เรียนรู้ความหมายของสัญญาณรบกวน ตำแหน่งที่เพิ่ม และผลกระทบที่สัญญาณรบกวนมีต่อการวัดผล
รายงานสรุปคือผลจากการรวมรายงานที่รวบรวมได้ เมื่อรายงานที่รวบรวมได้มีการจัดกลุ่มโดยผู้รวบรวมข้อมูลและประมวลผลโดยบริการรวมข้อมูล ระบบจะเพิ่มข้อมูลเท็จ (ข้อมูลจำนวนมากแบบสุ่ม) ลงในรายงานสรุปที่ได้ มีการเพิ่มเสียงรบกวนเพื่อปกป้องความเป็นส่วนตัวของผู้ใช้ เป้าหมายของกลไกนี้คือการสร้างเฟรมเวิร์กที่รองรับการวัดผลDifferentially Private
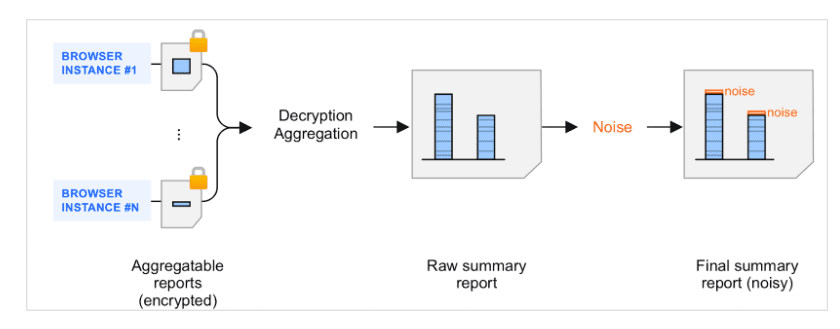
ข้อมูลเบื้องต้นเกี่ยวกับสัญญาณรบกวนในรายงานสรุป
แม้ว่าการเพิ่มสัญญาณรบกวนมักจะไม่ใช่ส่วนหนึ่งของการวัดผลโฆษณาในปัจจุบัน แต่ในหลายกรณี สัญญาณรบกวนดังกล่าวก็ไม่ได้เปลี่ยนวิธีตีความผลลัพธ์อย่างมีนัยสำคัญ
เราขอแนะนำให้คุณคำนึงถึงสิ่งเหล่านี้ในลักษณะต่อไปนี้ คุณจะมั่นใจไหมที่จะตัดสินใจตามข้อมูลบางส่วนหากข้อมูลนั้นไม่ไม่ชัดเจน
ตัวอย่างเช่น ผู้ลงโฆษณาจะมั่นใจหรือไม่ที่จะเปลี่ยนกลยุทธ์หรืองบประมาณแคมเปญโดยพิจารณาจากข้อเท็จจริงที่ว่าแคมเปญ A มี Conversion 15 รายการและแคมเปญ B มี 16 รายการ
หากคำตอบคือไม่ Noise นั้นไม่เกี่ยวข้อง
คุณจะต้องกำหนดค่าการใช้ API ในลักษณะต่อไปนี้
- คำตอบของคำถามด้านบนคือใช่
- ระบบจะจัดการเสียงรบกวนในลักษณะที่ไม่ส่งผลกระทบอย่างมากต่อความสามารถในการตัดสินใจโดยอิงตามข้อมูลบางอย่าง โดยสามารถทำได้ดังนี้ สำหรับจำนวน Conversion ขั้นต่ำที่คาดไว้ คุณต้องรักษาสัญญาณรบกวนในเมตริกที่รวบรวมไว้ให้ต่ำกว่า % ที่กำหนด
ในส่วนนี้และต่อไปนี้เราจะอธิบายถึงกลยุทธ์เพื่อบรรลุเป้าหมาย 2 ข้อ
แนวคิดหลัก
บริการรวมข้อมูลจะเพิ่มข้อมูลเพียงครั้งเดียวลงในค่าสรุปแต่ละค่า นั่นคือ 1 ครั้งต่อคีย์ ทุกครั้งที่มีการขอรายงานสรุป
ค่าสัญญาณรบกวนเหล่านี้มาจากการแจกแจงความน่าจะเป็นแบบเฉพาะเจาะจง ซึ่งจะกล่าวถึงด้านล่าง
