تم عرضها بعد الإكمال الناجح لعملية نشر Terraform بتنسيق Prerequisite 1.6. يتّبع عنوان URL هذا التنسيق: https://
2. 2. درس تطبيقي حول الترميز الخاص بالاختبار المحلي
الوقت المقدّر لإنهاء الدرس: أقل من ساعة واحدة
يمكنك استخدام أداة الاختبار المحلي على جهازك لتجميع البيانات وإنشاء تقارير موجزة باستخدام تقارير تصحيح الأخطاء غير المشفَّرة. قبل البدء، تأكَّد من إكمال جميع المتطلبات الأساسية التي تحمل التصنيف "اختبار محلي".
خطوات الدرس التطبيقي حول الترميز
الخطوة 2.1: تشغيل التقرير: يمكنك تشغيل إعداد تقارير "التجميع الخاص" لتتمكّن من جمع التقرير.
الخطوة 2.2: إنشاء تقرير تصحيح الأخطاء AVRO: يمكنك تحويل تقرير JSON الذي تم جمعه إلى تقرير بتنسيق AVRO. ستكون هذه الخطوة مشابهة لتلك التي ستجمع فيها تكنولوجيا الإعلان التقارير من نقاط نهاية إعداد تقارير واجهة برمجة التطبيقات وتحوِّل تقارير JSON إلى تقارير بتنسيق AVRO.
الخطوة 2.3: استرداد مفاتيح الحزمة: صُممت مفاتيح الحزم من قِبل adTechs. في هذا الدرس التطبيقي حول الترميز، وبما أنّ المجموعات محدّدة مسبقًا، يمكنك استرداد مفاتيح الحزمة على النحو المقدَّم.
الخطوة 2.4: إنشاء نطاق الإخراج AVRO: بعد استرداد مفاتيح الحزمة، يمكنك إنشاء ملف AVRO لنطاق الإخراج.
الخطوة 2.5: إنشاء تقرير ملخّص: استخدِم "أداة الاختبار المحلي" لتتمكن من إنشاء تقارير ملخّص في البيئة المحلية.
الخطوة 2.6: مراجعة تقارير الملخّص: راجِع تقرير "الملخّص" الذي تم إنشاؤه بواسطة "أداة الاختبار المحلي".
2.1. تشغيل التقرير
