
1. 1. Prerequisites
Estimated time to complete: 1-2 hours
There are 2 modes for performing this codelab: Local Testing or Aggregation Service. The Local Testing mode requires a local machine and Chrome browser (no Google Cloud resource creation/usage). The Aggregation Service mode requires a full deployment of the Aggregation Service on Google Cloud.
To perform this codelab in either mode, a few prerequisites are required. Each requirement is marked accordingly whether it is required for Local Testing or Aggregation Service.
1.1. Complete Enrollment and Attestation (Aggregation Service)
To use Privacy Sandbox APIs, ensure that you have completed the Enrollment and Attestation for both Chrome and Android.
1.2. Enable Ad privacy APIs (Local Testing and Aggregation Service)
Since we will be using the Privacy Sandbox, we encourage you to enable the Privacy Sandbox Ads APIs.
On your browser, go to chrome://settings/adPrivacy and enable all the Ad privacy APIs.
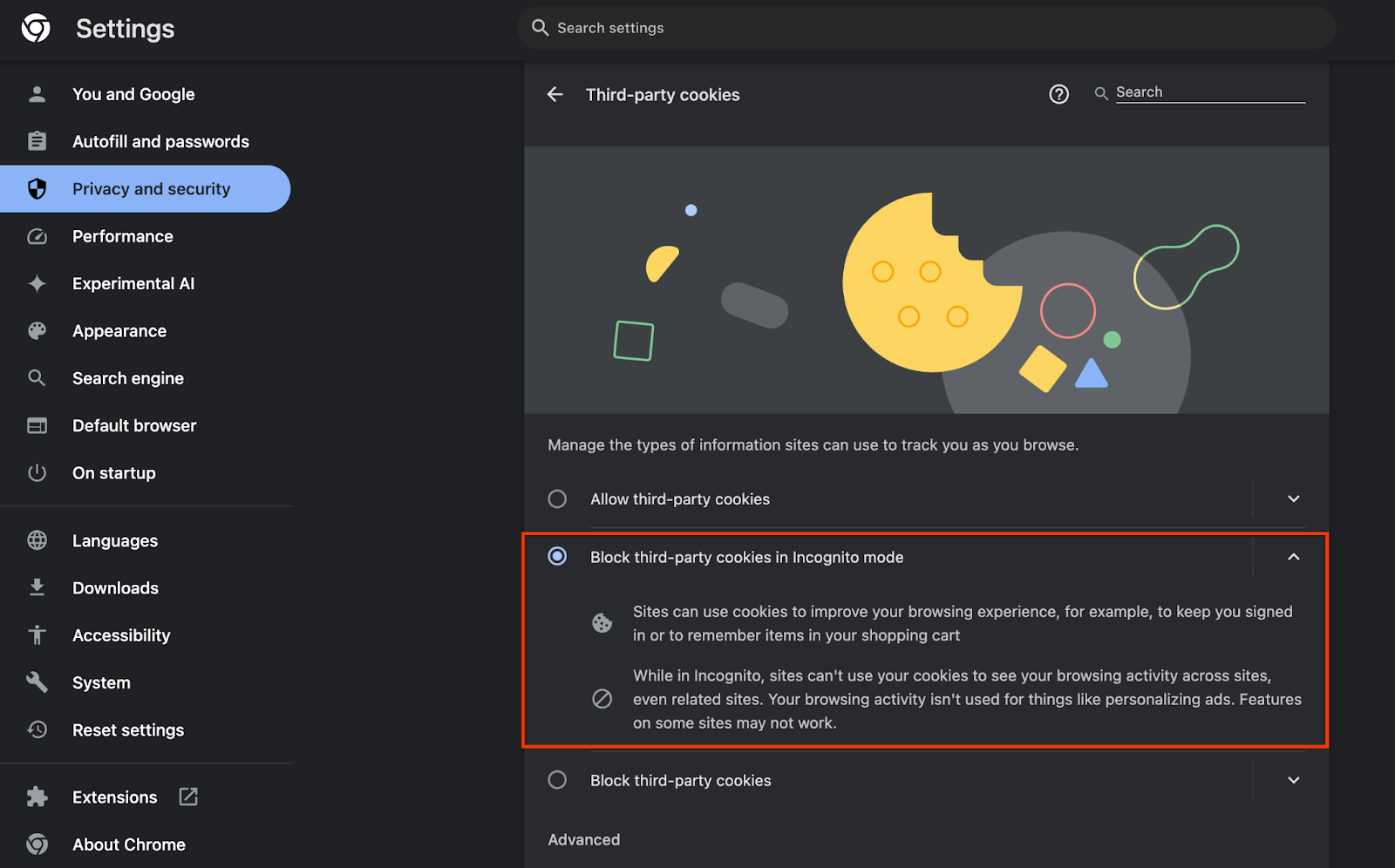
Also ensure that your third-party cookies are enabled.
From chrome://settings/cookies, make sure third-party cookies are NOT being blocked. Depending on your Chrome version, you may see different options on this settings menu, but acceptable configurations include:
- "Block all third-party cookies" = DISABLED
- "Block third-party cookies" = DISABLED
- "Block third-party cookies in Incognito mode" = ENABLED
1.3. Download the Local Testing Tool (Local Testing)
Local Testing will require the download of the Local Testing Tool. The tool will generate summary reports from the unencrypted debug reports.