องค์ประกอบทั้งหมดที่มีผลต่อสัญญาณรบกวนต้องอาศัยแนวคิดหลัก 2 ประการ
การกระจายของสัญญาณรบกวน (รายละเอียดด้านล่าง) จะเหมือนกันไม่ว่าค่าสรุปจะเป็นค่าต่ำหรือสูง ดังนั้น ยิ่งค่าสรุปสูงเท่าใด ก็ยิ่งมีโอกาสที่จะส่งผลกระทบน้อยลงเมื่อเทียบกับค่านี้
ตัวอย่างเช่น สมมติว่ามูลค่าการซื้อรวมทั้งหมดเท่ากับ 600, 000 บาท และมูลค่าการซื้อรวมทั้งหมดเท่ากับ 6,000 บาท ขึ้นอยู่กับสัญญาณรบกวนที่เลือกจากการกระจายเดียวกัน
สมมติว่าสัญญาณรบกวนจากการกระจายนี้แปรผันระหว่าง -100 และ +100 โดยประมาณ
- สำหรับมูลค่าการซื้อโดยสรุปที่ $20,000 สัญญาณรบกวนจะอยู่ระหว่าง 0 ถึง 100/20,000=0.5%
- สำหรับมูลค่าการซื้อโดยสรุปที่ 6, 000 บาท สัญญาณรบกวนจะอยู่ระหว่าง 0 ถึง 100/200=50%
ดังนั้น Noise จึงมีแนวโน้มที่จะส่งผลกระทบต่อมูลค่าการซื้อโดยรวม $20,000 ต่ำกว่ามูลค่า $200 หากมองในแง่นี้ ตัวเลข $20,000 มีแนวโน้มที่จะมีเสียงดังน้อยกว่า ซึ่งมีแนวโน้มที่จะมีอัตราส่วนสัญญาณต่อสัญญาณรบกวนสูงกว่า
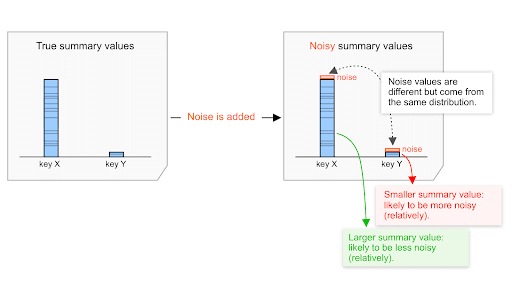
ซึ่งจะมีนัยสำคัญในทางปฏิบัติที่สำคัญ 2-3 ประการซึ่งจะกล่าวถึงในส่วนถัดไป กลไกนี้เป็นส่วนหนึ่งของการออกแบบ API ซึ่งจะมีผลในระยะยาว และจะยังคงมีบทบาทสำคัญต่อไปเมื่อเทคโนโลยีโฆษณาออกแบบและประเมินกลยุทธ์ในการรวบรวมข้อมูลแบบต่างๆ
แม้ว่าสัญญาณรบกวนจะมาจากการกระจายเดียวกันโดยไม่คำนึงถึงค่าสรุป แต่การกระจายนั้นจะขึ้นอยู่กับพารามิเตอร์หลายตัว หนึ่งในพารามิเตอร์เหล่านี้คือ epsilon อาจมีการดัดแปลงโดยเทคโนโลยีโฆษณาระหว่างช่วงทดลองใช้จากต้นทางที่สรุปผลแล้ว เพื่อประเมินการปรับเปลี่ยนด้านยูทิลิตี/ความเป็นส่วนตัวหลายรายการ อย่างไรก็ตาม ให้พิจารณาความสามารถในการปรับแต่ง epsilon แบบชั่วคราว เรายินดีรับฟังความคิดเห็นของคุณเกี่ยวกับกรณีการใช้งานและคุณค่าของ epsilon ที่ใช้ได้ดี