لتشغيل تقرير تجميع خاص، يمكنك استخدام الموقع الإلكتروني التجريبي لـ "مبادرة حماية الخصوصية" (https://privacy-sandbox-demos-news.dev/?env=gcp) أو موقعك الإلكتروني الخاص (مثل https://adtechexample.com). إذا كنت تستخدم موقعك الإلكتروني ولم تُكمل عملية التسجيل إعداد خدمة المصادقة والتجميع، ستحتاج إلى استخدام مفتاح Chrome بعلامة Chrome ومفتاح واجهة سطر الأوامر.
في هذا العرض التوضيحي، سنستخدم الموقع الإلكتروني التجريبي لـ "مبادرة حماية الخصوصية". اتّبِع الرابط للانتقال إلى الموقع الإلكتروني. بعد ذلك، يمكنك عرض التقارير على chrome://private-aggregation-internals:
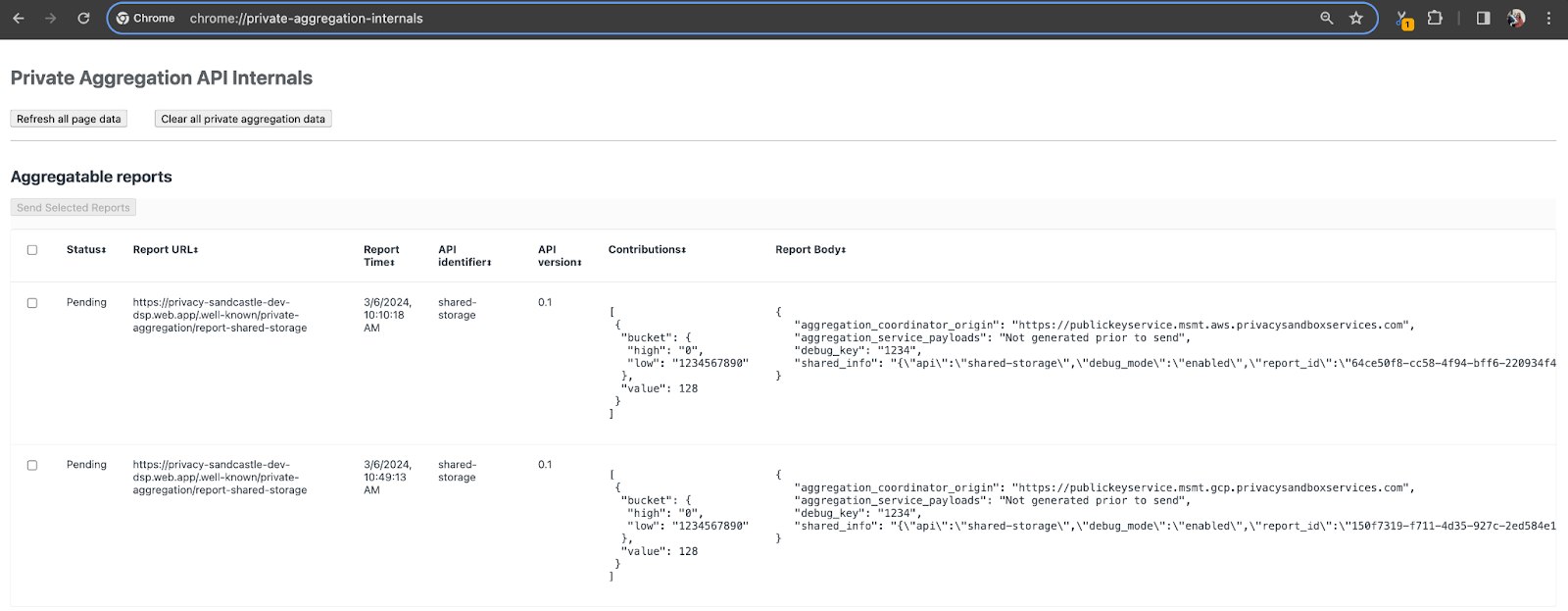
التقرير الذي يتم إرساله إلى نقطة نهاية {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage يمكن العثور عليه أيضًا في "نص التقرير". من التقارير المعروضة في صفحة "إعدادات Chrome الداخلية".
قد تظهر لك العديد من التقارير هنا، ولكن في هذا الدرس التطبيقي، يمكنك استخدام التقرير القابل للتجميع الخاص بخدمة Google Cloud Platform والذي تنشئه نقطة نهاية تصحيح الأخطاء. "عنوان URL للإبلاغ" سيحتوي على "/debug/" وaggregation_coordinator_origin field في "نص التقرير" على عنوان URL هذا: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
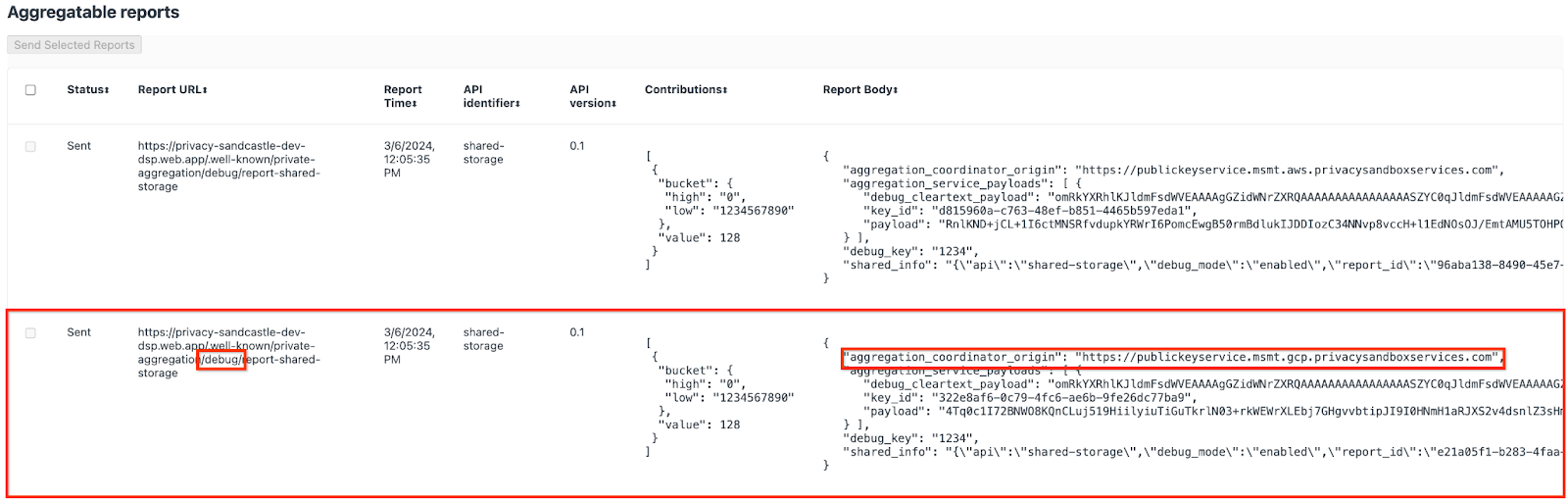
2.2. إنشاء تقرير مجمّع لتصحيح الأخطاء
انسخ التقرير الذي تم العثور عليه في "نص التقرير" من chrome://private-aggregation-internals وأنشِئ ملف JSON في المجلد privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (ضمن المستودع الذي تم تنزيله في الإصدار 1.5 من المتطلبات الأساسية).