Local Testing tool is available for download in the Cloud Function JAR Archives in GitHub. It should be named as LocalTestingTool_{version}.jar.
1.4. Ensure JAVA JRE is installed (Local Testing and Aggregation Service)
Open "Terminal" and use java --version to check if your machine has Java or openJDK installed.

If it is not installed, you can download and install from the Java site or the openJDK site.
1.5. Download aggregatable_report_converter (Local Testing and Aggregation Service)
You can download a copy of the aggregatable_report_converter from the Privacy Sandbox Demos GitHub repository. The GitHub repository mentions using IntelliJ or Eclipse, but neither are required. If you don't use these tools, download the JAR file to your local environment instead.
1.6. Set up a GCP Environment (Aggregation Service)
Aggregation Service requires the use of a Trusted Execution Environment which uses a cloud provider. In this codelab, Aggregation Service will be deployed in GCP, but AWS is also supported.
Follow the Deployment Instructions in GitHub to setup the gcloud CLI, download Terraform binaries and modules, and create GCP resources for Aggregation Service.
Key steps in the Deployment Instructions:
- Set up the "gcloud" CLI and Terraform in your environment.
- Create a Cloud Storage bucket to store Terraform state.
- Download dependencies.
- Update
adtech_setup.auto.tfvarsand run theadtech_setupTerraform. See Appendix for an exampleadtech_setup.auto.tfvarsfile. Note the name of the data bucket that is created here – this will be used in the codelab to store the files we create. - Update
dev.auto.tfvars, impersonate the deploy service account, and run thedevTerraform. See Appendix for an exampledev.auto.tfvarsfile. - Once the deployment is complete, capture the
frontend_service_cloudfunction_urlfrom the Terraform output, which will be needed to make requests to the Aggregation Service in later steps.
1.7. Complete Aggregation Service Onboarding (Aggregation Service)
