
1. 1. 前提条件
完了までの推定所要時間: 1 ~ 2 時間
この Codelab には、ローカルテストと集計サービスの 2 つのモードがあります。ローカルテスト モードには、ローカルマシンと Chrome ブラウザが必要です(Google Cloud リソースの作成や使用は必要ありません)。集約サービスモードでは、Google Cloud に集約サービスを完全にデプロイする必要があります。
この Codelab をどちらのモードでも実行するには、いくつかの前提条件を満たす必要があります。各要件は、ローカルテストと集約サービスのどちらで必要かに応じてマークされています。
1.1. 登録と認証の完了(集約サービス)
プライバシー サンドボックス API を使用するには、Chrome と Android の両方で登録と証明書が完了している必要があります。
1.2. Ad Privacy API(ローカルテストおよび集計サービス)を有効にする
プライバシー サンドボックスを使用するため、プライバシー サンドボックスの広告 API を有効にすることをおすすめします。
ブラウザで chrome://settings/adPrivacy に移動し、Ad privacy API をすべて有効にします。
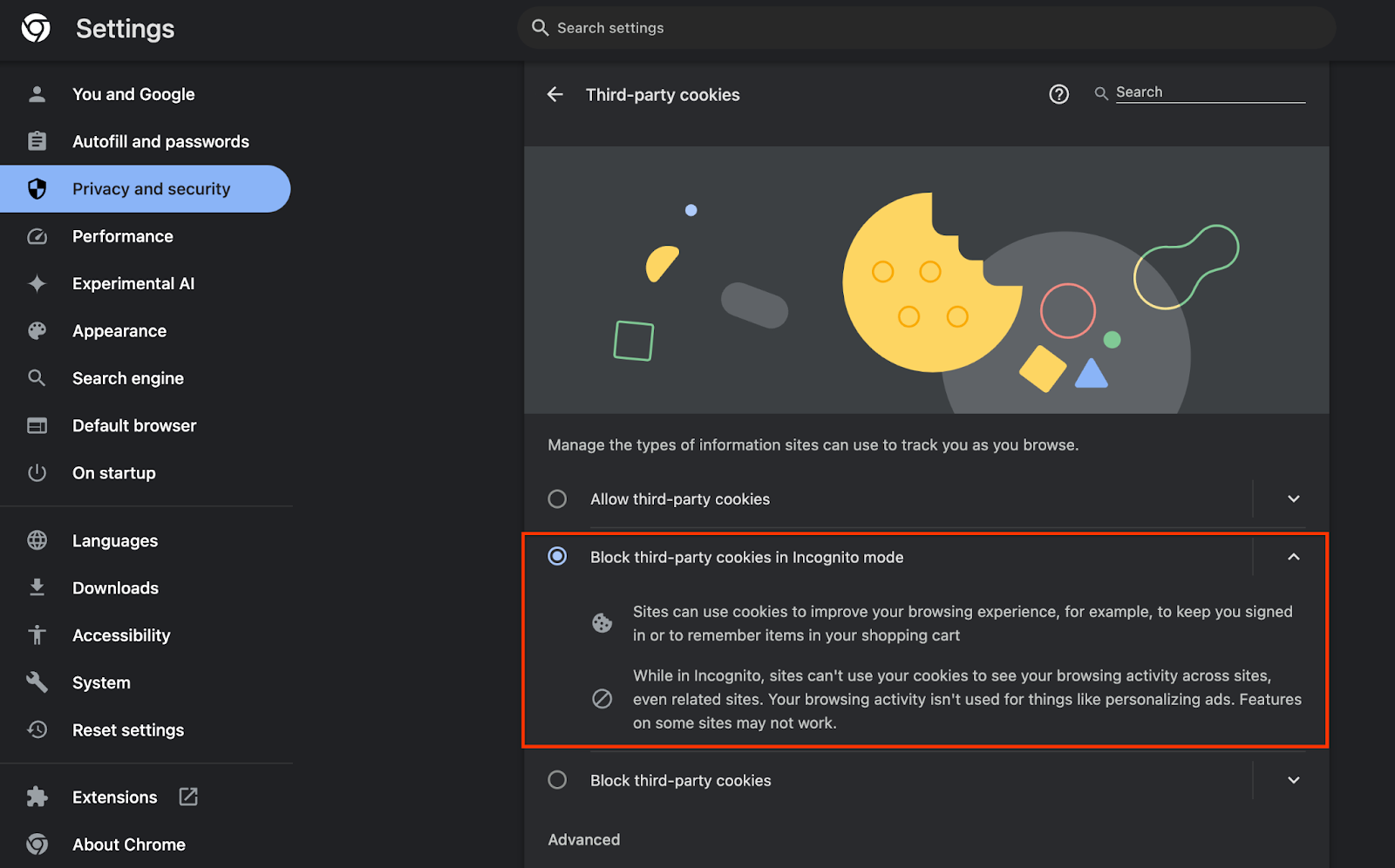
また、サードパーティ Cookie が有効になっていることも確認します。
chrome://settings/cookies で、サードパーティ Cookie がブロックされていないことを確認します。Chrome のバージョンによっては、この設定メニューに表示されるオプションが異なる場合がありますが、使用できる設定は次のとおりです。
- 「すべてのサードパーティ Cookie をブロックする」= 無効
- 「サードパーティの Cookie をブロックする」= 無効
- 「シークレット モードでサードパーティの Cookie をブロックする」= 有効
1.3. ローカル テストツール(ローカルテスト)をダウンロードする
ローカルテストを行うには、ローカル テストツールをダウンロードする必要があります。このツールは、暗号化されていないデバッグ レポートから概要レポートを生成します。
ローカルテストツールは、GitHub の Cloud Functions JAR アーカイブからダウンロードできます。LocalTestingTool_{version}.jar という名前にします。
1.4. JAVA JRE がインストールされていることを確認してください(ローカルテストと集約サービス)
ターミナルを開き、java --version を使用して、マシンに Java または openJDK がインストールされているかどうかを確認します。

インストールされていない場合は、Java のサイトまたは openJDK のサイトからダウンロードしてインストールできます。
1.5. aggregatable_report_converter(ローカル テストおよび集計サービス)をダウンロードする