في هذا المثال، نستخدم vim لأننا نستخدم linux. ولكن يمكنك استخدام أي محرر نصوص تريده.
vim report.json
الصق التقرير في report.json واحفظ ملفك.

بعد الحصول على ذلك، يمكنك استخدام aggregatable_report_converter.jar للمساعدة في إنشاء تقرير تصحيح الأخطاء القابل للتجميع. يؤدي هذا إلى إنشاء تقرير قابل للتجميع يسمى report.avro في الدليل الحالي.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. استرداد مفتاح الحزمة من التقرير
لإنشاء ملف output_domain.avro، ستحتاج إلى مفاتيح الحزمة التي يمكن استردادها من التقارير.
صمّمت شركة adTech مفاتيح الحزم. مع ذلك، في هذه الحالة، ينشئ الموقع الإلكتروني الإصدار التجريبي من "مبادرة حماية الخصوصية" مفاتيح الحزمة. بما أنّ التجميع الخاص لهذا الموقع الإلكتروني في وضع تصحيح الأخطاء، يمكننا استخدام debug_cleartext_payload من "نص التقرير". للحصول على مفتاح الحزمة.
تابع وانسخ debug_cleartext_payload من نص التقرير.

افتح goo.gle/ags-payload-decoder والصِق debug_cleartext_payload في الحقل "INPUT". وانقر على "فك التشفير".
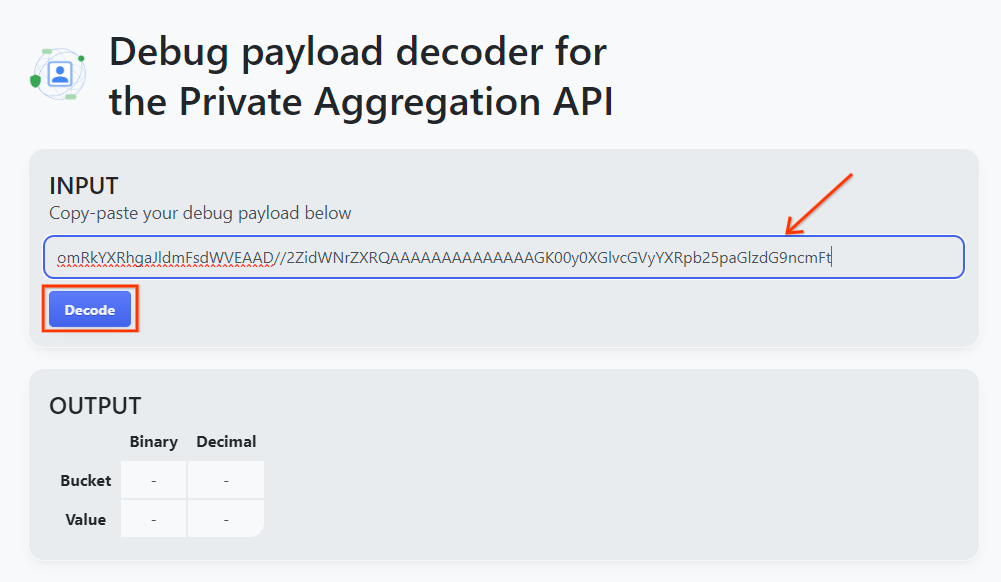
تعرض الصفحة القيمة العشرية لمفتاح الحزمة. في ما يلي نموذج لمفتاح حزمة.