Aggregation Service requires onboarding to coordinators to be able to use the service. Complete the Aggregation Service Onboarding form by providing your Reporting Site and other information, selecting "Google Cloud", and entering your service account address. This service account gets created in the previous prerequisite (1.6. Set up a GCP Environment). (Hint: if you use the default names provided, this service account will start with "worker-sa@").
Allow up to 2 weeks for the onboarding process to be completed.
1.8. Determine your method for calling the API endpoints (Aggregation Service)
This codelab provides 2 options for calling the Aggregation Service API endpoints: cURL and Postman. cURL is the quicker and easier way to call the API endpoints from your Terminal, since it requires minimal setup and no additional software. However, if you don't want to use cURL, you can instead use Postman to execute and save API requests for future use.
In section 3.2. Aggregation Service Usage, you'll find detailed instructions for using both options. You may preview them now to determine which method you'll use. If you select Postman, perform the following initial setup.
1.8.1. Set up workspace
Sign up for a Postman account. Once signed up, a workspace is automatically created for you.
If a workspace is not created for you, go to "Workspaces" top navigation item and select "Create Workspace".
Select "Blank workspace", click next and name it "GCP Privacy Sandbox". Select "Personal" and click "Create".
Download the pre-configured workspace JSON configuration and Global Environment files.
Import both JSON files into "My Workspace" via the "Import" button.

This will create the "GCP Privacy Sandbox" collection for you along with the createJob and getJob HTTP requests.
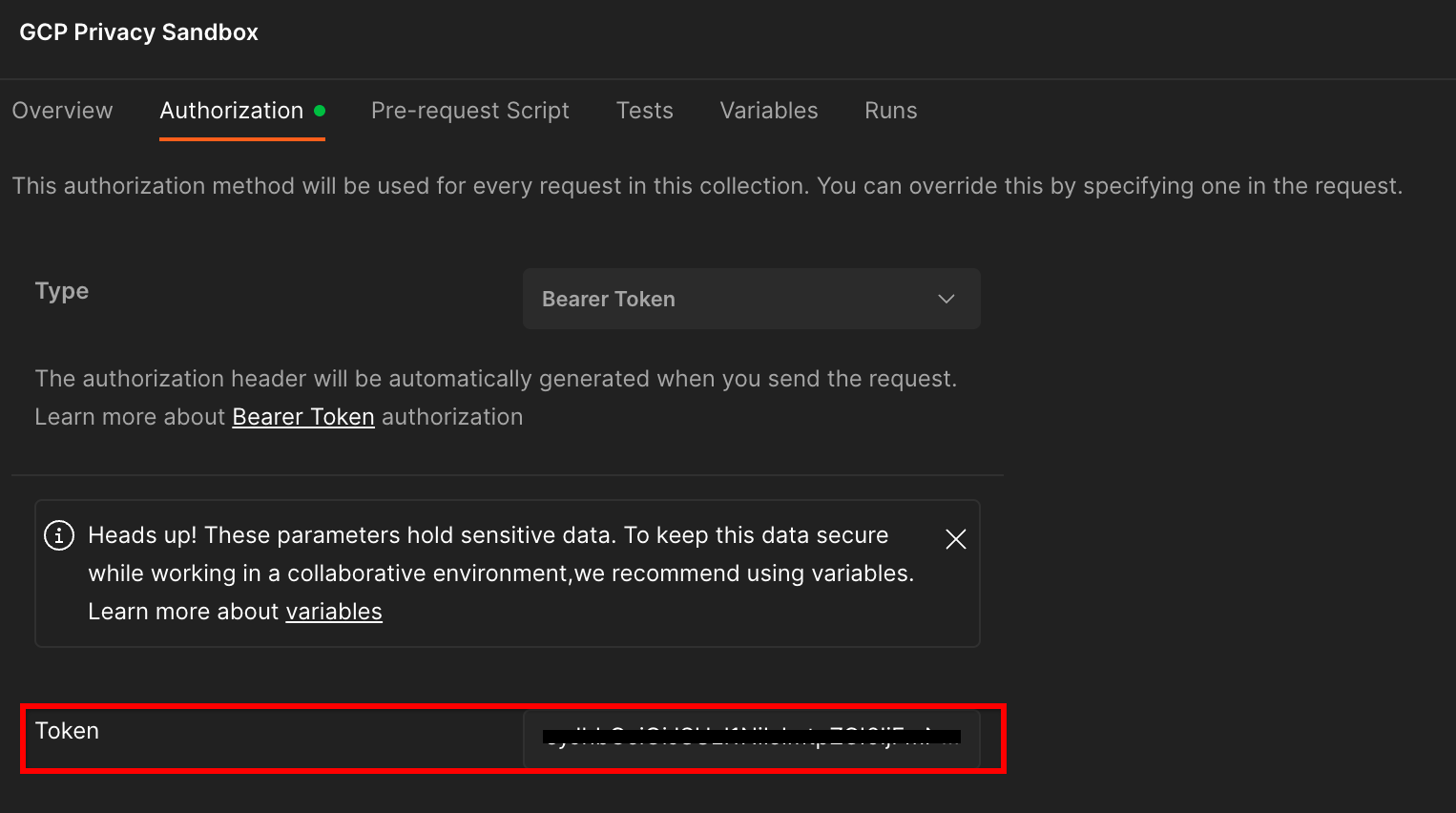
1.8.2. Set up authorization
Click the "GCP Privacy Sandbox" collection and navigate to the "Authorization" tab.

You'll use the "Bearer Token" method. From your Terminal environment, run this command and copy the output.
gcloud auth print-identity-token
Then, paste this token value in the "Token" field of the Postman authorization tab:
1.8.3. Set up environment
Navigate to the "Environment quick look" in the top-right corner:
Click "Edit" and update the "Current Value" of "environment", "region", and "cloud-function-id":
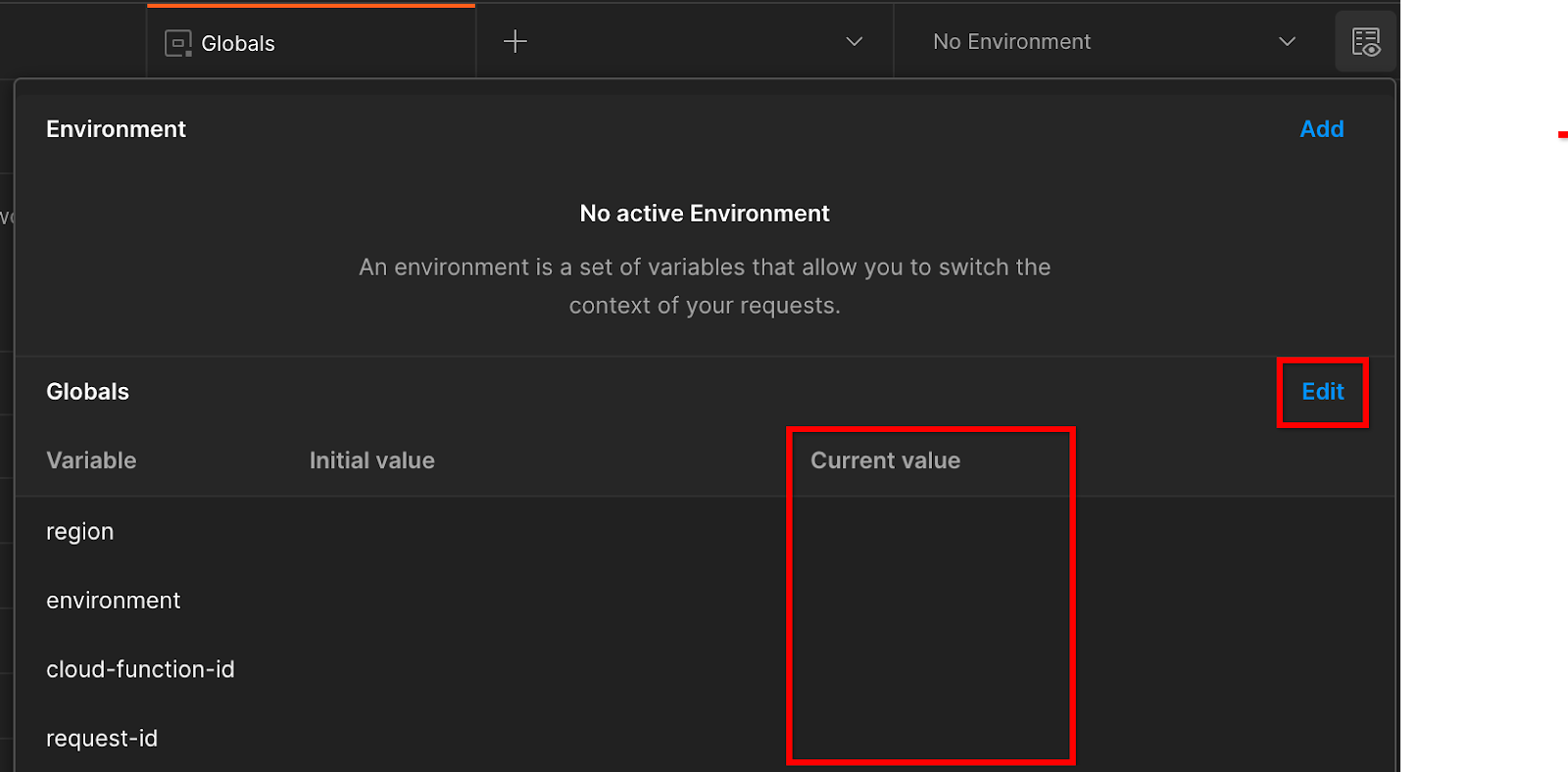
