
1. דרישות מוקדמות
כדי לבצע את הקודלאב הזה, נדרשים כמה תנאים מקדימים. כל דרישה מסומנת בהתאם אם היא נדרשת ל'בדיקה מקומית' או ל'שירות צבירת נתונים'.
1.1. הורדת הכלי לבדיקות מקומיות (בדיקות מקומיות)
כדי לבצע בדיקה מקומית, תצטרכו להוריד את הכלי לבדיקות מקומיות. הכלי יפיק דוחות סיכום מדוחות ניפוי הבאגים הלא מוצפנים.
הכלי לבדיקות מקומיות זמין להורדה בארכיוני JAR של Lambda ב-GitHub. השם שלו צריך להיות LocalTestingTool_{version}.jar.
1.2. מוודאים ש-JAVA JRE מותקן (שירות מקומי של בדיקה וצבירה)
פותחים את Terminal ומשתמשים בפקודה java --version כדי לבדוק אם במחשב מותקנת Java או openJDK.

אם היא לא מותקנת, אפשר להוריד ולהתקין אותה מאתר Java או מאתר openJDK.
1.3. הורדת הכלי להמרת דוחות לצורך צבירת נתונים (שירות מקומי לבדיקה ולצבירת נתונים)
אפשר להוריד עותק של הממיר של הדוחות שניתן לצבור ממאגר GitHub של הדגמות של ארגז החול לפרטיות.
1.4. הפעלת ממשקי API לשמירה על פרטיות בפרסום (שירות מקומי לבדיקה ולצבירה)
בדפדפן, עוברים אל chrome://settings/adPrivacy ומפעילים את כל ממשקי ה-API של פרטיות הפרסום.
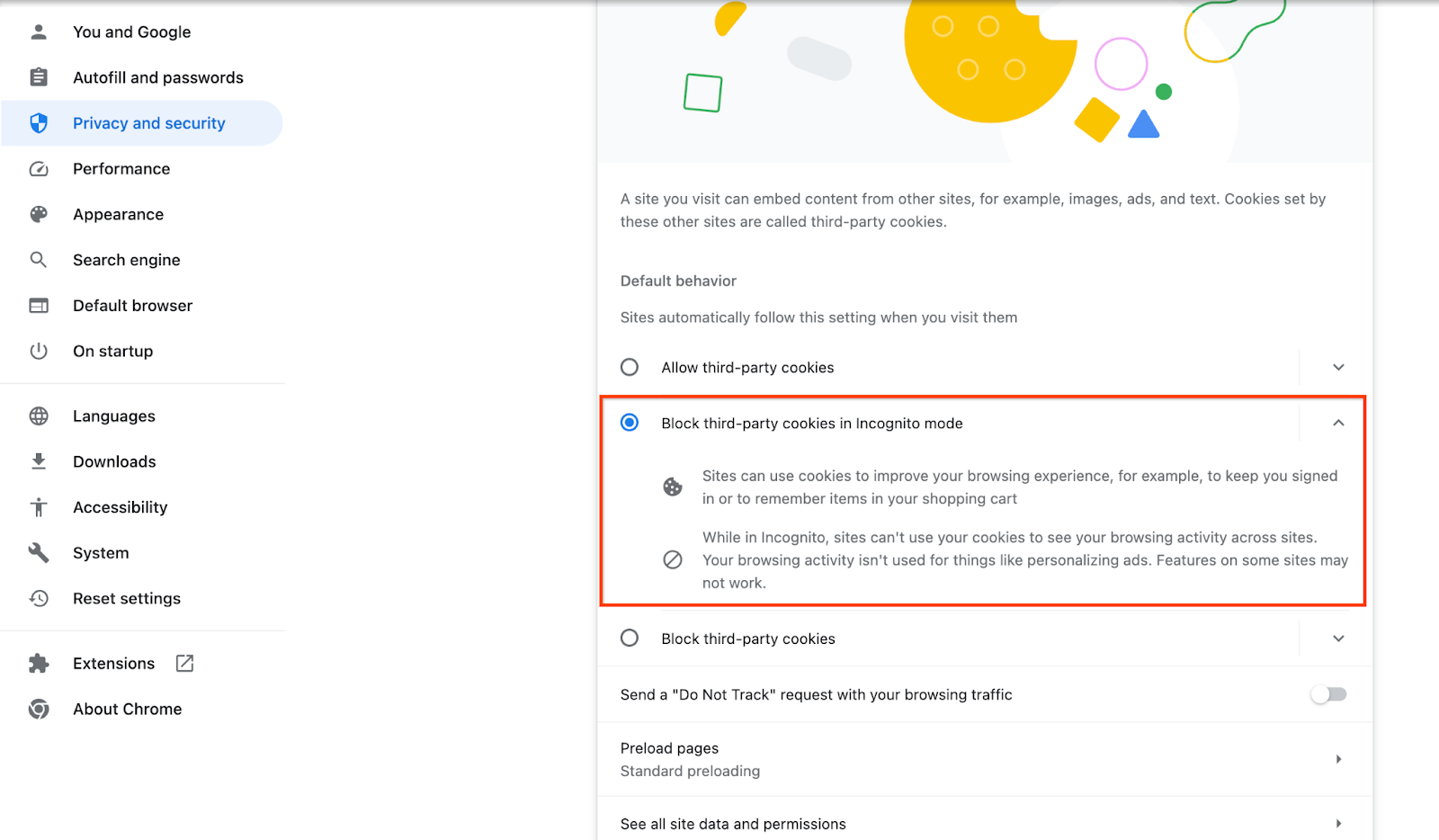
מוודאים שהופעלו קובצי cookie של צד שלישי.
בדפדפן, עוברים אל chrome://settings/cookies ובוחרים באפשרות חסימת קובצי Cookie של צד שלישי במצב פרטי.
1.5. הרשמה באינטרנט וב-Android (Aggregation Service)
כדי להשתמש בממשקי API של ארגז החול לפרטיות בסביבת ייצור, צריך לוודא שהשלמתם את ההרשמה והאימות גם ב-Chrome וגם ב-Android.
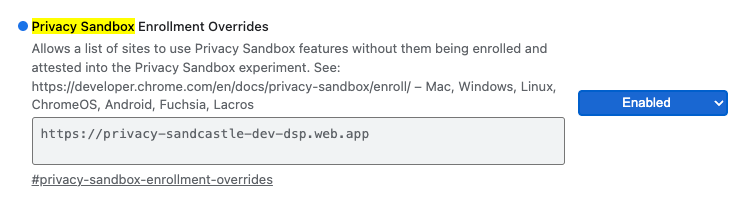
לצורך בדיקה מקומית, אפשר להשבית את ההרשמה באמצעות דגל Chrome ו-CLI switch.