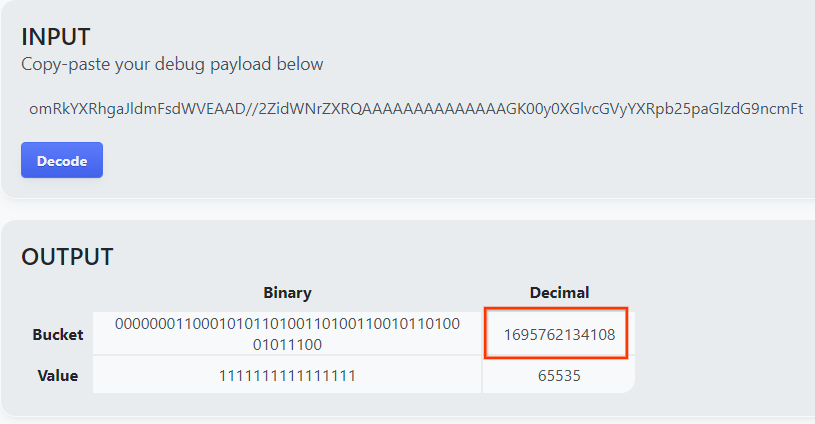
2.4. إنشاء نطاق الإخراج AVRO
الآن بعد أن أصبح لدينا مفتاح bucket، لننشئ output_domain.avro في المجلد نفسه الذي كنا نعمل عليه. تأكد من استبدال مفتاح الحزمة بمفتاح الحزمة الذي تم استرداده.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
ينشئ النص البرمجي ملف output_domain.avro في المجلد الحالي.
2.5. إنشاء تقارير ملخّصة باستخدام "أداة الاختبار المحلي"
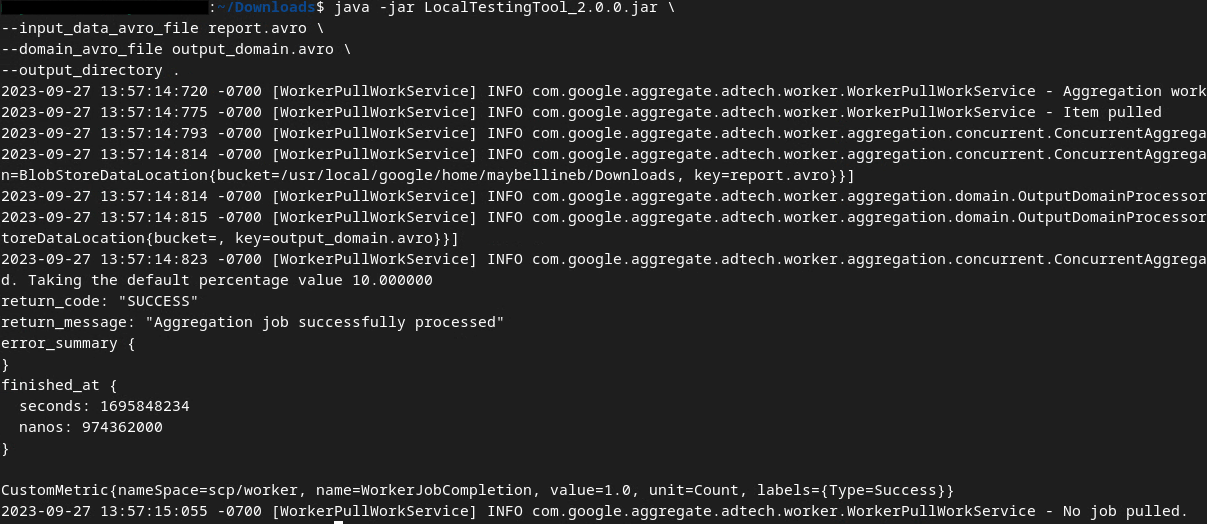
سنستخدم LocalTestingTool_{version}.jar الذي تم تنزيله في الإصدار 1.3 من المتطلبات الأساسية لإنشاء تقارير الملخّص باستخدام الأمر أدناه. استبدِل {version} بالنسخة التي نزَّلتها. تذكَّر نقل LocalTestingTool_{version}.jar إلى الدليل الحالي، أو إضافة مسار نسبي للإشارة إلى موقعه الحالي.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
من المفترض أن يظهر لك شيء مشابه لما يرد أدناه بعد تشغيل الأمر. يتم إنشاء تقرير output.avro بعد اكتمال هذا الإجراء.