You can leave "request-id" blank for now, as we'll fill it in later. For the other fields, use the values from the frontend_service_cloudfunction_url, which was returned from the successful completion of the Terraform deployment in Prerequisite 1.6. The URL follows this format: https://
2. 2. Local Testing Codelab
Estimated time to complete: <1 hour
You can use the local testing tool on your machine to perform aggregation and generate summary reports using the unencrypted debug reports. Before you begin, ensure that you've completed all Prerequisites labeled with "Local Testing".
Codelab steps
Step 2.1. Trigger report: Trigger Private Aggregation reporting to be able to collect the report.
Step 2.2. Create Debug AVRO Report: Convert the collected JSON report to an AVRO formatted report. This step will be similar to when adTechs collect the reports from the API reporting endpoints and convert the JSON reports to AVRO formatted reports.
Step 2.3. Retrieve the Bucket Keys: Bucket keys are designed by adTechs. In this codelab, since the buckets are pre-defined, retrieve the bucket keys as provided.
Step 2.4. Create Output Domain AVRO: Once the bucket keys are retrieved, create the Output Domain AVRO file.
Step 2.5. Create Summary Report: Use the Local Testing Tool to be able to create Summary Reports in the Local Environment.
Step 2.6. Review the Summary Reports: Review the Summary Report that is created by the Local Testing Tool.
2.1. Trigger report
To trigger a private aggregation report, you can use the Privacy Sandbox demo site (https://privacy-sandbox-demos-news.dev/?env=gcp) or your own site (e.g., https://adtechexample.com). If you're using your own site and you have not completed Enrollment & Attestation and Aggregation Service Onboarding, you will need to use a Chrome flag and CLI switch.
For this demo, we'll use the Privacy Sandbox demo site. Follow the link to go to the site; then, you can view the reports at chrome://private-aggregation-internals:
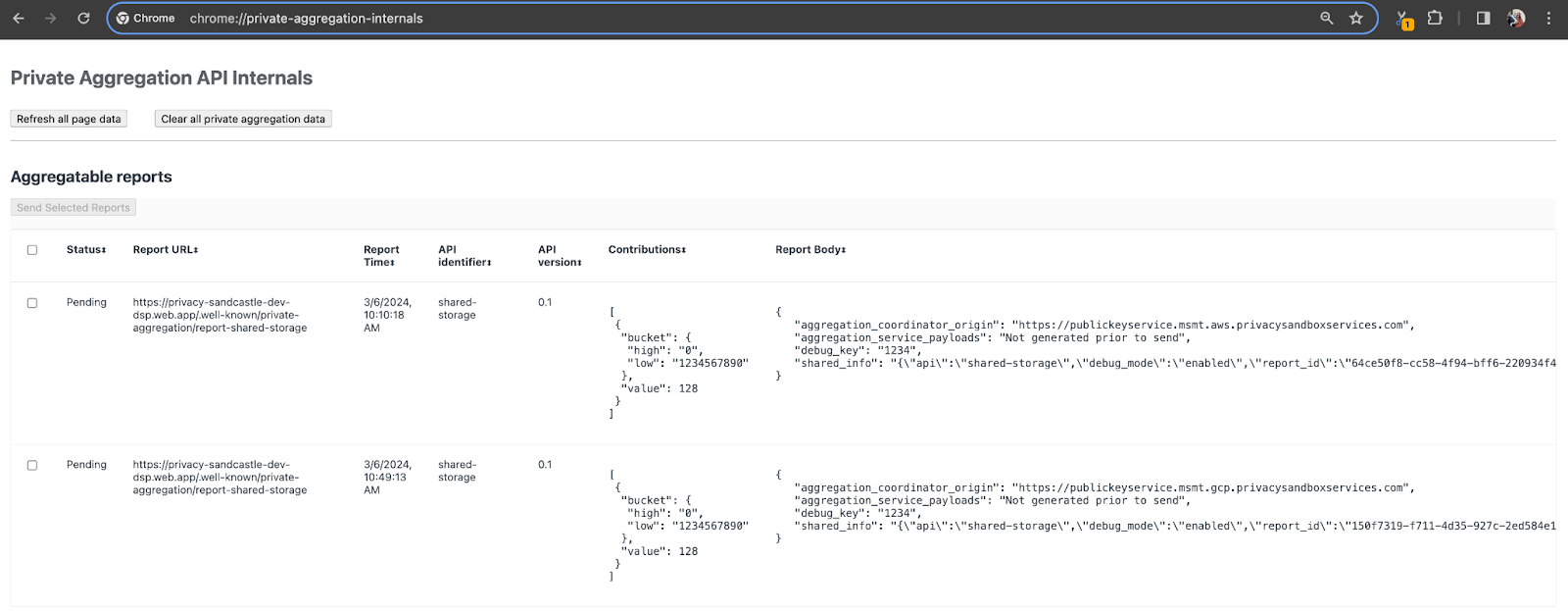
The report that is sent to the {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage endpoint is also found in the "Report Body" of the reports displayed on the Chrome Internals page.