כדי להשתמש בדגל Chrome להדגמה שלנו, עוברים אל chrome://flags/#privacy-sandbox-enrollment-overrides ומעדכנים את ההחרגה עם האתר שלכם. אם אתם מתכוונים להשתמש באתר ההדגמה שלנו, אין צורך לבצע עדכון.
1.6. הצטרפות ל-Aggregation Service (Aggregation Service)
כדי להשתמש בשירות הצבירה, צריך להוסיף את המארגנים. ממלאים את הטופס להצטרפות לשירות הצבירה ומספקים את כתובת האתר לדיווח, מזהה חשבון AWS ופרטים נוספים.
1.7. ספק שירותי ענן (Aggregation Service)
כדי להשתמש בשירות הצבירה, צריך להשתמש בסביבת מחשוב אמינה (TEE) שמשתמשת בסביבת ענן. שירות האגרגציה נתמך ב-Amazon Web Services (AWS) וב-Google Cloud (GCP). ב-Codelab הזה נסביר רק על שילוב עם AWS.
AWS מספקת סביבת מחשוב אמינה שנקראת Nitro Enclaves. עליכם לוודא שיש לכם חשבון AWS ולפעול לפי הוראות ההתקנה והעדכון של AWS CLI כדי להגדיר את סביבת AWS CLI.
אם ה-AWS CLI שלכם חדש, תוכלו להגדיר אותו לפי הוראות ההגדרה של CLI.
1.7.1. יצירת קטגוריה ב-AWS S3
יוצרים קטגוריה של AWS S3 לאחסון מצב Terraform, וקטגוריה אחרת של S3 לאחסון הדוחות ודוחות הסיכום. אפשר להשתמש בפקודת ה-CLI שצוינה. מחליפים את השדה ב-<> במשתנים המתאימים.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. יצירת מפתח גישה של משתמש
יוצרים מפתחות גישה של משתמשים לפי המדריך של AWS. הוא ישמש לקריאה לנקודות הקצה של ה-API createJob ו-getJob שנוצרו ב-AWS.
1.7.3. הרשאות משתמשים וקבוצות ב-AWS
כדי לפרוס את Aggregation Service ב-AWS, תצטרכו לתת הרשאות מסוימות למשתמש שמשמש לפריסה של השירות. ב-Codelab הזה, חשוב לוודא שלמשתמש יש גישת אדמין כדי להבטיח הרשאות מלאות בפריסה.
1.8. Terraform (Aggregation Service)
ב-Codelab הזה נעשה שימוש ב-Terraform כדי לפרוס את Aggregation Service. מוודאים שקובץ ה-binary של Terraform מותקן בסביבה המקומית.
מורידים את קובץ הבינארי של Terraform לסביבה המקומית.
אחרי שמורידים את קובץ הבינארי של Terraform, לחלץ את הקובץ ולהעביר את קובץ הבינארי של Terraform אל /usr/local/bin.
cp <directory>/terraform /usr/local/bin
מוודאים ש-Terraform זמין ב-classpath.
terraform -v
1.9. Postman (ל-AWS Aggregation Service)
ב-Codelab הזה נשתמש ב-Postman לניהול הבקשות.
כדי ליצור סביבת עבודה, עוברים לסביבות עבודה בתפריט הניווט העליון ובוחרים באפשרות יצירת סביבת עבודה.
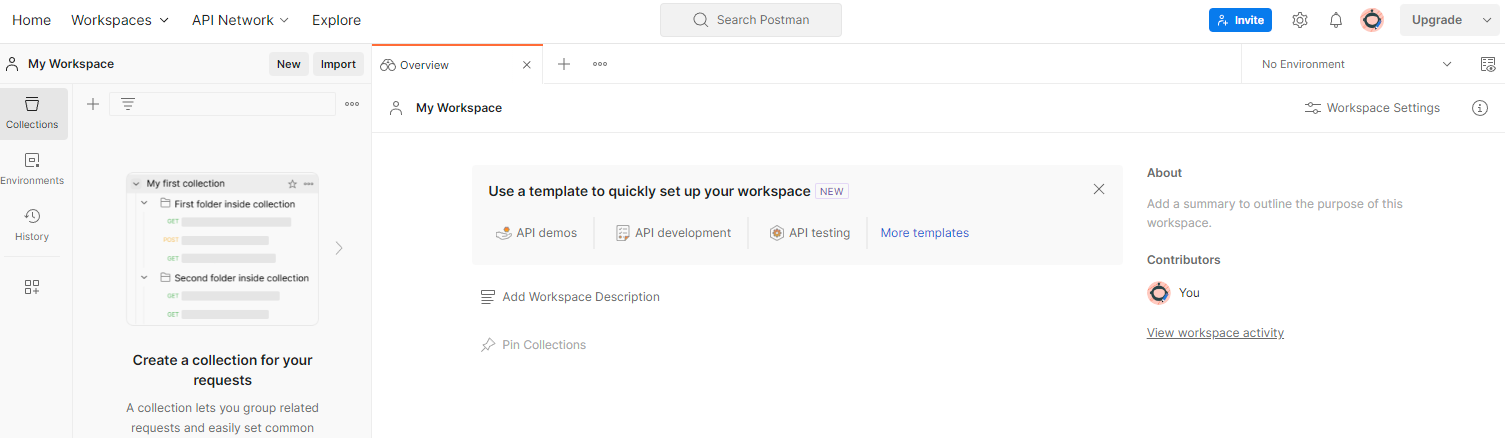
בוחרים באפשרות סביבת עבודה ריקה, לוחצים על 'הבא' ומעניקים לה את השם Sandbox לפרטיות. בוחרים באפשרות אישי ולוחצים על יצירה.
מורידים את קובצי התצורה של JSON ואת קובץ Global Environment של סביבת העבודה שהוגדרה מראש.
מייבאים את קובצי ה-JSON אל 'My Workspace' באמצעות הלחצן Import.

הפעולה הזו תיצור בשבילכם את האוסף של ארגז החול לפרטיות, יחד עם בקשות ה-HTTP createJob ו-getJob.