2.6. مراجعة تقرير الملخص
يكون تقرير الملخص الذي يتم إنشاؤه بتنسيق AVRO. لتتمكّن من قراءة هذا النص، يجب تحويله من AVRO إلى تنسيق JSON. من المفترَض أن تكتب adTech رمزًا برمجيًا لتحويل تقارير AVRO إلى تنسيق JSON.
سنستخدم aggregatable_report_converter.jar لتحويل تقرير AVRO إلى تنسيق JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
وسيؤدي ذلك إلى عرض تقرير مشابه لما يرد أدناه. بالإضافة إلى تقرير output.json تم إنشاؤه في الدليل نفسه.

اكتملت الدرس التطبيقي حول الترميز
ملخّص: لقد جمعت تقرير تصحيح أخطاء، وأنشأت ملف نطاق إخراج، وأنشأت تقريرًا ملخّصًا باستخدام أداة الاختبار المحلية التي يحاكي سلوك التجميع لخدمة التجميع.
الخطوات التالية: الآن بعد أن جرّبت أداة الاختبار المحلي، يمكنك تجربة التمرين نفسه مع نشر مباشر لخدمة التجميع في بيئتك الخاصة. راجِع المتطلبات الأساسية للتأكّد من إعداد كل شيء من أجل "خدمة التجميع". ثم تابع إلى الخطوة 3.
3- 3- درس تطبيقي حول ترميز خدمة التجميع
الوقت المقدّر لإنهاء الدرس: ساعة واحدة
قبل البدء، تأكَّد من إكمال جميع المتطلبات الأساسية التي تحمل التصنيف "خدمة التجميع".
خطوات الدرس التطبيقي حول الترميز
الخطوة 3.1: إنشاء مدخلات خدمة التجميع: يمكنك إنشاء تقارير "خدمة التجميع" التي يتم تجميعها لخدمة التجميع.
- الخطوة 3.1.1. تشغيل التقرير
- الخطوة 3.1.2. جمع التقارير القابلة للتجميع
- الخطوة 3.1.3. تحويل التقارير إلى AVRO
- الخطوة 3.1.4. إنشاء AVRO لنطاق المخرجات
- الخطوة 3.1.5. نقل التقارير إلى حزمة Cloud Storage
الخطوة 3.2: استخدام خدمة التجميع: استخدِم واجهة برمجة تطبيقات خدمة التجميع لإنشاء تقارير الملخّص ومراجعة تقارير الملخّص.
- الخطوة 3.2.1. جارٍ استخدام نقطة نهاية واحدة (
createJob) للتجميع - الخطوة 3.2.2. يتم استخدام نقطة النهاية
getJobلاسترداد حالة الدُفعة. - الخطوة 3.2.3. مراجعة تقرير الملخص
3.1. إنشاء مدخلات خدمة التجميع
واصِل إنشاء تقارير AVRO لتجميعها على "خدمة التجميع". يمكن تشغيل أوامر واجهة المستخدم في هذه الخطوات من خلال Cloud Shell في Google Cloud Platform (طالما يتم استنساخ التبعيات من المتطلبات الأساسية في بيئة Cloud Shell) أو في بيئة تنفيذ محلية.
3.1.1. تشغيل التقرير
اتّبِع الرابط للانتقال إلى الموقع الإلكتروني. بعد ذلك، يمكنك عرض التقارير على chrome://private-aggregation-internals:
التقرير الذي يتم إرساله إلى نقطة نهاية {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage يمكن العثور عليه أيضًا في "نص التقرير". من التقارير المعروضة في صفحة "إعدادات Chrome الداخلية".
قد تظهر لك العديد من التقارير هنا، ولكن في هذا الدرس التطبيقي، يمكنك استخدام التقرير القابل للتجميع الخاص بخدمة Google Cloud Platform والذي تنشئه نقطة نهاية تصحيح الأخطاء. "عنوان URL للإبلاغ" سيحتوي على "/debug/" وaggregation_coordinator_origin field في "نص التقرير" على عنوان URL هذا: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. جمع التقارير القابلة للتجميع
جمِّع التقارير القابلة للتجميع من نقاط نهاية .well-known في واجهة برمجة التطبيقات المقابلة.