You may see many reports here, but for this codelab, use the aggregatable report that is GCP-specific and generated by the debug endpoint. The "Report URL" will contain "/debug/" and the aggregation_coordinator_origin field of the "Report Body" will contain this URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
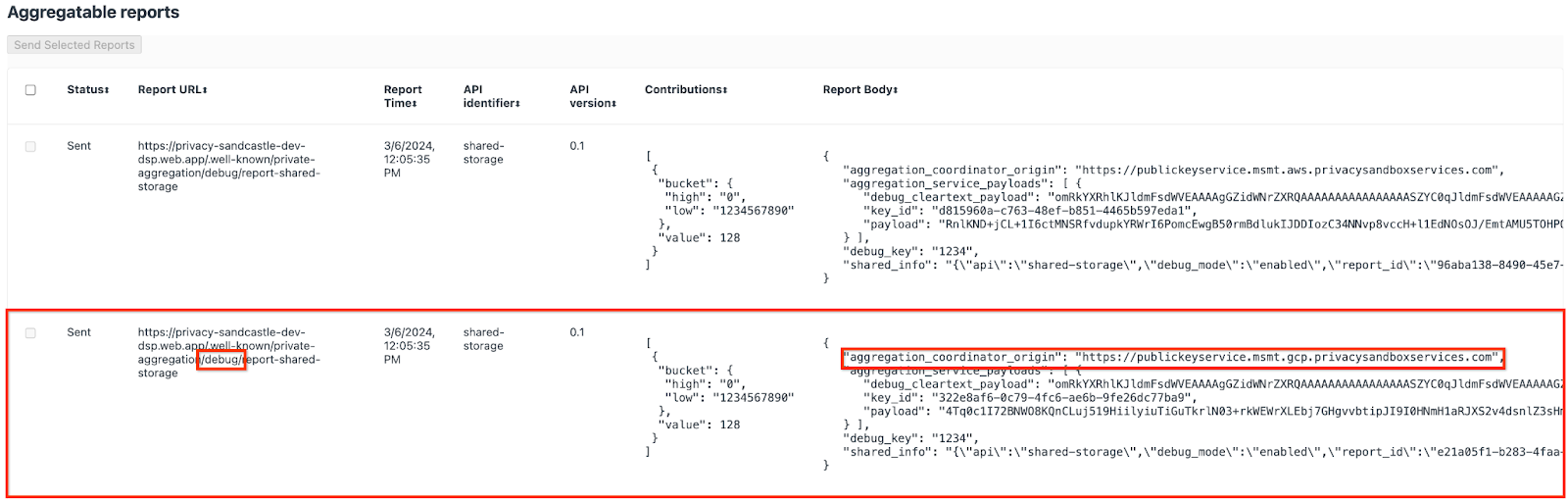
2.2. Create Debug Aggregatable Report
Copy the report found in the "Report Body" of chrome://private-aggregation-internals and create a JSON file in the privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar folder (within the repo downloaded in Prerequisite 1.5).
In this example, we're using vim since we are using linux. But you can use any text editor you want.
vim report.json
Paste the report into report.json and save your file.

Once you have that, use aggregatable_report_converter.jar to help create the debug aggregatable report. This creates an aggregatable report called report.avro in your current directory.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Retrieve the Bucket Key from Report
To create the output_domain.avro file, you need the bucket keys that can be retrieved from the reports.
Bucket keys are designed by the adTech. However, in this case, the site Privacy Sandbox Demo creates the bucket keys. Since private aggregation for this site is in debug mode, we can use the debug_cleartext_payload from the "Report Body" to get the bucket key.
Go ahead and copy the debug_cleartext_payload from the report body.

Open goo.gle/ags-payload-decoder and paste your debug_cleartext_payload in the "INPUT" box and click "Decode".