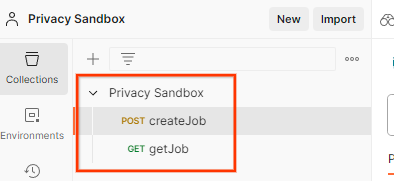
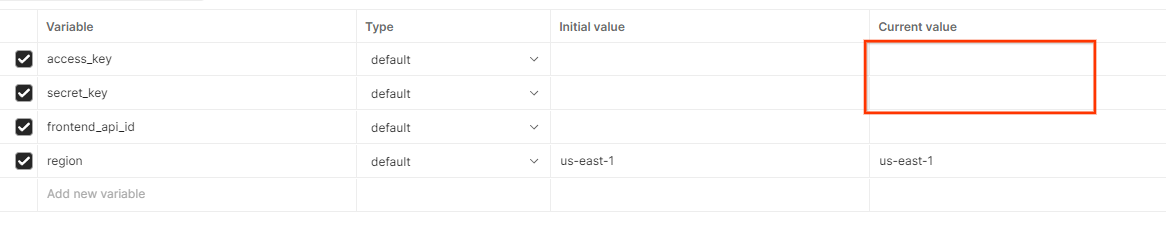
מעדכנים את 'מפתח הגישה' ו'מפתח הסוד' של AWS דרך הצגה מהירה של הסביבה.
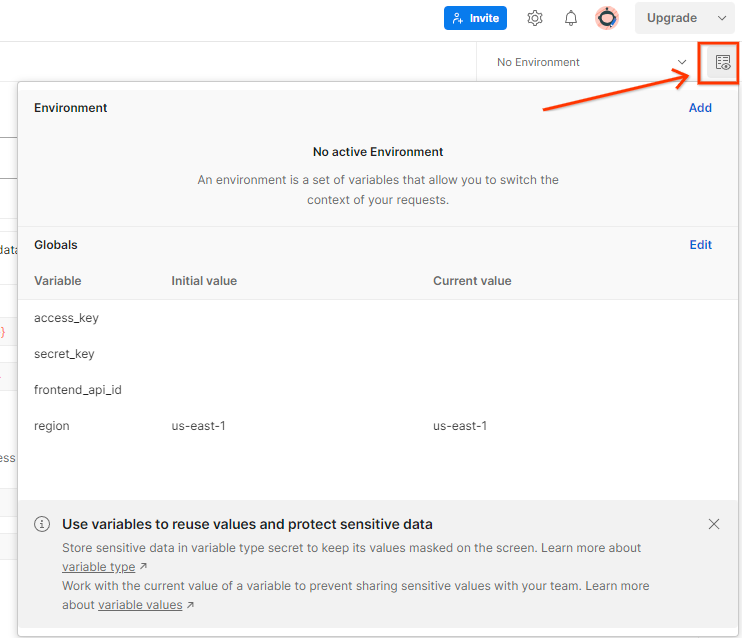
לוחצים על Edit (עריכה) ומעדכנים את הערך הנוכחי של access_key ושל secret_key. הערה: הערך של frontend_api_id יופיע בקטע 3.1.4 במסמך הזה. מומלץ להשתמש באזור us-east-1. עם זאת, אם אתם רוצים לפרוס באזור אחר, חשוב להעתיק את קובץ ה-AMI שפורס לחשבון שלכם או לבצע פיתוח עצמאי באמצעות הסקריפטים שסופקו.

2. Codelab בנושא בדיקות מקומיות
אתם יכולים להשתמש בכלי הבדיקה המקומי במחשב כדי לבצע צבירת נתונים וליצור דוחות סיכום באמצעות דוחות ניפוי הבאגים הלא מוצפנים.
השלבים ב-Codelab
שלב 2.1. הפעלת הדוח: מפעילים את הדיווח על צבירת נתונים פרטית כדי שאפשר יהיה לאסוף את הדוח.
שלב 2.2. יצירת דוח ניפוי באגים שניתן לצבור: המרת דוח ה-JSON שנאסף לדוח בפורמט AVRO.
השלב הזה יהיה דומה למה שקורה כשטכנאי הפרסום אוספים את הדוחות מנקודות הקצה לדיווח של ה-API וממירים את דוחות ה-JSON לדוחות בפורמט AVRO.
שלב 2.3. לנתח את מפתח הקטגוריה מדוח ניפוי הבאגים: מפתחות הקטגוריות תוכננו על ידי טכנאי פרסום. ב-codelab הזה, מאחר שהקטגוריות מוגדרות מראש, מאחזרים את מפתחות הקטגוריות כפי שצוינו.
שלב 2.4. יצירת קובץ AVRO של דומיין הפלט: אחרי שמאחזרים את מפתחות הקטגוריה, יוצרים את קובץ ה-AVRO של דומיין הפלט.
שלב 2.5. יצירת דוחות סיכום באמצעות הכלי לבדיקות מקומיות: אפשר להשתמש בכלי לבדיקות מקומיות כדי ליצור דוחות סיכום בסביבה המקומית.
שלב 2.6. בודקים את דוח הסיכום: בודקים את דוח הסיכום שנוצר על ידי כלי הבדיקה המקומי.
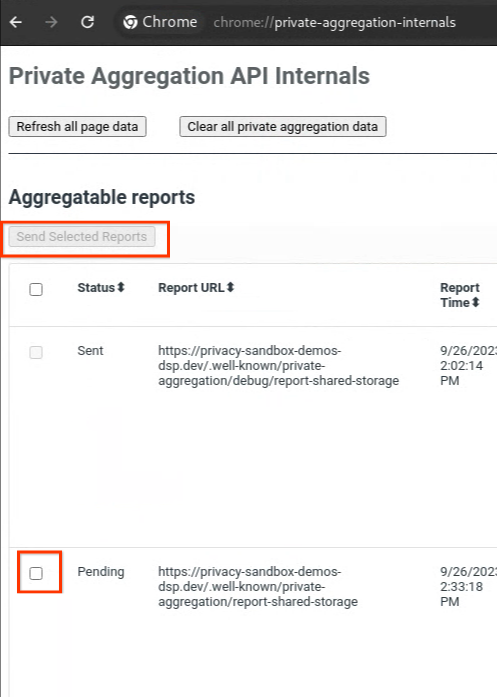
2.1. דוח טריגרים
נכנסים לאתר הדגמה של ארגז החול לפרטיות. הפעולה הזו תגרום ליצירה של דוח צבירת נתונים פרטי. אפשר להציג את הדוח בכתובת chrome://private-aggregation-internals.
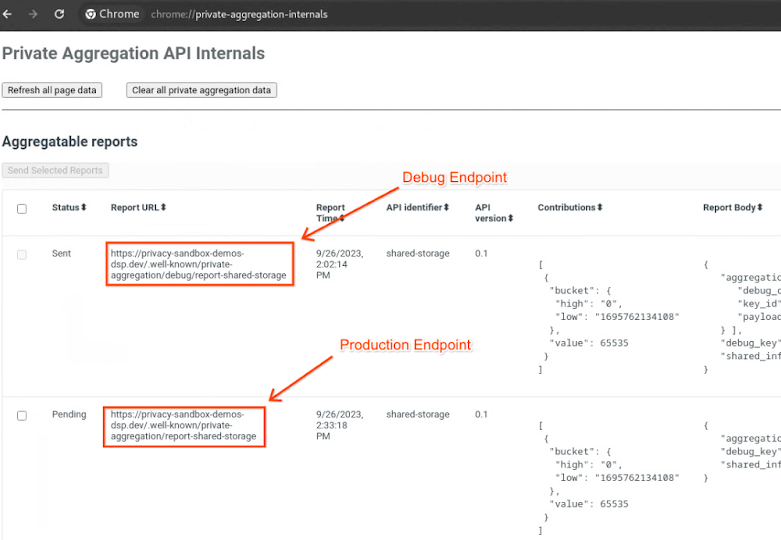
אם הדוח נמצא בסטטוס בהמתנה, אפשר לבחור את הדוח וללחוץ על שליחת הדוחות שנבחרו.