- تجميع خاص:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - إعداد تقارير تحديد المصدر - تقرير الملخّص:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
في هذا الدرس التطبيقي حول الترميز، نجري جمع التقارير يدويًا. في مرحلة الإنتاج، من المتوقّع أن تجمع تكنولوجيات الإعلان التقارير وتحوِّلها آليًا.
لننسخ تقرير JSON في "نص التقرير". ابتداءً من chrome://private-aggregation-internals
في هذا المثال، نستخدم vim لأننا نستخدم linux. ولكن يمكنك استخدام أي محرر نصوص تريده.
vim report.json
الصق التقرير في report.json واحفظ ملفك.
3.1.3. تحويل التقارير إلى AVRO
تكون التقارير المُستلَمة من نقاط النهاية .well-known بتنسيق JSON ويجب تحويلها إلى تنسيق تقرير AVRO. بعد توفُّر تقرير JSON، انتقِل إلى مكان تخزين report.json واستخدِم aggregatable_report_converter.jar للمساعدة في إنشاء تقرير تصحيح الأخطاء القابل للتجميع. يؤدي هذا إلى إنشاء تقرير قابل للتجميع يسمى report.avro في الدليل الحالي.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. إنشاء AVRO لنطاق المخرجات
لإنشاء ملف output_domain.avro، ستحتاج إلى مفاتيح الحزمة التي يمكن استردادها من التقارير.
صمّمت شركة adTech مفاتيح الحزم. مع ذلك، في هذه الحالة، ينشئ الموقع الإلكتروني الإصدار التجريبي من "مبادرة حماية الخصوصية" مفاتيح الحزمة. بما أنّ التجميع الخاص لهذا الموقع الإلكتروني في وضع تصحيح الأخطاء، يمكننا استخدام debug_cleartext_payload من "نص التقرير". للحصول على مفتاح الحزمة.
تابع وانسخ debug_cleartext_payload من نص التقرير.
افتح goo.gle/ags-payload-decoder والصِق debug_cleartext_payload في الحقل "INPUT". وانقر على "فك التشفير".
تعرض الصفحة القيمة العشرية لمفتاح الحزمة. في ما يلي نموذج لمفتاح حزمة.
الآن بعد أن أصبح لدينا مفتاح bucket، لننشئ output_domain.avro في المجلد نفسه الذي كنا نعمل عليه. تأكد من استبدال مفتاح الحزمة بمفتاح الحزمة الذي تم استرداده.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
ينشئ النص البرمجي ملف output_domain.avro في المجلد الحالي.
3.1.5. نقل التقارير إلى حزمة Cloud Storage
بعد إنشاء تقارير AVRO ونطاق الناتج، تابِع نقل التقارير ونطاق الإخراج إلى الحزمة في Cloud Storage (المذكورة في الإصدار 1.6 من المتطلبات الأساسية).
في حال إعداد gcloud CLI في بيئتك المحلية، استخدِم الأوامر أدناه لنسخ الملفات إلى المجلدات المقابلة.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
ويمكنك بدلاً من ذلك تحميل الملفات يدويًا إلى حزمتك. إنشاء مجلد باسم "التقارير" وتحميل ملف report.avro هناك. إنشاء مجلد باسم "output_domains" وتحميل ملف output_domain.avro هناك.
3.2. استخدام خدمة التجميع
في الإصدار 1.8 من المتطلبات الأساسية، اختَر إما cURL أو Postman لإرسال طلبات بيانات من واجهة برمجة التطبيقات إلى نقاط نهاية خدمة التجميع. ستجد أدناه تعليمات لكلا الخيارين.
إذا فشلت مهمتك نتيجة خطأ، يمكنك الاطّلاع على وثائق تحديد المشاكل وحلّها في GitHub للحصول على مزيد من المعلومات حول كيفية المتابعة.
3.2.1. جارٍ استخدام نقطة نهاية واحدة (createJob) للتجميع
استخدِم تعليمات cURL أو Postman أدناه لإنشاء مهمة.
cURL
في "المحطة الطرفية"، أنشِئ ملف نص الطلب (body.json) والصِقه أدناه. تأكَّد من تعديل قيم العنصر النائب. يُرجى الاطّلاع على مستندات واجهة برمجة التطبيقات هذه لمزيد من المعلومات حول ما يمثّله كل حقل.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
نفِّذ الطلب أدناه. يمكنك استبدال العناصر النائبة في عنوان URL لطلب cURL بالقيم الواردة من frontend_service_cloudfunction_url، والتي تظهر بعد اكتمال عملية نشر Terraform بنجاح في الإصدار 1.6 من المتطلبات الأساسية.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
ومن المفترض أن تتلقى استجابة HTTP 202 بعد قبول الطلب بواسطة خدمة التجميع. تم توثيق رموز الاستجابة المحتملة الأخرى في مواصفات واجهة برمجة التطبيقات.