aggregatable_report_converter のコピーは、プライバシー サンドボックスのデモ GitHub リポジトリからダウンロードできます。GitHub リポジトリには、IntelliJ または Eclipse の使用が記載されていますが、どちらも必須ではありません。これらのツールを使用しない場合は、代わりに JAR ファイルをローカル環境にダウンロードしてください。
1.6. GCP 環境(集約サービス)を設定する
アグリゲーション サービスでは、クラウド プロバイダを使用する高信頼実行環境を使用する必要があります。この Codelab では、集計サービスを GCP にデプロイしますが、AWS もサポートしています。
GitHub のデプロイ手順に沿って gcloud CLI を設定し、Terraform バイナリとモジュールをダウンロードして、集計サービス用の GCP リソースを作成します。
デプロイ手順の主なステップ:
- 「gcloud」コマンドをCLI と Terraform の使用を検討します。
- Terraform の状態を保存する Cloud Storage バケットを作成する。
- 依存関係をダウンロードする。
adtech_setup.auto.tfvarsを更新し、adtech_setupTerraform を実行します。adtech_setup.auto.tfvarsファイルの例については、付録をご覧ください。ここで作成するデータバケットの名前をメモします。これは、Codelab で作成するファイルを保存するために使用されます。dev.auto.tfvarsを更新し、デプロイ サービス アカウントの権限を借用して、devTerraform を実行します。dev.auto.tfvarsファイルの例については、付録をご覧ください。- デプロイが完了したら、Terraform の出力から
frontend_service_cloudfunction_urlを取得します。これは、後の手順で集計サービスにリクエストを行うときに必要になります。
1.7.集約サービスのオンボーディング(集約サービス)を完了する
集約サービスを使用するには、コーディネーターへのオンボーディングが必要です。集計サービスのオンボーディング フォームに、レポートサイトやその他の情報を入力して [Google Cloud] を選択し、サービス アカウントのアドレスを入力します。このサービス アカウントは、以前の前提条件(1.6.「GCP 環境を設定する」を参照)。(ヒント: 指定されているデフォルト名を使用する場合、このサービス アカウントは「worker-sa@」で始まります)。
オンボーディング プロセスが完了するまで、最大 2 週間かかります。
1.8.API エンドポイント(集計サービス)を呼び出す方法を決定する