2.2. יצירת דוח ניפוי באגים שניתן לצבור
ב-chrome://private-aggregation-internals, מעתיקים את Report Body (גוף הדוח) שקיבלתם בנקודת הקצה [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
מוודאים שבגוף הדוח, השדה aggregation_coordinator_origin מכיל את הערך https://publickeyservice.msmt.aws.privacysandboxservices.com, כלומר שהדוח הוא דוח שאפשר לצבור ב-AWS.
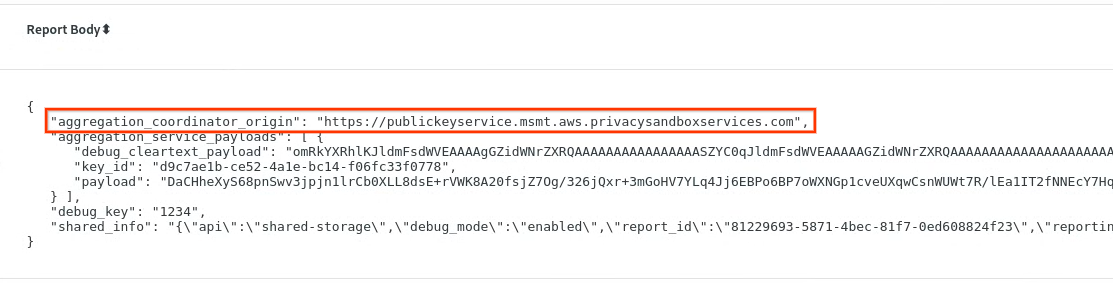
מניחים את ה-JSON 'Report Body' בקובץ JSON. בדוגמה הזו אפשר להשתמש ב-vim. אבל אפשר להשתמש בכל עורך טקסט שרוצים.
vim report.json
מדביקים את הדוח ב-report.json ושומרים את הקובץ.

לאחר מכן, עוברים לתיקיית הדוחות ומשתמשים ב-aggregatable_report_converter.jar כדי ליצור את הדוח של ניפוי הבאגים שניתן לצבור. הפקודה הזו יוצרת דוח שניתן לצבור בשם report.avro בספרייה הנוכחית.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. ניתוח מפתח הקטגוריה מדוח ניפוי הבאגים
כדי לקבץ נתונים ב-Aggregation Service, צריך שני קבצים. הדוח שניתן לצבור ואת קובץ הפלט של הדומיין. קובץ הדומיין של הפלט מכיל את המפתחות שרוצים לאחזר מהדוחות שאפשר לצבור. כדי ליצור את הקובץ output_domain.avro, צריך את מפתחות הקטגוריות שאפשר לאחזר מהדוחות.
מפתחות הקטגוריות עוצבו על ידי מבצע הקריאה ל-API, והדמו מכיל דוגמאות למפתחות קטגוריות שנוצרו מראש. מכיוון שבהדגמה הופעל מצב ניפוי באגים לצבירה פרטית, אפשר לנתח את מטען הנתונים לניפוי באגים בטקסט ללא הצפנה מגוף הדוח כדי לאחזר את מפתח הקטגוריה. עם זאת, במקרה הזה, מפתחות הקטגוריות נוצרים באתר privacy sandbox demo. מכיוון שהצברת הנתונים הפרטית באתר הזה נמצאת במצב ניפוי באגים, אפשר להשתמש ב-debug_cleartext_payload מגוף הדוח כדי לקבל את מפתח הקטגוריה.
מעתיקים את debug_cleartext_payload מגוף הדוח.

פותחים את הכלי Debug payload decoder for Private Aggregation, מדביקים את debug_cleartext_payload בתיבה INPUT ולוחצים על Decode.
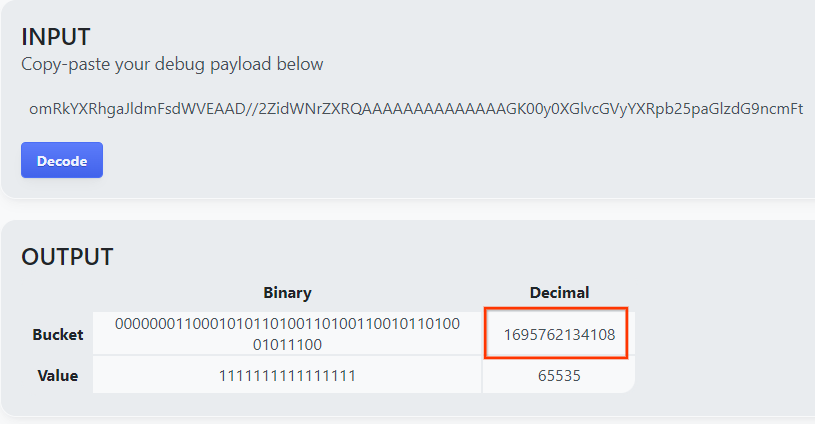
הדף מחזיר את הערך העשרוני של מפתח הקטגוריה. לפניכם מפתח קטגוריה לדוגמה.
2.4. יצירת דומיין הפלט AVRO
עכשיו, אחרי שקיבלנו את מפתח הקטגוריה, אפשר להעתיק את הערך העשרוני של מפתח הקטגוריה. ממשיכים ליצור את output_domain.avro באמצעות מפתח הקטגוריה. חשוב להחליף את
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
הסקריפט יוצר את הקובץ output_domain.avro בתיקייה הנוכחית.
2.5. יצירת דוחות סיכום באמצעות הכלי לבדיקות מקומיות
כדי ליצור את דוחות הסיכום, נשתמש בקובץ LocalTestingTool_{version}.jar שהורדתם בקטע 1.1. משתמשים בפקודה הבאה. צריך להחליף את LocalTestingTool_{version}.jar בגרסה שהורדתם ל-LocalTestingTool.