Postman
بالنسبة إلى نقطة النهاية createJob، يجب إدخال نص طلب لتزويد "خدمة التجميع" بأسماء المواقع الجغرافية وأسماء الملفات للتقارير القابلة للتجميع ونطاقات الناتج والتقارير التلخيصية.
الانتقال إلى "نص" طلب createJob :

استبدِل العناصر النائبة ضمن ملف JSON المقدَّم. لمزيد من المعلومات عن هذه الحقول وما تمثّله، يمكنك الرجوع إلى مستندات واجهة برمجة التطبيقات.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"إرسال" طلب بيانات من واجهة برمجة التطبيقات createJob:

يمكن العثور على رمز الاستجابة في النصف السفلي من الصفحة:

ومن المفترض أن تتلقى استجابة HTTP 202 بعد قبول الطلب بواسطة خدمة التجميع. تم توثيق رموز الاستجابة المحتملة الأخرى في مواصفات واجهة برمجة التطبيقات.
3.2.2. يتم استخدام نقطة النهاية getJob لاسترداد حالة الدُفعة.
يمكنك استخدام تعليمات cURL أو Postman أدناه للحصول على وظيفة.
cURL
نفِّذ الطلب أدناه في محطة الدفع. استبدِل العناصر النائبة في عنوان URL بالقيم من frontend_service_cloudfunction_url، وهو عنوان URL نفسه الذي استخدمته في طلب createJob. بالنسبة إلى "job_request_id"، استخدِم القيمة من المهمة التي أنشأتها باستخدام نقطة النهاية createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
من المفترض أن تعرض النتيجة حالة طلب المهمة وحالة HTTP هي 200. "النص الأساسي" للطلب يحتوي على المعلومات الضرورية، مثل job_status وreturn_message وerror_messages (إذا حدث خطأ في المهمة).
Postman
للتحقّق من حالة طلب المهمة، يمكنك استخدام نقطة النهاية getJob. فِي حَرَكَاتِ الْمُشَاهَدَاتْ في طلب getJob، يمكنك تعديل القيمة job_request_id إلى job_request_id التي تم إرسالها في طلب createJob.
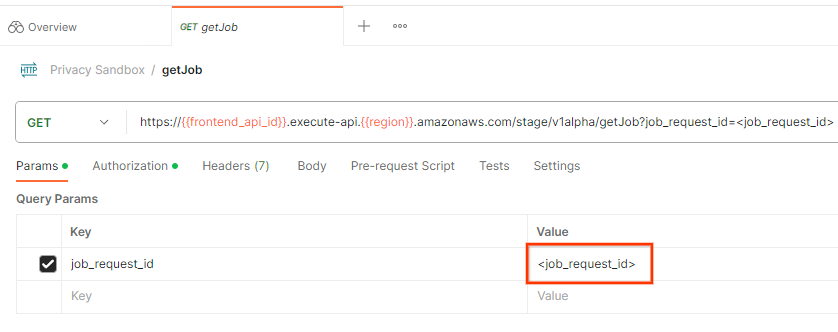
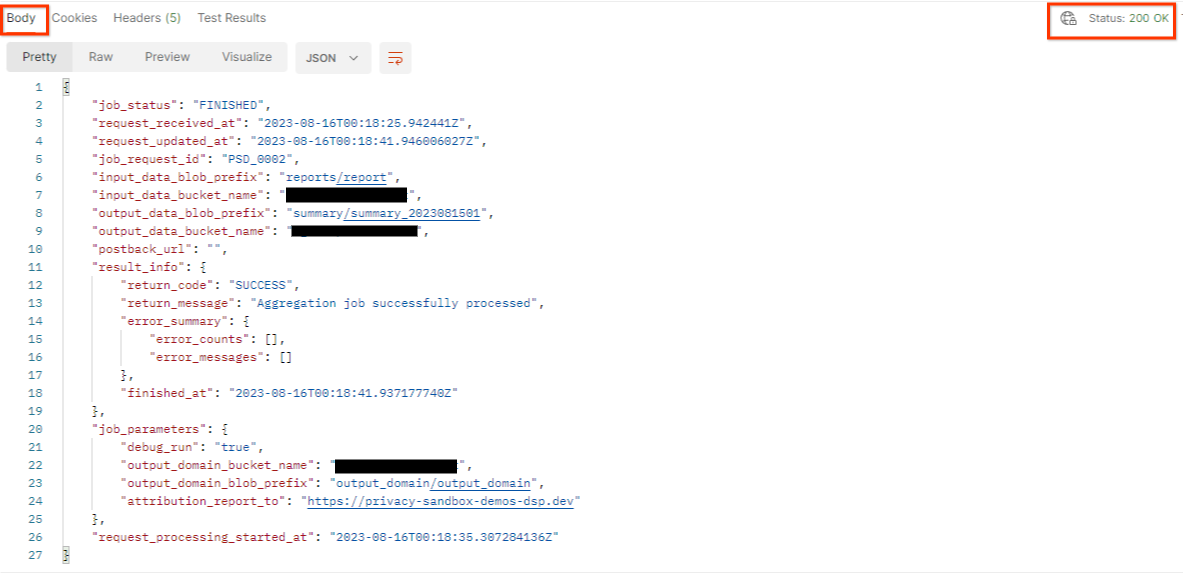
"إرسال" طلب getJob:

من المفترض أن تعرض النتيجة حالة طلب المهمة وحالة HTTP هي 200. "النص الأساسي" للطلب يحتوي على المعلومات الضرورية، مثل job_status وreturn_message وerror_messages (إذا حدث خطأ في المهمة).
3.2.3. مراجعة تقرير الملخص