この Codelab には、Aggregation Service API エンドポイントを呼び出すための 2 つのオプション(cURL と Postman)が用意されています。cURL を使用すると、セットアップが最小限で済み、追加のソフトウェアが不要なため、ターミナルから API エンドポイントを迅速かつ簡単に呼び出すことができます。ただし、cURL を使用したくない場合は、代わりに Postman を使用して API リクエストを実行、保存し、後で使用することもできます。
「3.2.Aggregation Service Usage で、両方のオプションを使用する際の詳細な手順を確認できます。プレビューして、使用する方法を決定できます。Postman を選択した場合は、次の初期設定を行います。
1.8.1.ワークスペースをセットアップ
Postman アカウントに登録します。登録すると、ワークスペースが自動的に作成されます。
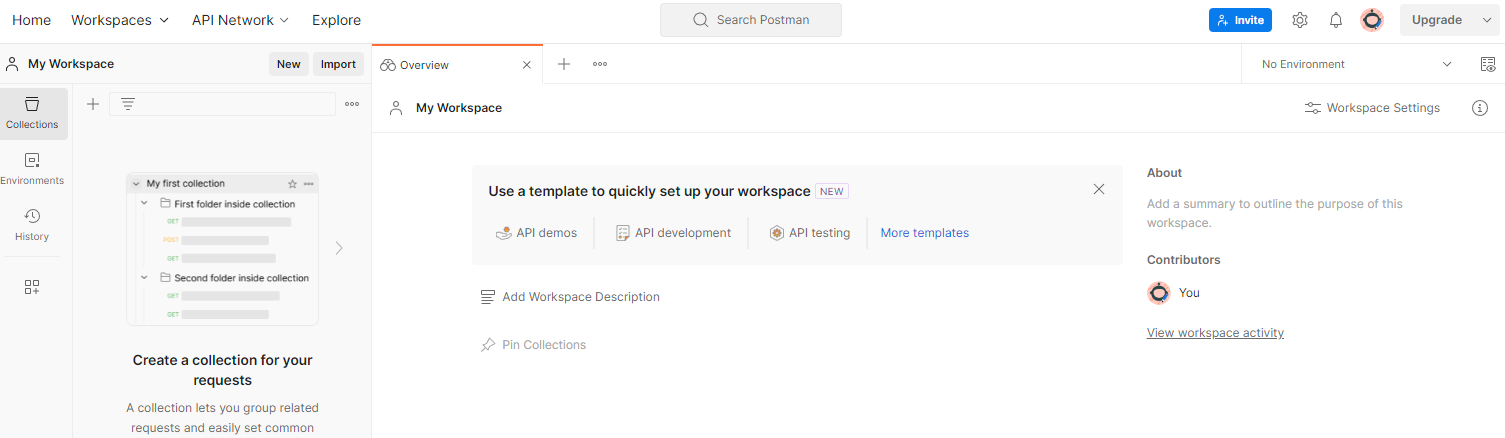
ワークスペースが作成されていない場合は、[ワークスペース] に移動します。[Create Workspace] を選択します。
[空のワークスペース] を選択し、[次へ] をクリックして「GCP Privacy Sandbox」という名前を付けます。[個人用] を選択します。[作成]をクリックします
事前構成済みのワークスペースの JSON 構成とGlobal Environment ファイルをダウンロードします。
両方の JSON ファイルを「My Workspace」にインポートします[インポート]から] ボタンを離します。

これにより「GCP プライバシー サンドボックス」が作成されますcreateJob および getJob HTTP リクエストと一緒に自動的に収集されます。
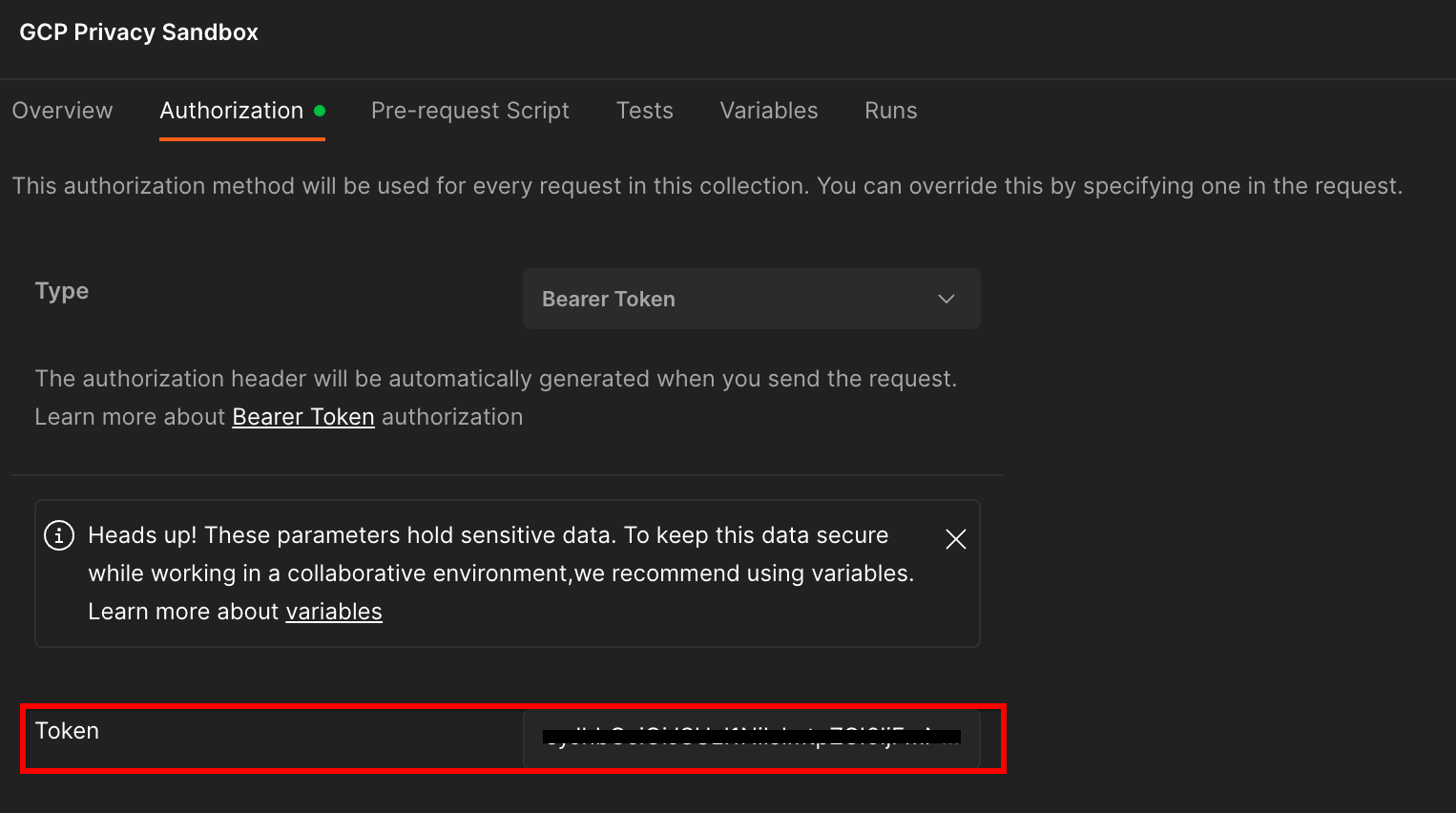
1.8.2.認可を設定する
[GCP Privacy Sandbox] をクリックします。[Authorization(承認)] セクションに移動し、タブ

ここでは「署名なしトークン」をメソッドを呼び出します。ターミナル環境から、次のコマンドを実行して出力をコピーします。
gcloud auth print-identity-token
次に、このトークン値を [トークン] 欄に貼り付けます。フィールドで確認できます。
1.8.3.環境を設定する
[環境のクイックルック] に移動しますをクリックします。
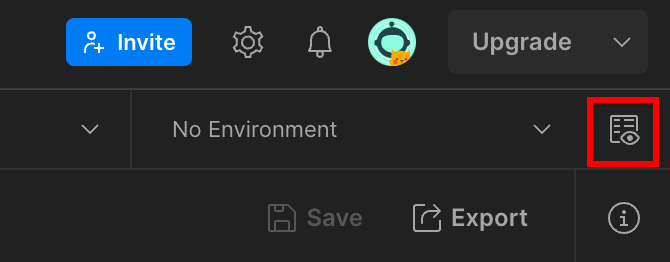
[編集] をクリックします。[現在の値]を"environment"、"region"、"cloud-function-id":
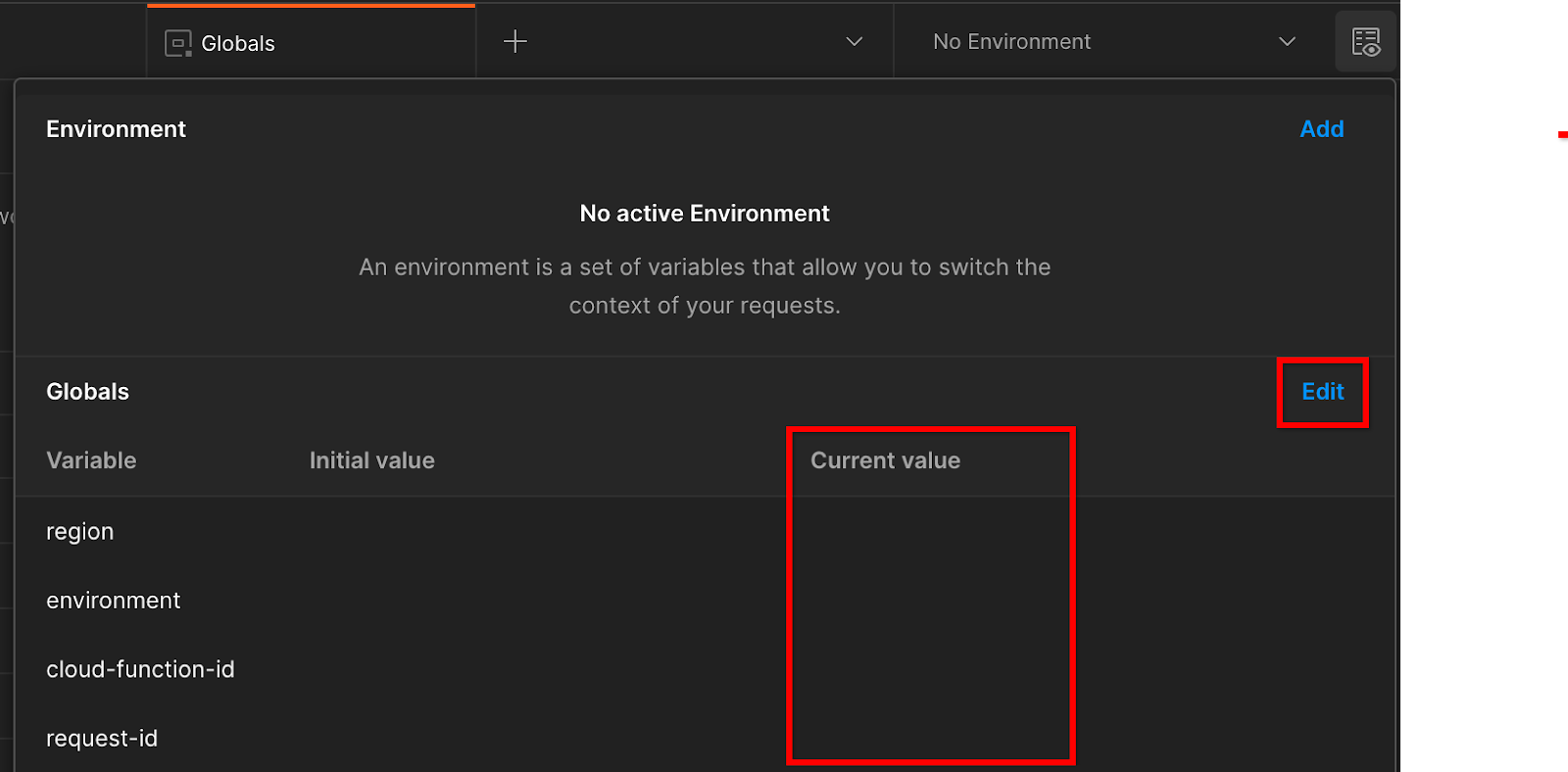
「request-id」はそのままで構いません。後で入力するため、空白にします。他のフィールドには、前提条件 1.6 で Terraform のデプロイが正常に完了したときに返された frontend_service_cloudfunction_url の値を使用します。URL の形式は https:// です。
2. 2. ローカルテストの Codelab
完了までの推定所要時間: 1 時間未満