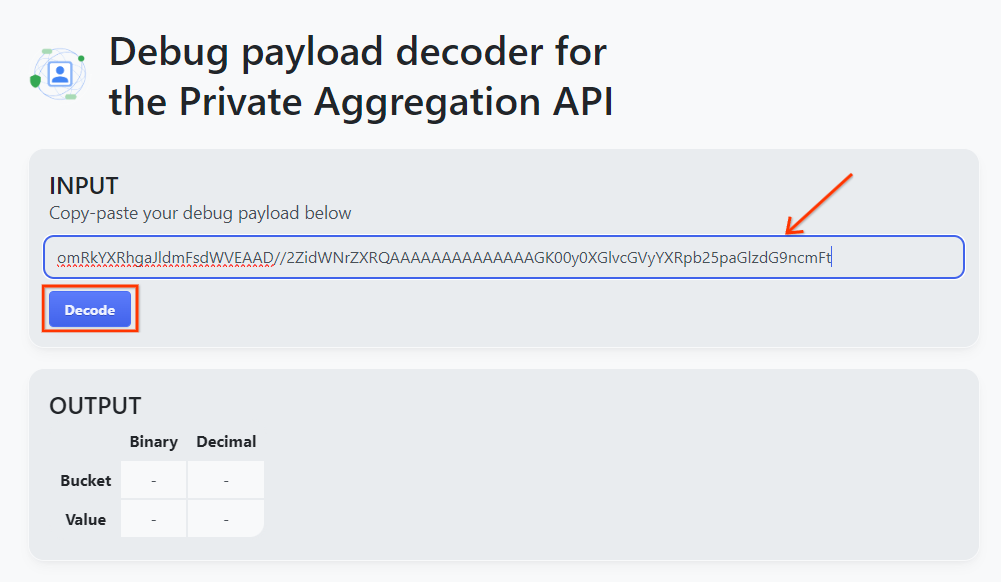
The page returns the decimal value of the bucket key. The below is a sample bucket key.
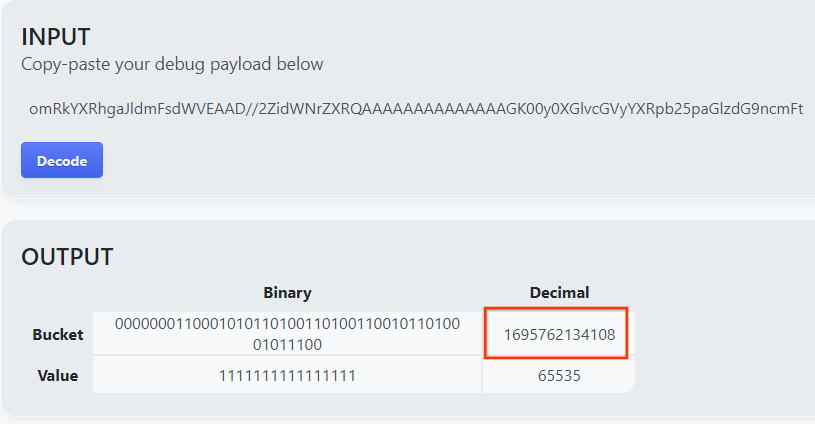
2.4. Create Output Domain AVRO
Now that we have the bucket key, let's create the output_domain.avro in the same folder we've been working in. Ensure that you replace bucket key with the bucket key you retrieved.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
The script creates the output_domain.avro file in your current folder.
2.5. Create Summary Reports using Local Testing Tool
We'll use LocalTestingTool_{version}.jar that was downloaded in Prerequisite 1.3 to create the summary reports using the below command. Replace {version} with the version you downloaded. Remember to move LocalTestingTool_{version}.jar to the current directory, or add a relative path to reference its current location.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
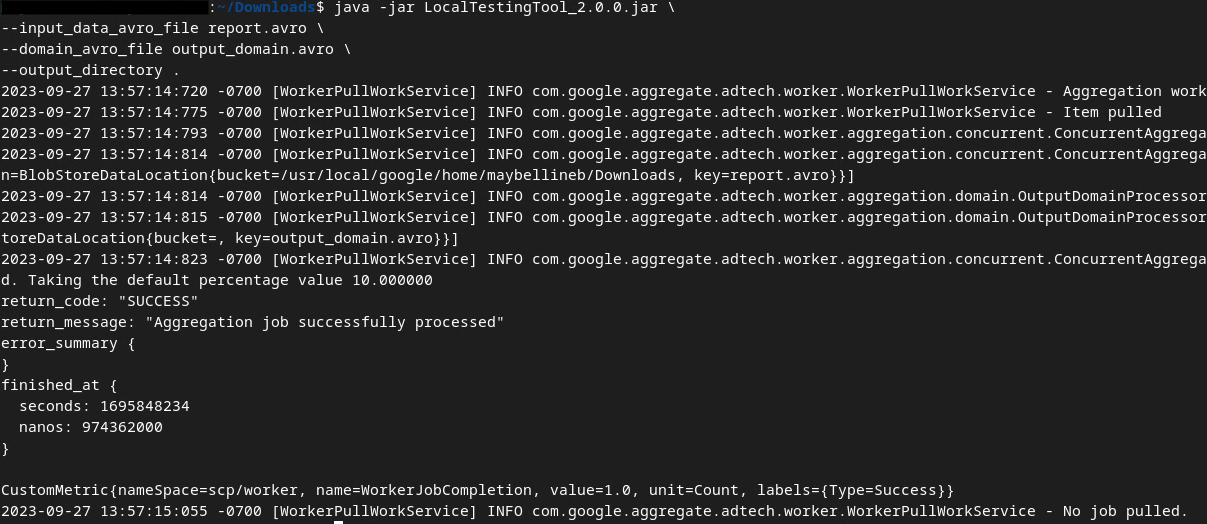
--output_directory .