מריצים את הפקודה הבאה כדי ליצור דוח סיכום בסביבת הפיתוח המקומית:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
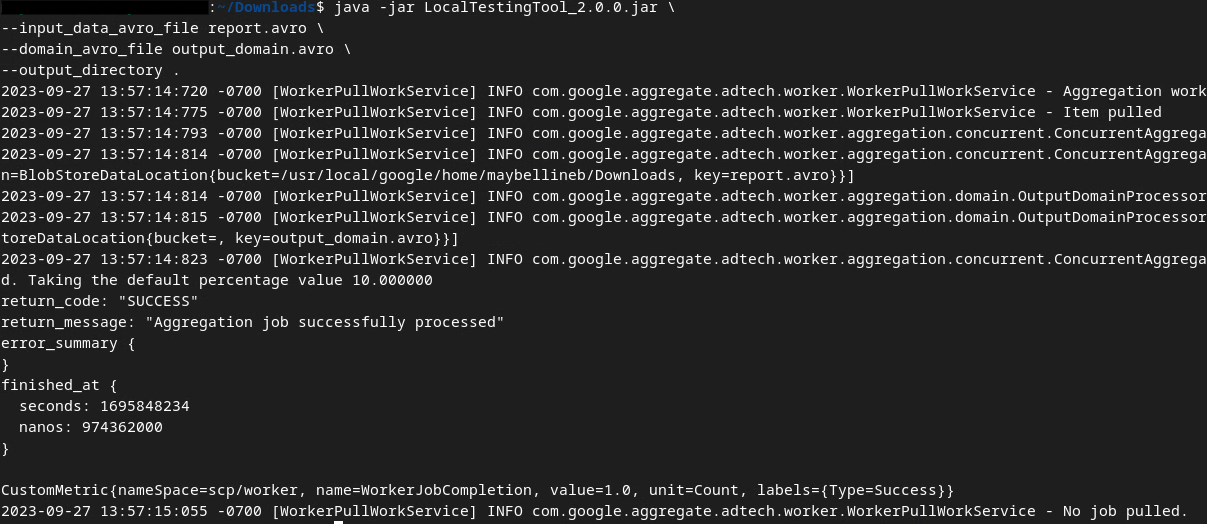
אחרי הרצת הפקודה, אמורה להופיע תמונה דומה לזו: בסיום התהליך נוצר דוח output.avro.
2.6. בדיקת דוח הסיכום
דוח הסיכום שנוצר הוא בפורמט AVRO. כדי שתוכלו לקרוא את הקובץ, צריך להמיר אותו מ-AVRO לפורמט JSON. באופן אידיאלי, טכנולוגיית הפרסום צריכה לקודד כדי להמיר דוחות AVRO בחזרה ל-JSON.
ב-Codelab שלנו, נשתמש בכלי aggregatable_report_converter.jar שסופק כדי להמיר את הדוח בפורמט AVRO בחזרה ל-JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
הפקודה הזו מחזירה דוח שדומה לתמונה הבאה. יחד עם דוח output.json שנוצר באותה ספרייה.

פותחים את קובץ ה-JSON בכלי עריכה לבחירתכם כדי לבדוק את דוח הסיכום.
3. פריסה של Aggregation Service
כדי לפרוס את Aggregation Service, פועלים לפי השלבים הבאים:
שלב 3. פריסת Aggregation Service: פריסת Aggregation Service ב-AWS
שלב 3.1. שכפול המאגר של Aggregation Service
שלב 3.2. מורידים יחסי תלות שנוצרו מראש
שלב 3.3. יוצרים סביבת פיתוח
שלב 3.4. פריסה של Aggregation Service
3.1. שכפול המאגר של Aggregation Service
בסביבה המקומית, משכפלים את מאגר GitHub של שירות הצבירה.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. הורדת יחסי תלות מוכנים מראש
אחרי שמשכפלים את המאגר של שירות הצבירה, עוברים לתיקיית Terraform של המאגר ולתיקיית הענן המתאימה. אם הערך של cloud_provider הוא AWS, אפשר להמשיך לשלב
cd <repository_root>/terraform/aws
ב-download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3. יצירת סביבת פיתוח
יוצרים סביבה לפיתוח ב-dev.
mkdir dev
מעתיקים את תוכן התיקייה demo לתיקייה dev.
cp -R demo/* dev
עוברים לתיקייה dev.
cd dev
מעדכנים את הקובץ main.tf ומקישים על i למשך input כדי לערוך את הקובץ.
vim main.tf
מבטלים את ההערה לקוד בתיבה האדומה על ידי הסרת הסימן # ועדכון שמות הקטגוריה והמפתח.
ב-AWS main.tf:
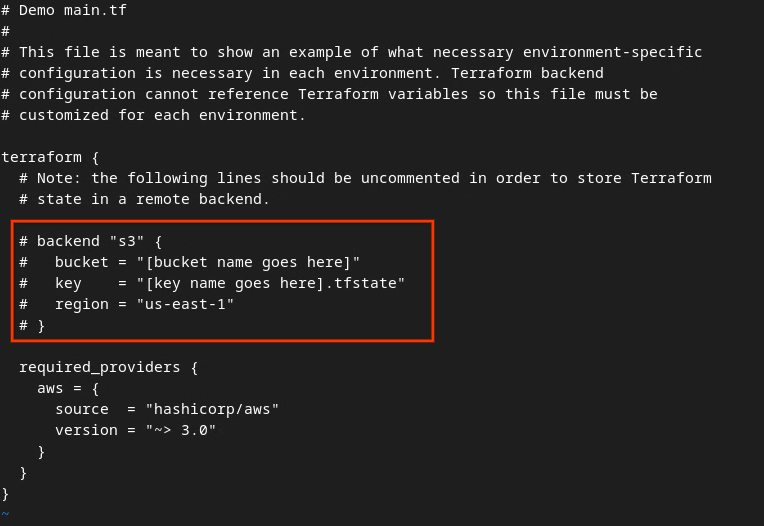
הקוד ללא התגובות אמור להיראות כך.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
אחרי שמסיימים את העדכונים, שומרים אותם ויוצאים מהעורך בלחיצה על esc -> :wq!. כך העדכונים יישמרו ב-main.tf.
לאחר מכן, משנים את השם של example.auto.tfvars ל-dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
מעדכנים את dev.auto.tfvars ומקישים על i עבור input כדי לערוך את הקובץ.
vim dev.auto.tfvars
מעדכנים את השדות בתיבה האדומה בתמונה הבאה באמצעות הפרמטרים הנכונים של AWS ARN שסופקו במהלך ההצטרפות לשירות הצבירה, בסביבה ובאימייל לקבלת התראות.