マシン上のローカルテスト ツールを使用して集計を実行し、暗号化されていないデバッグ レポートを使用して概要レポートを生成できます。始める前に、「ローカルテスト」というラベルが付いた前提条件をすべて満たしていることを確認してください。
Codelab のステップ
ステップ 2.1.トリガー レポート: プライベート アグリゲーション レポートをトリガーしてレポートを収集できるようにします。
ステップ 2.2.Create Debug AVRO Report: 収集した JSON レポートを AVRO 形式のレポートに変換します。この手順は、アドテックが API レポート エンドポイントからレポートを収集し、JSON レポートを AVRO 形式のレポートに変換する場合と同様です。
ステップ 2.3.バケットキーを取得する: バケットキーはアドテックによって設計されています。この Codelab では、バケットが事前に定義されているため、指定されたバケットキーを取得します。
ステップ 2.4.出力ドメイン AVRO を作成する: バケットキーを取得したら、出力ドメイン AVRO ファイルを作成します。
ステップ 2.5.概要レポートの作成: ローカル テストツールを使用して、ローカル環境で概要レポートを作成できます。
ステップ 2.6.概要レポートを確認する: ローカル テストツールで作成された概要レポートを確認します。
2.1. トリガー レポート
非公開集計レポートをトリガーするには、プライバシー サンドボックスのデモサイト(https://privacy-sandbox-demos-news.dev/?env=gcp)または独自のサイト(例: https://adtechexample.com)を使用します。独自のサイトを使用していて、登録と登録を完了していない場合証明書とアグリゲーション サービスのオンボーディングでは、Chrome のフラグと CLI スイッチを使用する必要があります。
このデモでは、プライバシー サンドボックスのデモサイトを使用します。リンクをクリックしてサイトにアクセスします。その後、chrome://private-aggregation-internals でレポートを表示できます。
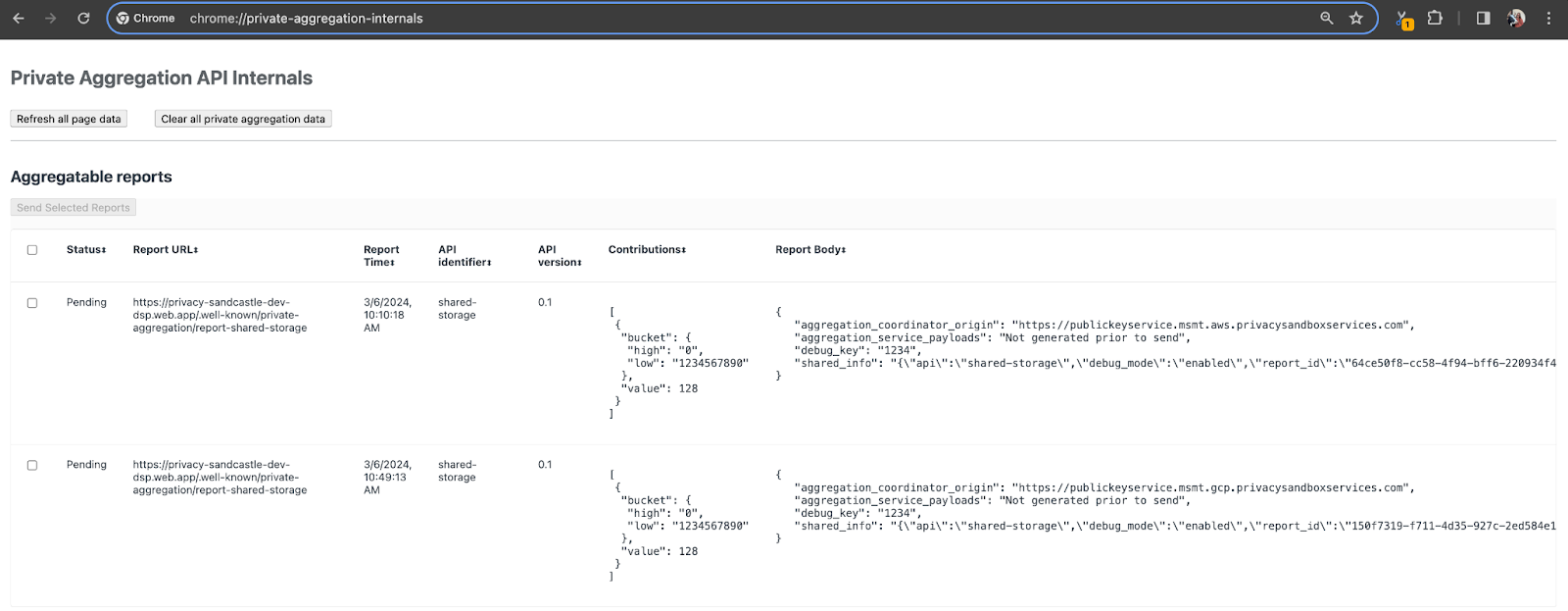
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage エンドポイントに送信されるレポートは、[Report Body] にも表示されます。レポートの一部のみ利用できます
ここには多くのレポートが表示されますが、この Codelab では、デバッグ エンドポイントによって生成される GCP 固有の集計可能レポートを使用します。「レポート URL」「/debug/」が含まれると「Report Body」の aggregation_coordinator_origin field をこの URL は https://publickeyservice.msmt.gcp.privacysandboxservices.com です。