แม้ว่าบริษัทเทคโนโลยีโฆษณาจะไม่สามารถควบคุมวิธีการเพิ่มสัญญาณรบกวนได้โดยตรง แต่ก็สามารถส่งผลต่อผลกระทบของสัญญาณรบกวนที่มีต่อข้อมูลการวัดผลได้ ในส่วนถัดไป เราจะเจาะลึกถึงวิธีที่ระบบสร้างอิทธิพลต่อสัญญาณรบกวนในทางปฏิบัติ
ก่อนเราจะพูดถึงนั้น เรามาดูการใช้เสียงรบกวนอย่างละเอียดกัน
การซูมเข้า: วิธีใช้เสียงรบกวน
การกระจายสัญญาณรบกวน 1 จุด
เสียงรบกวนจะดึงมาจากการกระจาย Laplace โดยมีพารามิเตอร์ต่อไปนี้
- ค่าเฉลี่ย (
μ) ของ 0 ซึ่งหมายความว่าค่าสัญญาณรบกวนที่เป็นไปได้มากที่สุดคือ 0 (ไม่มีการเพิ่มสัญญาณรบกวน) และค่าที่มีเสียงรบกวนจะน้อยกว่าค่าเดิมเนื่องจากสูงกว่า (บางครั้งเรียกว่าเป็นกลาง) - พารามิเตอร์สเกลเป็น
b = CONTRIBUTION_BUDGET/epsilon- มีการกำหนด
CONTRIBUTION_BUDGETในเบราว์เซอร์ วันที่ - มีการแก้ไข
epsilonในเซิร์ฟเวอร์การรวม
- มีการกำหนด
แผนภาพต่อไปนี้แสดงฟังก์ชันความหนาแน่นของความน่าจะเป็นสำหรับการแจกแจงแบบลาปลาซด้วย μ=0, b = 20
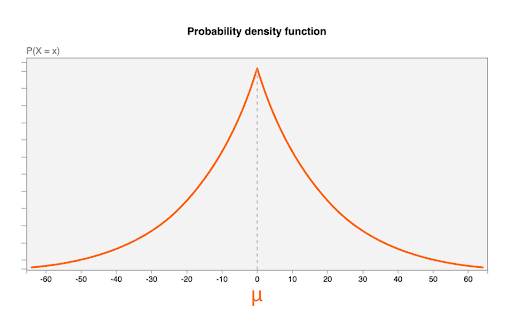
ค่าสัญญาณรบกวนแบบสุ่ม การกระจายสัญญาณรบกวน 1 รายการ
สมมติว่าเทคโนโลยีโฆษณาหนึ่งขอรายงานสรุปสำหรับคีย์การรวม 2 คีย์ คือคีย์1 และคีย์2
บริการรวมจะเลือกค่าสัญญาณรบกวน 2 ค่า คือ x1 และ x2 ตามการกระจายสัญญาณรบกวนเดียวกัน ระบบจะเพิ่ม x1 ลงในค่าสรุปสำหรับคีย์ 1 และจะเพิ่ม x2 ลงในค่าสรุปสำหรับคีย์ 2
ในแผนภาพ เราจะแสดงค่าสัญญาณรบกวนว่าเหมือนกัน นี่คือการลดความซับซ้อน ในความเป็นจริง ค่าสัญญาณรบกวนจะแตกต่างกันเนื่องจากสุ่มมาจากการกระจาย
ตัวอย่างนี้แสดงให้เห็นว่าค่าสัญญาณรบกวนทั้งหมดมาจากการกระจายเดียวกัน และเป็นอิสระจากค่าสรุปที่ใช้
คุณสมบัติอื่นๆ ของเสียงรบกวน
ระบบจะใช้เสียงรบกวนกับค่าสรุปทุกค่า รวมถึงค่าว่าง (0)
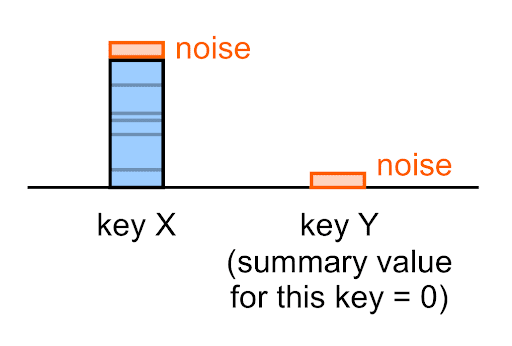
ตัวอย่างเช่น แม้ว่าค่าสรุปที่แท้จริงสำหรับคีย์ที่ระบุจะเป็น 0 แต่ค่าสรุปที่ไม่ชัดเจนซึ่งคุณจะเห็นในรายงานสรุปของคีย์นี้จะ (ส่วนใหญ่) ไม่ใช่ 0