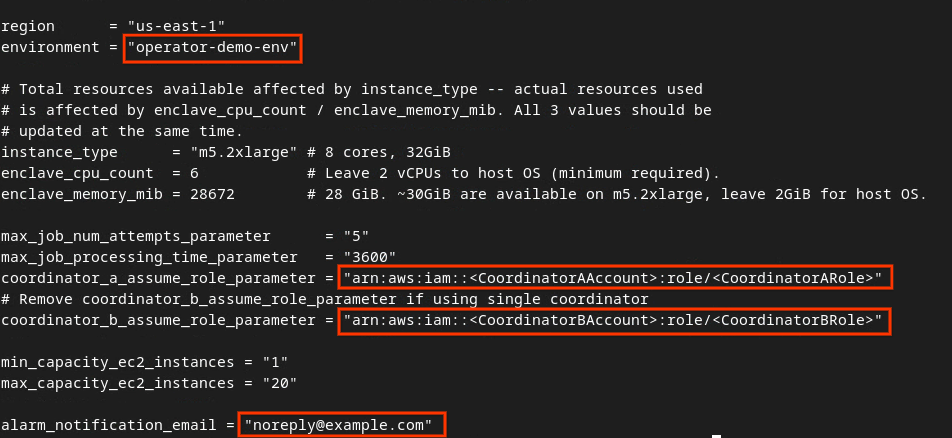
בסיום העדכונים, מקישים על esc -> :wq!. הפעולה הזו שומרת את הקובץ dev.auto.tfvars, והוא אמור להיראות בערך כמו בתמונה הבאה.
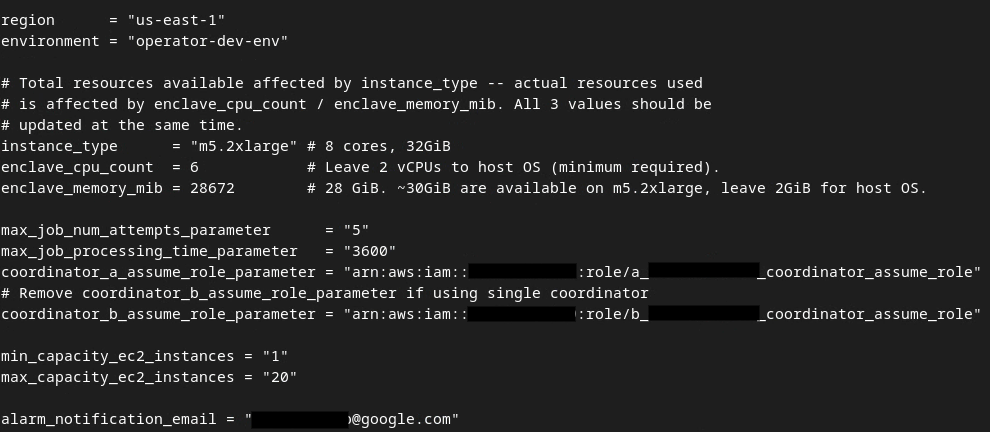
3.4. פריסה של Aggregation Service
כדי לפרוס את Aggregation Service, מאתחלים את Terraform באותה תיקייה
terraform init
התוצאה אמורה להיות דומה לתמונה הבאה:
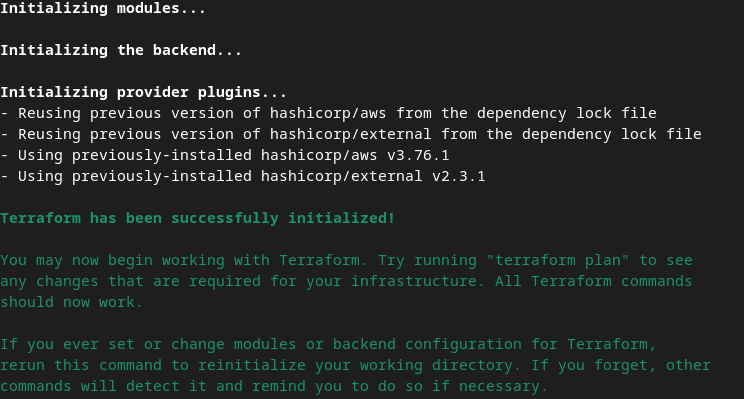
אחרי שמפעילים את Terraform, יוצרים את תוכנית הביצוע של Terraform. המספר של המשאבים שצריך להוסיף ומידע נוסף, בדומה לתמונה הבאה.
terraform plan
בהמשך מופיע הסיכום של התוכנית. אם מדובר בפריסה חדשה, אמור להופיע מספר המשאבים שיתווספו, עם 0 לשינוי ו-0 להשמדה.
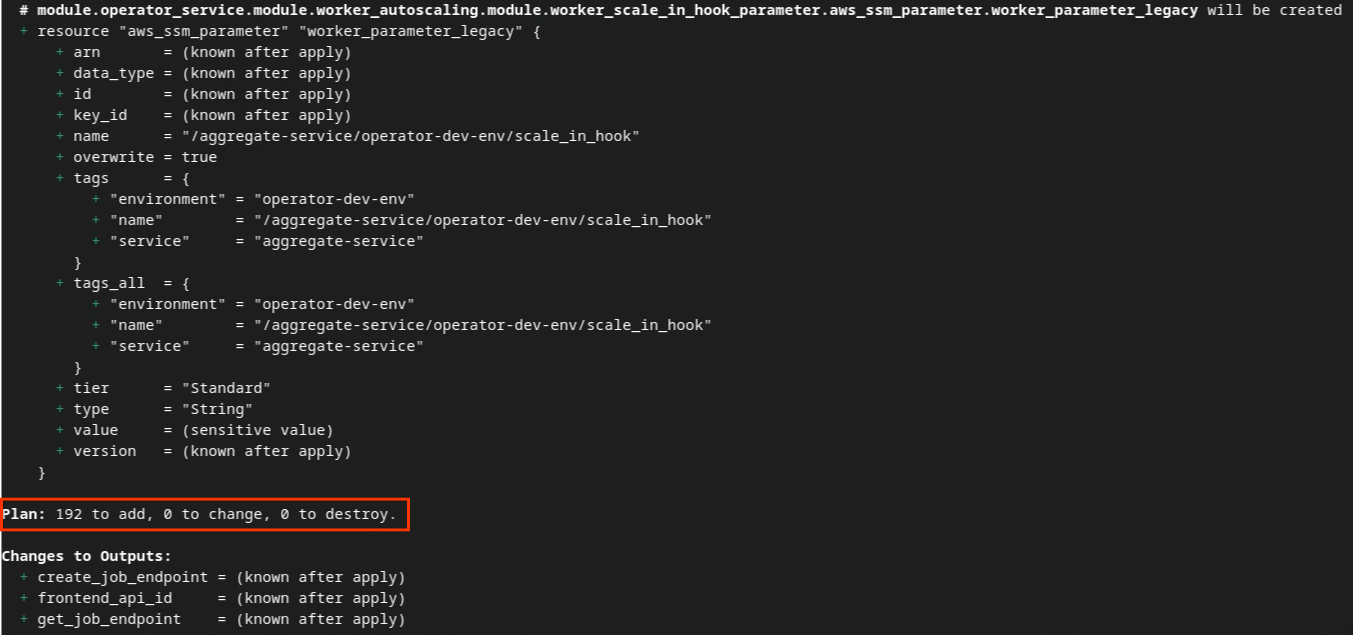
לאחר מכן תוכלו להמשיך להחיל את Terraform.
terraform apply
כשתופיע בקשה לאשר את ביצוע הפעולות על ידי Terraform, מזינים yes בערך.