بعد تلقّي التقرير الملخّص في حزمة Cloud Storage المُخرجة، يمكنك تنزيل هذا التقرير في بيئتك المحلية. تكون تقارير الملخّص بتنسيق AVRO ويمكن تحويلها إلى تنسيق JSON. يمكنك استخدام aggregatable_report_converter.jar لقراءة تقريرك باستخدام الأمر أدناه.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
يؤدي ذلك إلى عرض ملف json بالقيم المجمّعة لكل مفتاح حزمة يبدو مشابهًا لما يرد أدناه.

إذا كان طلب createJob يتضمّن debug_run على القيمة "صحيح"، يمكنك تلقّي تقرير الملخص في مجلد تصحيح الأخطاء المتوفّر في output_data_blob_prefix. يكون التقرير بتنسيق AVRO ويمكن تحويله باستخدام الأمر أعلاه إلى JSON.
يحتوي التقرير على مفتاح الحزمة والمقياس غير المصوَّر والتشويش الذي تتم إضافته إلى المقياس غير المصوَّر لتكوين تقرير الملخّص. يشبه التقرير ما يلي.

تحتوي التعليقات التوضيحية أيضًا على "in_reports" و/أو "in_domain" ويعني ذلك ما يلي:
- in_reports - يتوفر مفتاح الحزمة في التقارير القابلة للتجميع.
- in_domain - يتوفر مفتاح الحزمة في ملف exit_domain AVRO.
اكتملت الدرس التطبيقي حول الترميز
الملخّص: لقد نشرت "خدمة التجميع" في بيئتك السحابية الخاصة بك، وجمعت تقرير تصحيح أخطاء، وأنشأت ملف نطاق إخراج، وخزّنت هذه الملفات في حزمة على Cloud Storage، ونفّذت مهمة ناجحة.
الخطوات التالية: يمكنك مواصلة استخدام "خدمة التجميع" في بيئتك، أو حذف موارد السحابة الإلكترونية التي أنشأتها للتو باتّباع تعليمات التنظيف في الخطوة 4.
4. 4. الإزالة
لحذف الموارد التي تم إنشاؤها لخدمة التجميع من خلال Terraform، يمكنك استخدام أمر التدمير في المجلد adtech_setup وdev (أو بيئة أخرى):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
لحذف حزمة Cloud Storage التي تتضمّن التقارير القابلة للتجميع وتقارير الملخّص:
$ gcloud storage buckets delete gs://my-bucket
يمكنك أيضًا اختيار إعادة إعدادات ملفات تعريف الارتباط في Chrome من الشرط الأساسي 1.2 إلى حالته السابقة.
5- 5- الملحق
مثال على ملف adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
مثال على ملف dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20