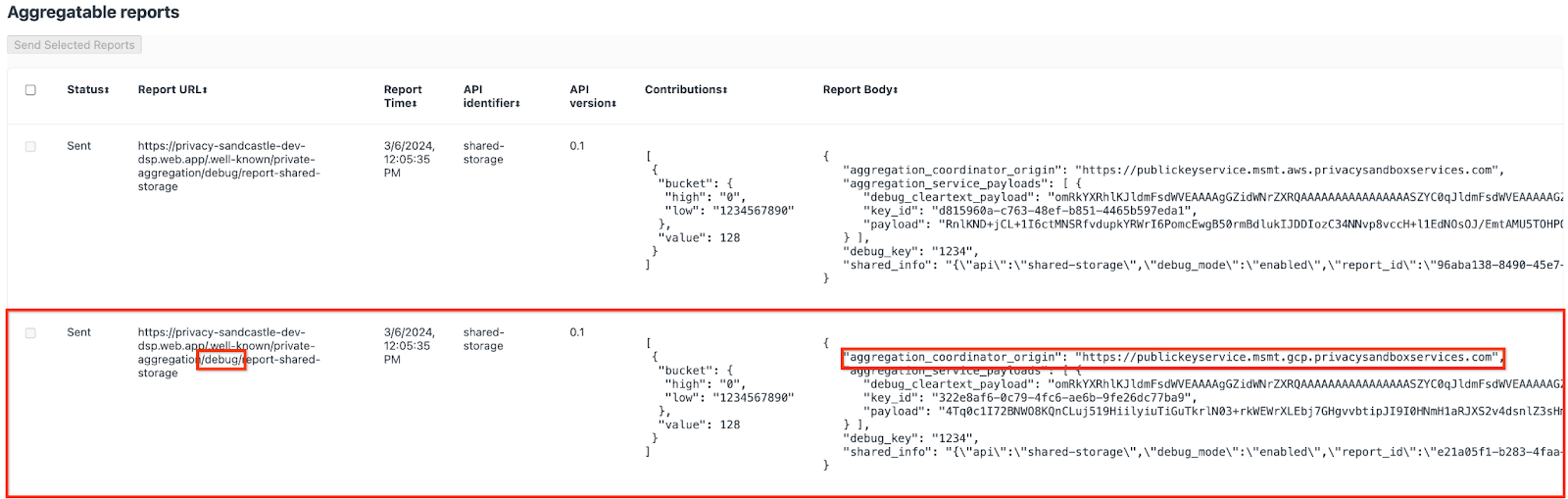
2.2. デバッグ集計可能レポートを作成
[Report Body] 内にあるレポートをコピーします。chrome://private-aggregation-internals を開き、privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar フォルダ(前提条件 1.5 でダウンロードしたリポジトリ内)に JSON ファイルを作成します。
この例では Linux を使用しているため、vim を使用しています。任意のテキスト エディタを使用できます。
vim report.json
レポートを report.json に貼り付けて、ファイルを保存します。

それを取得したら、aggregatable_report_converter.jar を使用してデバッグ集計可能レポートを作成します。これにより、現在のディレクトリに report.avro という集計レポートが作成されます。
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. レポートからバケットキーを取得する
output_domain.avro ファイルを作成するには、レポートから取得できるバケットキーが必要です。
バケットキーはアドテックによって設計されています。ただし、この場合は、サイトのプライバシー サンドボックスのデモがバケットキーを作成します。このサイトの非公開集計はデバッグモードであるため、[Report Body] の debug_cleartext_payload を使用できます。バケットキーを取得します
では、レポート本文から debug_cleartext_payload をコピーします。

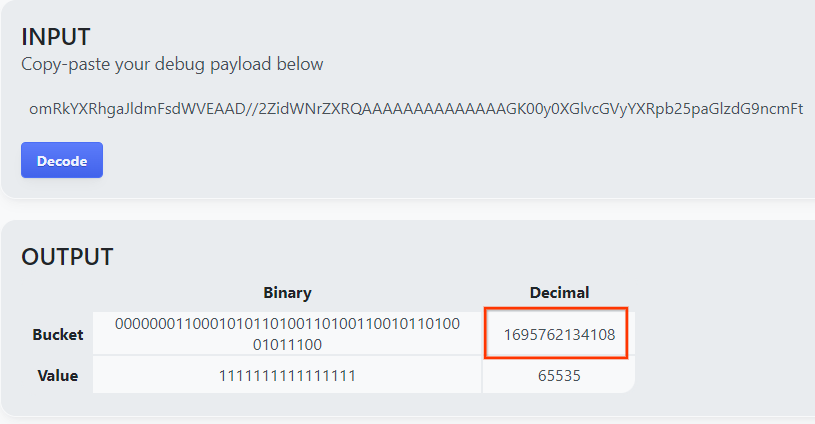
goo.gle/ags-payload-decoder を開き、[入力] に debug_cleartext_payload を貼り付けます。[デコード]をクリックします
![[デコード] ボタン](https://developers-dot-devsite-v2-prod.appspot.com/privacy-sandbox/assets/images/codelab/aggregation-service-codelab-gcp/decode.png?authuser=3&hl=ja)
バケットキーの 10 進数値が返されます。バケットキーの例を次に示します。
2.4. 出力ドメイン AVRO の作成
バケットキーを取得したので、先ほど作業したのと同じフォルダに output_domain.avro を作成しましょう。バケットキーは、取得したバケットキーに置き換えてください。
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
このスクリプトにより、現在のフォルダに output_domain.avro ファイルが作成されます。