בסיום הקריאה של terraform apply, נקודות הקצה הבאות של createJob ו-getJob יחזרו. המערכת גם מחזירה את הערך של frontend_api_id שצריך לעדכן ב-Postman בקטע 1.9.

4. יצירת קלט של Aggregation Service
ממשיכים ליצור את דוחות ה-AVRO לצבירה ב-Aggregation Service.
שלב 4. יצירת קלט ל-Aggregation Service: יוצרים את הדוחות של Aggregation Service שמקובצים עבור Aggregation Service.
שלב 4.1. הפעלת דוח
שלב 4.2. איסוף דוחות שאפשר לצבור
שלב 4.3. המרת דוחות ל-AVRO
שלב 4.4. יצירת דומיין הפלט AVRO
4.1. דוח טריגרים
נכנסים לאתר הדגמה של ארגז החול לפרטיות. הפעולה הזו מפעילה דוח צבירת נתונים פרטי. אפשר להציג את הדוח בכתובת chrome://private-aggregation-internals.
אם הדוח נמצא בסטטוס בהמתנה, אפשר לבחור את הדוח וללחוץ על שליחת הדוחות שנבחרו.
4.2. איסוף דוחות שאפשר לצבור
אוספים את הדוחות שאפשר לצבור מנקודות הקצה .well-known של ה-API התואם.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - דוחות שיוך (Attribution) – דוח סיכום
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
ב-Codelab הזה נעשה את אוסף הדוחות באופן ידני. בסביבת הייצור, טכנאי הפרסום אמורים לאסוף ולבצע המרה של הדוחות באופן פרוגרמטי.
ב-chrome://private-aggregation-internals, מעתיקים את Report Body (גוף הדוח) שקיבלתם בנקודת הקצה [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
מוודאים שבגוף הדוח, השדה aggregation_coordinator_origin מכיל את הערך https://publickeyservice.msmt.aws.privacysandboxservices.com, כלומר שהדוח הוא דוח שאפשר לצבור ב-AWS.
מניחים את ה-JSON 'Report Body' בקובץ JSON. בדוגמה הזו אפשר להשתמש ב-vim. אבל אפשר להשתמש בכל עורך טקסט שרוצים.
vim report.json
מדביקים את הדוח ב-report.json ושומרים את הקובץ.
4.3. המרת דוחות ל-AVRO
הדוחות שמתקבלים מנקודות הקצה .well-known הם בפורמט JSON, וצריך להמיר אותם לפורמט דוח AVRO. אחרי שתקבלו את דוח ה-JSON, תוכלו לעבור לתיקיית הדוחות ולהשתמש ב-aggregatable_report_converter.jar כדי ליצור את דוח ניפוי הבאגים שאפשר לצבור. הפקודה הזו יוצרת דוח שניתן לצבור בשם report.avro בספרייה הנוכחית.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. יצירת דומיין הפלט AVRO
כדי ליצור את הקובץ output_domain.avro, צריך את מפתחות הקטגוריות שאפשר לאחזר מהדוחות.
מפתחות הקטגוריות נוצרים על ידי טכנולוגיית הפרסום. עם זאת, במקרה הזה, מפתחות הקטגוריות נוצרים באתר Privacy Sandbox demo. מכיוון שהצברת הנתונים הפרטית באתר הזה נמצאת במצב ניפוי באגים, אפשר להשתמש ב-debug_cleartext_payload מגוף הדוח כדי לקבל את מפתח הקטגוריה.
מעתיקים את debug_cleartext_payload מתוך גוף הדוח.
פותחים את goo.gle/ags-payload-decoder, מדביקים את debug_cleartext_payload בתיבה INPUT ולוחצים על Decode.
הדף מחזיר את הערך העשרוני של מפתח הקטגוריה. לפניכם מפתח קטגוריה לדוגמה.
עכשיו, אחרי שיש לנו את מפתח הקטגוריה, אפשר ליצור את output_domain.avro. חשוב להחליף את
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
הסקריפט יוצר את הקובץ output_domain.avro בתיקייה הנוכחית.
4.5. העברת דוחות לקטגוריה ב-AWS
אחרי שיוצרים את הדוחות בפורמט AVRO (מחלקה 3.2.3) ואת דומיין הפלט (מחלקה 3.2.4), מעבירים את הדוחות ואת דומיין הפלט לקטגוריות הדיווח ב-S3.
אם הגדרתם את AWS CLI בסביבה המקומית, תוכלו להשתמש בפקודות הבאות כדי להעתיק את הדוחות לקטגוריה ולתיקיית הדוחות המתאימים ב-S3.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. שימוש ב-Aggregation Service
מה-terraform apply, מקבלים את הערכים create_job_endpoint, get_job_endpoint ו-frontend_api_id. מעתיקים את frontend_api_id ומדביקים אותו במשתנה הגלובלי frontend_api_id ב-Postman שהגדרתם בקטע 1.9 של התנאים המוקדמים.
שלב 5. שימוש ב-Aggregation Service: משתמשים ב-Aggregation Service API כדי ליצור דוחות סיכום ולעיין בדוחות הסיכום.
שלב 5.1. שימוש בנקודת הקצה createJob כדי לבצע עיבוד באצווה
שלב 5.2. שימוש בנקודת הקצה getJob כדי לאחזר את סטטוס האצווה
שלב 5.3. בדיקת דוח הסיכום
5.1. שימוש בנקודת הקצה createJob כדי ליצור קבוצות
ב-Postman, פותחים את האוסף Privacy Sandbox ובוחרים באפשרות createJob.
בוחרים באפשרות Body ובאפשרות raw כדי להוסיף את עומס העבודה של הבקשה.