You should see something similar to the below once the command is run. A report output.avro is created once this is completed.
2.6. Review the Summary Report
The summary report that is created is in AVRO format. To be able to read this, you need to convert this from AVRO to a JSON format. Ideally, adTech should write code to convert AVRO reports back to JSON.
We'll use aggregatable_report_converter.jar to convert the AVRO report back to JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
This returns a report similar to the below. Along with a report output.json created in the same directory.

Codelab complete!
Summary: You have collected a debug report, constructed an output domain file, and generated a summary report using the local testing tool which simulates the aggregation behavior of Aggregation Service.
Next steps: Now that you've experimented with the Local Testing tool, you can try the same exercise with a live deployment of Aggregation Service in your own environment. Revisit the prerequisites to make sure you've set everything up for "Aggregation Service" mode, then proceed to step 3.
3. 3. Aggregation Service Codelab
Estimated time to complete: 1 hour
Before you begin, ensure that you've completed all Prerequisites labeled with "Aggregation Service".
Codelab steps
Step 3.1. Aggregation Service Input Creation: Create the Aggregation Service reports that are batched for Aggregation Service.
- Step 3.1.1. Trigger Report
- Step 3.1.2. Collect Aggregatable Reports
- Step 3.1.3. Convert Reports to AVRO
- Step 3.1.4. Create output_domain AVRO
- Step 3.1.5. Move Reports to Cloud Storage bucket
Step 3.2. Aggregation Service Usage: Use the Aggregation Service API to create Summary Reports and review the Summary Reports.
- Step 3.2.1. Using
createJobEndpoint to batch - Step 3.2.2. Using
getJobEndpoint to retrieve batch status - Step 3.2.3. Reviewing the Summary Report
3.1. Aggregation Service Input Creation
Proceed to create the AVRO reports for batching to Aggregation Service. The shell commands in these steps can be run within GCP's Cloud Shell (as long as the dependencies from the Prerequisites are cloned into your Cloud Shell environment) or in a local execution environment.
3.1.1. Trigger Report
Follow the link to go to the site; then, you can view the reports at chrome://private-aggregation-internals:
The report that is sent to the {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage endpoint is also found in the "Report Body" of the reports displayed on the Chrome Internals page.
You may see many reports here, but for this codelab, use the aggregatable report that is GCP-specific and generated by the debug endpoint. The "Report URL" will contain "/debug/" and the aggregation_coordinator_origin field of the "Report Body" will contain this URL: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Collect Aggregatable Reports
Collect your aggregatable reports from the .well-known endpoints of your corresponding API.
- Private Aggregation:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attribution Reporting - Summary Report:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
For this codelab, we perform the report collection manually. In production, adTechs are expected to programmatically collect and convert the reports.
Let's go ahead and copy the JSON report in the "Report Body" from chrome://private-aggregation-internals.
In this example, we use vim since we are using linux. But you can use any text editor you want.
vim report.json
Paste the report into report.json and save your file.
3.1.3. Convert Reports to AVRO
Reports received from the .well-known endpoints are in JSON format and need to be converted into AVRO report format. Once you have the JSON report, navigate to where report.json is stored and use aggregatable_report_converter.jar to help create the debug aggregatable report. This creates an aggregatable report called report.avro in your current directory.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Create output_domain AVRO
To create the output_domain.avro file, you need the bucket keys that can be retrieved from the reports.
Bucket keys are designed by the adTech. However, in this case, the site Privacy Sandbox Demo creates the bucket keys. Since private aggregation for this site is in debug mode, we can use the debug_cleartext_payload from the "Report Body" to get the bucket key.
Go ahead and copy the debug_cleartext_payload from the report body.
Open goo.gle/ags-payload-decoder and paste your debug_cleartext_payload in the "INPUT" box and click "Decode".
The page returns the decimal value of the bucket key. The below is a sample bucket key.
Now that we have the bucket key, let's create the output_domain.avro in the same folder we've been working in. Ensure that you replace bucket key with the bucket key you retrieved.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
The script creates the output_domain.avro file in your current folder.
3.1.5. Move Reports to Cloud Storage bucket
Once the AVRO reports and output domain are created, proceed to move the reports and output domain into the bucket in Cloud Storage (which you noted in Prerequisite 1.6).
If you have the gcloud CLI setup on your local environment, use the below commands to copy the files to the corresponding folders.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
Otherwise, manually upload the files to your bucket. Create a folder called "reports" and upload the report.avro file there. Create a folder called "output_domains" and upload the output_domain.avro file there.
3.2. Aggregation Service Usage
Recall in Prerequisite 1.8 that you selected either cURL or Postman for making API requests to Aggregation Service endpoints. Below you'll find instructions for both options.
If your job fails with an error, check our troubleshooting documentation in GitHub for more information on how to proceed.
3.2.1. Using createJob Endpoint to batch
Use either cURL or Postman instructions below to create a job.
cURL
In your "Terminal", create a request body file (body.json) and paste in the below. Be sure to update the placeholder values. Refer to this API documentation for more information on what each field represents.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Execute the below request. Replace the placeholders in the cURL request's URL with the values from frontend_service_cloudfunction_url, which is output after successful completion of the Terraform deployment in Prerequisite 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
You should receive a HTTP 202 response once the request is accepted by the Aggregation Service. Other possible response codes are documented in the API specs.