2.5. ローカル テストツールを使用して概要レポートを作成する
前提条件 1.3 でダウンロードした LocalTestingTool_{version}.jar を使用して、次のコマンドで概要レポートを作成します。{version} はダウンロードしたバージョンに置き換えます。LocalTestingTool_{version}.jar を現在のディレクトリに移動するか、相対パスを追加して現在の場所を参照します。
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
このコマンドを実行すると、次のように表示されます。完了すると、レポート output.avro が作成されます。
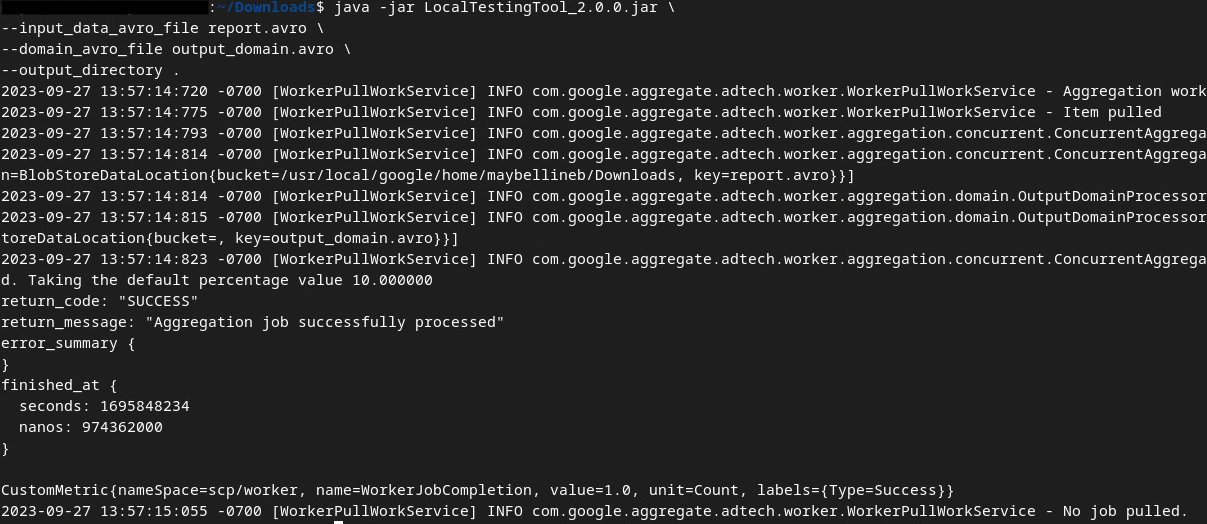
2.6. 概要レポートを確認する
作成される概要レポートは AVRO 形式です。これを読み取るには、これを AVRO から JSON 形式に変換する必要があります。アドテックが AVRO レポートを JSON に変換するコードを記述するのが理想的です。
aggregatable_report_converter.jar を使用して、AVRO レポートを JSON に戻します。
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
これにより、次のようなレポートが返されます。同じディレクトリにレポート output.json が作成されます。

Codelab が完了しました
概要: デバッグ レポートを収集し、出力ドメイン ファイルを作成し、集計サービスの集計動作をシミュレートするローカルテストツールを使用して概要レポートを生成しました。
次のステップ: ローカルテスト ツールでテストを行ったので、実際の環境で集計サービスのライブ デプロイを行って、同じ演習を試すことができます。前提条件を再確認し、「集計サービス」に必要な設定がすべて完了していることを確認します。ステップ 3 に進みます。
3. 3. 集計サービスの Codelab
完了までの推定所要時間: 1 時間
始める前に、「Aggregation Service」というラベルが付いた前提条件をすべて完了していることを確認してください。
Codelab のステップ
ステップ 3.1.集計サービスの入力の作成: 集計サービスに対してバッチ処理される集計サービス レポートを作成します。
- ステップ 3.1.1.トリガー レポート
- ステップ 3.1.2.集計可能レポートの収集
- ステップ 3.1.3.レポートを AVRO に変換する
- ステップ 3.1.4.output_domain AVRO を作成する
- ステップ 3.1.5。レポートを Cloud Storage バケットに移動する
ステップ 3.2.Aggregation Service Usage: Aggregation Service API を使用して、概要レポートを作成し、概要レポートを確認します。
- ステップ 3.2.1.