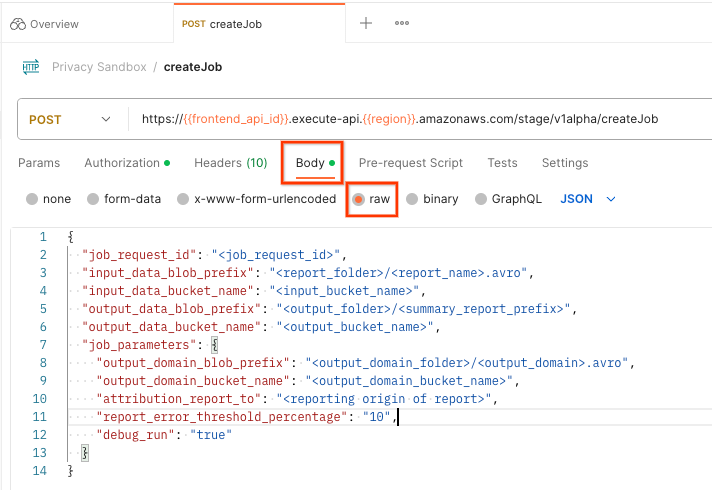
הסכימה של המטען הייעודי createJob זמינה ב-github ונראית כך: מחליפים את <> בשדות המתאימים.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
לחיצה על Send (שליחה) תיצור את המשימה עם job_request_id. לאחר שהבקשה תאושר על ידי שירות האגרגציה, אמורה להתקבל תגובה מסוג HTTP 202. קודי החזרה אפשריים אחרים מפורטים במאמר קודי תגובה של HTTP.

5.2. שימוש בנקודת הקצה getJob לאחזור סטטוס של קבוצת משימות
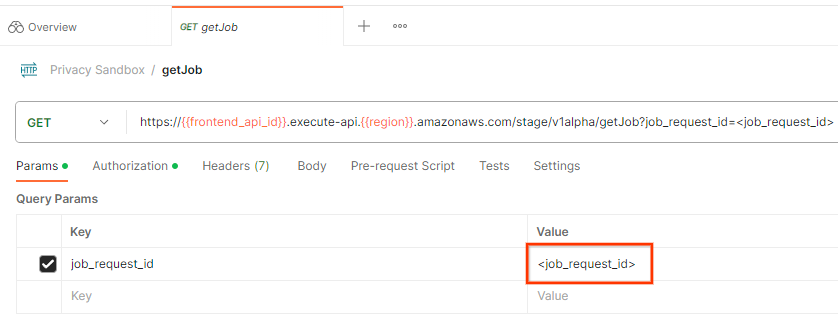
כדי לבדוק את הסטטוס של בקשת המשימה, אפשר להשתמש בנקודת הקצה getJob. בוחרים ב-getJob באוסף Privacy Sandbox.
בקטע Params, מעדכנים את הערך של job_request_id לערך job_request_id שנשלח בבקשה createJob.
התוצאה של getJob אמורה להחזיר את הסטטוס של בקשת המשימה עם סטטוס HTTP של 200. הבקשה 'Body' מכילה את המידע הנדרש, כמו job_status, return_message ו-error_messages (אם המשימה נכשלה).
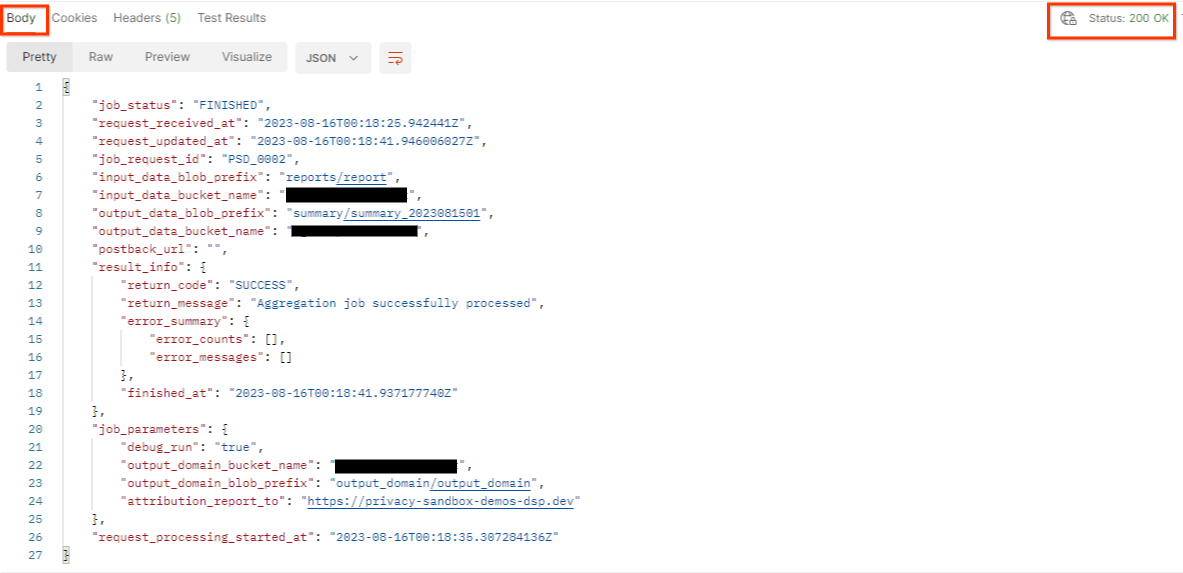
מאחר שהאתר המדווח של דוח הדגמה שנוצר שונה מהאתר שצורף לחשבון AWS שלכם, יכול להיות שתקבלו תשובה עם return_code PRIVACY_BUDGET_AUTHORIZATION_ERROR. זהו מצב תקין, כי האתר של מקור הדיווח של הדוחות לא תואם לאתר הדיווח שצורף למזהה AWS.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. בדיקת דוח הסיכום
אחרי שתקבלו את דוח הסיכום בקטגוריית ה-S3 של הפלט, תוכלו להוריד אותו לסביבה המקומית. דוחות סיכום הם בפורמט AVRO וניתן להמיר אותם בחזרה ל-JSON. אפשר להשתמש ב-aggregatable_report_converter.jar כדי לקרוא את הדוח באמצעות הפקודה הבאה.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
הפונקציה מחזירה JSON של ערכים מצטברים של כל מפתח קטגוריה, שנראה כמו התמונה הבאה.

אם הבקשה createJob כוללת את debug_run כ-true, תוכלו לקבל את דוח הסיכום בתיקיית ניפוי הבאגים שנמצאת ב-output_data_blob_prefix. הדוח בפורמט AVRO וניתן להמיר אותו ל-JSON באמצעות הפקודה הקודמת.
הדוח מכיל את מפתח הקטגוריה, את המדד ללא רעש ואת הרעש שנוסף למדד ללא רעש כדי ליצור את דוח הסיכום. הדוח נראה דומה לתמונה הבאה.

ההערות מכילות גם את הערכים in_reports ו-in_domain, שמסמנים את האפשרויות הבאות:
- in_reports – מפתח הקטגוריה זמין בדוחות שאפשר לצבור.
- in_domain – מפתח הקטגוריה זמין בקובץ ה-AVRO output_domain.