Postman
For the createJob endpoint, a request body is required in order to provide the Aggregation Service with the location and file names of aggregatable reports, output domains, and summary reports.
Navigate to the createJob request's "Body" tab:

Replace the placeholders within the JSON provided. For more information on these fields and what they represent, refer to the API documentation.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"Send" the createJob API request:

The response code can be found in the lower half of the page:

You should receive a HTTP 202 response once the request is accepted by the Aggregation Service. Other possible response codes are documented in the API specs.
3.2.2. Using getJob Endpoint to retrieve batch status
Use either cURL or Postman instructions below to get a job.
cURL
Execute the below request in your Terminal. Replace the placeholders in the URL with the values from frontend_service_cloudfunction_url, which is the same URL as you used for the createJob request. For "job_request_id", use the value from the job you created with the createJob endpoint.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
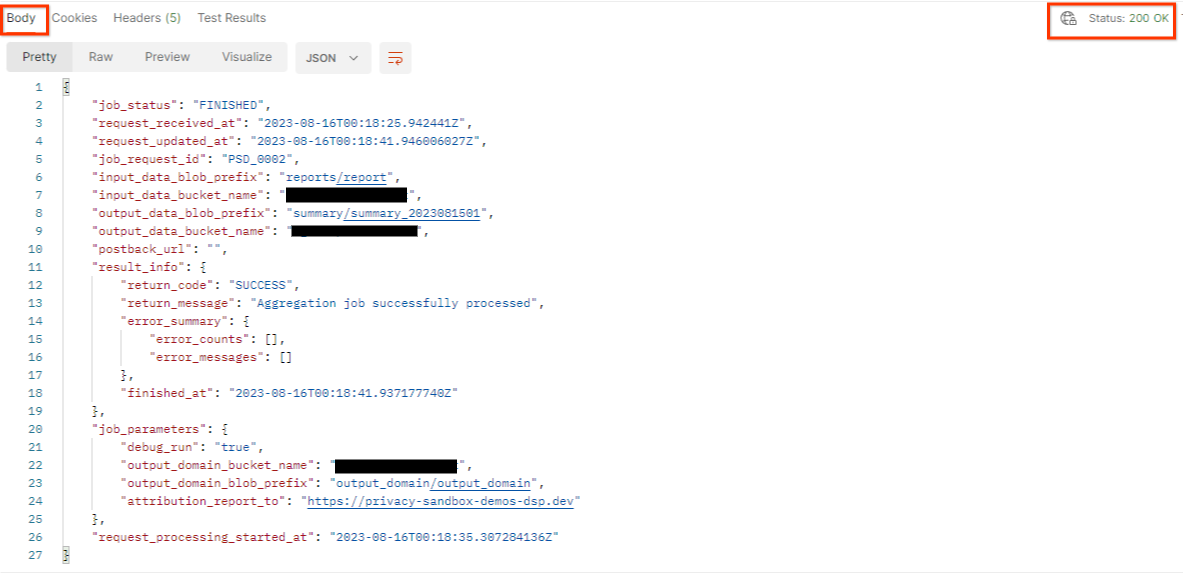
The result should return the status of your job request with a HTTP status of 200. The request "Body" contains the necessary information like job_status, return_message and error_messages (if the job has errored out).
Postman
To check the status of the job request, you can use the getJob endpoint. In the "Params" section of the getJob request, update the job_request_id value to the job_request_id that was sent in the createJob request.
"Send" the getJob request:

The result should return the status of your job request with a HTTP status of 200. The request "Body" contains the necessary information like job_status, return_message and error_messages (if the job has errored out).
3.2.3. Reviewing the Summary Report
Once you receive your summary report in your output Cloud Storage bucket, you can download this to your local environment. Summary reports are in AVRO format and can be converted back to a JSON. You can use aggregatable_report_converter.jar to read your report using the below command.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
This returns a json of aggregated values of each bucket key that looks similar to the below.

Should your createJob request include debug_run as true, then you can receive your summary report in the debug folder that is located in the output_data_blob_prefix. The report is in AVRO format and can be converted using the above command to a JSON.
The report contains the bucket key, unnoised metric and the noise that is added to the unnoised metric to form the summary report. The report is similar to the below.

The annotations also contain "in_reports" and/or "in_domain" which means:
- in_reports - the bucket key is available inside the aggregatable reports.
- in_domain - the bucket key is available inside the output_domain AVRO file.
Codelab complete!
Summary: You have deployed the Aggregation Service in your own cloud environment, collected a debug report, constructed an output domain file, stored these files in a Cloud Storage bucket, and run a successful job!
Next steps: Continue to use Aggregation Service in your environment, or delete the cloud resources you've just created following the clean-up instructions in step 4.
4. 4. Clean-up
To delete the resources created for Aggregation Service via Terraform, use the destroy command in the adtech_setup and dev (or other environment) folders:
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
To delete the Cloud Storage bucket holding your aggregatable reports and summary reports:
$ gcloud storage buckets delete gs://my-bucket
You may also choose to revert your Chrome cookie settings from Prerequisite 1.2 to their previous state.
5. 5. Appendix
Example adtech_setup.auto.tfvars file
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Example dev.auto.tfvars file
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20