เสียงรบกวนอาจเป็นตัวเลขบวกหรือจำนวนลบก็ได้
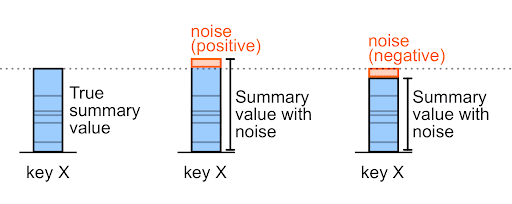
ตัวอย่างเช่น สําหรับยอดรวมการซื้อก่อนเสียงรบกวนจำนวน 327,000 รายการ สัญญาณรบกวนอาจเป็น +6,000 หรือ -6,000 (เป็นค่าตัวอย่างที่กำหนดเอง)
กำลังประเมินเสียงรบกวน
การคำนวณค่าเบี่ยงเบนมาตรฐานของสัญญาณรบกวน
ค่าเบี่ยงเบนมาตรฐานของสัญญาณรบกวนคือ
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2)
ตัวอย่าง
เมื่อใช้ epsilon = 10 ค่าเบี่ยงเบนมาตรฐานของสัญญาณรบกวนคือ
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2) = (65,536/10)*sqrt(2) = 9,267
ประเมินเมื่อความแตกต่างในการวัดผลมีนัยสำคัญ
เนื่องจากคุณจะทราบค่าเบี่ยงเบนมาตรฐานของสัญญาณรบกวนที่เพิ่มในแต่ละเอาต์พุตค่าโดยบริการการรวม คุณจึงสามารถกำหนดเกณฑ์ที่เหมาะสมในการเปรียบเทียบได้ เพื่อพิจารณาว่าความแตกต่างที่พบอาจเกิดจากสัญญาณรบกวนหรือไม่
เช่น หากสัญญาณรบกวนที่เพิ่มลงในค่ามีค่าประมาณ +/- 10 (ซึ่งคิดเป็นการปรับขนาด) และความแตกต่างของค่าระหว่าง 2 แคมเปญสูงกว่า 100 ก็น่าจะสรุปได้ว่าความแตกต่างของค่าที่วัดระหว่างแต่ละแคมเปญไม่ได้เกิดจากสัญญาณรบกวนเพียงอย่างเดียว
วันที่มีส่วนร่วมและแชร์ความคิดเห็น
คุณสามารถเข้าร่วมและทดสอบกับ API นี้
- อ่านเกี่ยวกับรายงานที่รวบรวมได้และบริการรวบรวมข้อมูล ถามคำถาม และแนะนำความคิดเห็น
- อ่านคู่มือการรายงานการระบุแหล่งที่มา
- ถามคำถามและเข้าร่วมการสนทนาในที่เก็บการสนับสนุนนักพัฒนาซอฟต์แวร์ Privacy Sandbox
ขั้นตอนถัดไป
- หากต้องการดูตัวแปรที่คุณควบคุมได้เพื่อปรับปรุงอัตราส่วนสัญญาณต่อเสียงรบกวน โปรดดูการทำงานกับเสียงรบกวน
- อ่านหัวข้อทดสอบการตัดสินใจออกแบบรายงานสรุปเพื่อรับความช่วยเหลือในการวางแผนกลยุทธ์การรายงานข้อมูลสรุป
- ลองใช้ Noise Lab ดู