createJobエンドポイントを使用したバッチ処理 - ステップ 3.2.2.
getJobエンドポイントを使用してバッチ ステータスを取得する - ステップ 3.2.3。概要レポートの確認
3.1. 集計サービスの入力作成
集計サービスへの一括処理に使用する AVRO レポートの作成に進みます。この手順のシェルコマンドは、GCP の Cloud Shell 内(前提条件の依存関係のクローンが Cloud Shell 環境に作成されている場合に限り)またはローカル実行環境で実行できます。
3.1.1. トリガー レポート
リンクをクリックしてサイトにアクセスします。その後、chrome://private-aggregation-internals でレポートを表示できます。
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage エンドポイントに送信されるレポートは、[Report Body] にも表示されます。レポートの一部のみ利用できます
ここには多くのレポートが表示されますが、この Codelab では、デバッグ エンドポイントによって生成される GCP 固有の集計可能レポートを使用します。「レポート URL」「/debug/」が含まれると「Report Body」の aggregation_coordinator_origin field をこの URL は https://publickeyservice.msmt.gcp.privacysandboxservices.com です。
3.1.2. 集計可能レポートの収集
対応する API の .well-known エンドポイントから、集計可能レポートを収集します。
- プライベート アグリゲーション:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - アトリビューション レポート - 概要レポート:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
この Codelab では、レポートの収集を手動で行います。本番環境では、アドテックがプログラマティックにレポートを収集して変換することが期待されます。
JSON レポートをコピーしてchrome://private-aggregation-internals~。
この例では Linux を使用しているため、vim を使用します。任意のテキスト エディタを使用できます。
vim report.json
レポートを report.json に貼り付けて、ファイルを保存します。
3.1.3. レポートを AVRO に変換する
.well-known エンドポイントから受信するレポートは JSON 形式であり、AVRO レポート形式に変換する必要があります。JSON レポートを取得したら、report.json が保存されている場所に移動し、aggregatable_report_converter.jar を使用してデバッグ集計可能レポートを作成します。これにより、現在のディレクトリに report.avro という集計レポートが作成されます。
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. output_domain AVRO を作成する
output_domain.avro ファイルを作成するには、レポートから取得できるバケットキーが必要です。
バケットキーはアドテックによって設計されています。ただし、この場合は、サイトのプライバシー サンドボックスのデモがバケットキーを作成します。このサイトの非公開集計はデバッグモードであるため、[Report Body] の debug_cleartext_payload を使用できます。バケットキーを取得します
では、レポート本文から debug_cleartext_payload をコピーします。
goo.gle/ags-payload-decoder を開き、[入力] に debug_cleartext_payload を貼り付けます。[デコード]をクリックします
バケットキーの 10 進数値が返されます。バケットキーの例を次に示します。
バケットキーを取得したので、先ほど作業したのと同じフォルダに output_domain.avro を作成しましょう。バケットキーは、取得したバケットキーに置き換えてください。
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
このスクリプトにより、現在のフォルダに output_domain.avro ファイルが作成されます。
3.1.5.レポートを Cloud Storage バケットに移動する
AVRO レポートと出力ドメインが作成されたら、レポートと出力ドメインを Cloud Storage(前提条件 1.6 でメモ)のバケットに移動します。
ローカル環境に gcloud CLI が設定されている場合は、次のコマンドを使用してファイルを対応するフォルダにコピーします。
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
それ以外の場合は、ファイルをバケットに手動でアップロードします。「reports」というフォルダを作成するそこに report.avro ファイルをアップロードします。「output_domains」というフォルダを作成するそこに output_domain.avro ファイルをアップロードします。
3.2. 集計サービスの使用状況
前提条件 1.8 では、集計サービス エンドポイントに API リクエストを行うために cURL または Postman を選択したことを思い出してください。以下に、これらの 2 つのオプションの手順を示します。
ジョブがエラーで失敗した場合は、GitHub のトラブルシューティング ドキュメントで処理方法の詳細を確認してください。
3.2.1. createJob エンドポイントを使用したバッチ処理
ジョブを作成するには、以下の cURL または Postman の手順を使用します。
cURL
[ターミナル] でリクエスト本文ファイル(body.json)を作成し、以下を貼り付けます。プレースホルダの値は必ず更新してください。各フィールドが表す内容について詳しくは、こちらの API ドキュメントをご覧ください。
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
以下のリクエストを実行します。cURL リクエストの URL のプレースホルダを、前提条件 1.6 で Terraform のデプロイが正常に完了した後に出力される frontend_service_cloudfunction_url の値に置き換えます。
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
リクエストが集計サービスによって受け入れられると、HTTP 202 レスポンスが返されます。その他のレスポンス コードについては、API 仕様をご覧ください。
Postman
createJob エンドポイントの場合、集計可能レポート、出力ドメイン、サマリー レポートの場所とファイル名を集計サービスに提供するために、リクエスト本文が必要です。
createJob リクエストの [Body] に移動します。タブ:
![[本文] タブ](https://developers-dot-devsite-v2-prod.appspot.com/privacy-sandbox/assets/images/codelab/aggregation-service-codelab-gcp/body-tab.png?authuser=3&hl=ja)
提供された JSON 内のプレースホルダを置き換えます。これらのフィールドの詳細と内容については、API ドキュメントをご覧ください。
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
「送信」createJob API リクエストを実行します。

レスポンス コードはページの下半分にあります。

リクエストが集計サービスによって受け入れられると、HTTP 202 レスポンスが返されます。その他のレスポンス コードについては、API 仕様をご覧ください。
3.2.2. getJob エンドポイントを使用してバッチ ステータスを取得する
以下の cURL または Postman の手順を使用してジョブを取得します。
cURL
ターミナルで以下のリクエストを実行します。URL のプレースホルダを frontend_service_cloudfunction_url の値に置き換えます。これは、createJob リクエストに使用した URL と同じ URL です。「job_request_id」には、createJob エンドポイントで作成したジョブの値を使用します。
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
ジョブ リクエストのステータスと HTTP ステータス 200 が返されます。リクエストの「本文」には、job_status、return_message、error_messages(ジョブがエラーになった場合)などの必要な情報が含まれます。
Postman
ジョブ リクエストのステータスを確認するには、getJob エンドポイントを使用します。[パラメータ] 欄のセクションで、job_request_id の値を createJob リクエストで送信された job_request_id に更新します。getJob
「送信」getJob リクエストを実行します。

ジョブ リクエストのステータスと HTTP ステータス 200 が返されます。リクエストの「本文」には、job_status、return_message、error_messages(ジョブがエラーになった場合)などの必要な情報が含まれます。
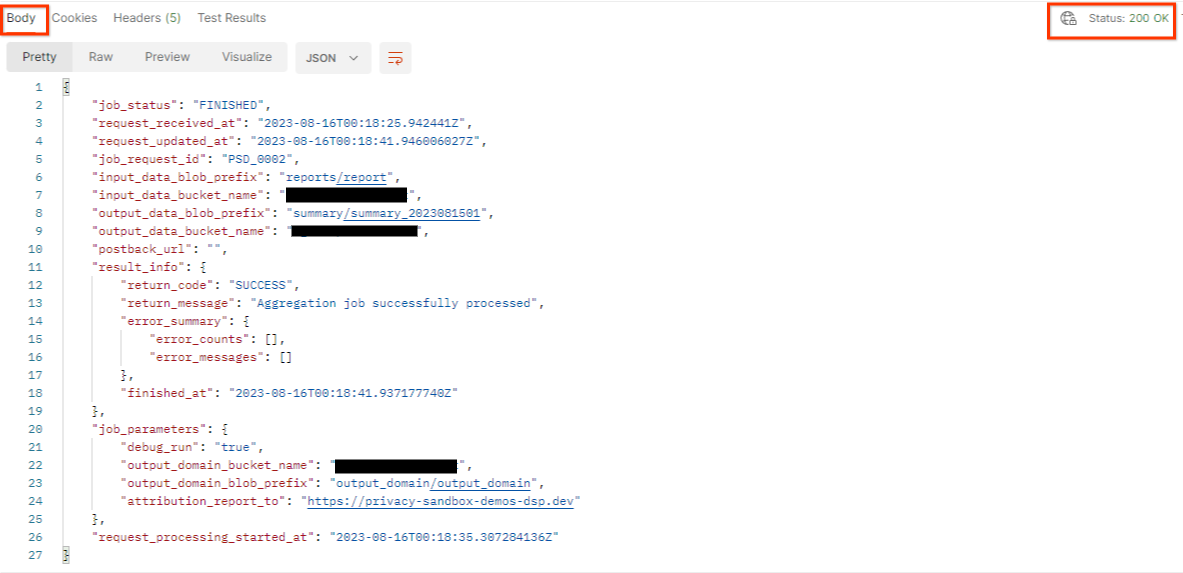
3.2.3. 概要レポートの確認
出力用の Cloud Storage バケットで概要レポートを受け取ったら、これをローカル環境にダウンロードできます。概要レポートは AVRO 形式であり、JSON に戻すことができます。以下のコマンドで aggregatable_report_converter.jar を使用してレポートを読み取ることができます。
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
これにより、次のような、各バケットキーの集計値の JSON が返されます。

createJob リクエストに debug_run が true として含まれている場合、概要レポートは output_data_blob_prefix にある debug フォルダに届きます。レポートは AVRO 形式であり、上記のコマンドを使用して JSON に変換できます。
このレポートには、バケットキー、ノイズのない指標、ノイズのない指標に追加されたノイズが含まれ、概要レポートが作成されます。レポートは次のようになります。

アノテーションには「in_reports」も含まれています。「in_domain」これは次のことを意味します。
- in_reports - バケットキーは集計可能レポート内で使用できます。
- in_domain - バケットキーは output_domain AVRO ファイル内で使用できます。
Codelab が完了しました
概要: 独自のクラウド環境に集計サービスをデプロイし、デバッグ レポートを収集し、出力ドメイン ファイルを作成して Cloud Storage バケットに保存し、ジョブを正常に実行しました。
次のステップ: 環境で集約サービスを引き続き使用するか、ステップ 4 のクリーンアップ手順に沿って作成したクラウド リソースを削除します。
4. 4. クリーンアップ
Terraform を介して集約サービス用に作成されたリソースを削除するには、adtech_setup フォルダと dev(または他の環境)フォルダで destroy コマンドを使用します。
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
集計可能レポートとサマリー レポートを保持する Cloud Storage バケットを削除するには:
$ gcloud storage buckets delete gs://my-bucket
Chrome の Cookie 設定を前提条件 1.2 から以前の状態に戻すこともできます。
5. 5. 付録
adtech_setup.auto.tfvars ファイルの例
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
dev.auto.tfvars ファイルの例
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20