שירות הצבירה מפיק דוחות סיכום של נתוני המרות מפורטים ומדידות של היקף החשיפה מדוחות נצברים גולמיים. לטכנולוגיות הפרסום יש שתי נקודות כניסה ראשיות לנתונים מצטברים בצד הלקוח, כדי להעביר דוחות לשירות הצבירה. הנקודות האלה הן Attribution Reporting API או Private Aggregation API.
סטטוס ההטמעה
- שירות הצבירה עבר עכשיו לזמינות לכלל המשתמשים.
- אפשר להשתמש ב-Aggregation Service עם Attribution Reporting API ו-Private Aggregation API עבור Protected Audience API ו-Shared Storage API.
זמינות
| Proposal | Status |
|---|---|
| Aggregation Service support for Amazon Web Services (AWS) across Attribution Reporting API, Private Aggregation API
Explainer |
Available |
| Aggregation Service support for Google Cloud across Attribution Reporting API, Private Aggregation API Explainer |
Available |
| Aggregation Service site enrollment and multi-origin aggregation. Site enrollment includes mapping of a site to cloud accounts (AWS, or GCP). To aggregate multiple origins, they must be of the same site.
FAQs on GitHub Site aggregation API documentation |
Available |
| The Aggregation Service's epsilon value will be kept as a range of up to 64, to facilitate experimentation and feedback on different parameters.
Submit ARA epsilon feedback. Submit PAA epsilon feedback. |
Available. We will provide advanced notice to the ecosystem before the epsilon range values are updated. |
| More flexible contribution filtering for Aggregation Service queries
Explainer |
Available |
| Process for budget recovery post-disasters (errors, misconfigurations, and so on)
Explainer |
Available Mechanism to review the percentage of shared IDs recovered by an ad tech using budget recovery and suspend future recoveries for excessive recoveries planned for H1 2025 |
| Accenture operating as one of the Coordinators on AWS
Developer Blog |
Available |
| Independent party operating as one of the Coordinators on Google Cloud
Developer blog |
Available |
| Aggregation Service support for Aggregate Debug Reporting on Attribution Reporting API
Explainer |
Available |
מונחי מפתח ומושגים מרכזיים
אם אתם שוקלים להשתמש בשירות הצבירה בתהליך העבודה שלכם בתחום טכנולוגיית הפרסום, המונחים והמושגים הבאים יעזרו לכם להבין טוב יותר את היתרונות של תהליך הצבירה החדש הזה לצוות שלכם:
| Term | Description |
|---|---|
| Aggregation Service | An ad tech-operated service that processes aggregatable reports to create a summary report. |
| Aggregatable Reports |
דוחות נצברים הם דוחות מוצפנים שנשלחים ממכשירים של משתמשים ספציפיים. הדוחות האלה מכילים נתונים לגבי התנהגות והמרות של משתמשים באתרים שונים. ההמרות (שלפעמים נקראים אירועי טריגר של שיוך (Attribution)) והמדדים המשויכים מוגדרים על ידי המפרסם או טכנולוגיית הפרסום. כל דוח מוצפן כדי למנוע מגורמים שונים גישה לנתונים הבסיסיים. Learn more about aggregatable reports. |
| Aggregatable Report Accounting | A distributed ledger located in both coordinators that tracks allocated privacy budget and enforces the 'No Duplicates' rule. This is the privacy preserving mechanism, located and run within coordinators, that ensures that no report passes through Aggregation Service beyond the allocated privacy budget. Read more on batching strategies on how it relates to aggregatable reports. |
| Aggregatable Report Accounting Budget | References to the budget that ensures reports are not processed more than once. |
| Trusted Execution Environment (TEE) |
A trusted execution environment is a special configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the computer. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less. To learn more about TEEs used for the Privacy Sandbox proposals, read the Protected Audience API services explainer and the Aggregation Service explainer. |
| Coordinators |
מתאם הוא ישות שאחראית לניהול מפתחות ולחשבונאות דוחות ניתנת לצבירה. המתאם מנהל רשימת גיבובים של הגדרות שירות שאושרו לצבירה ומגדיר את הגישה למפתחות פענוח. |
| Shared ID |
Computed value that consists of: shared_info, reporting_origin, destination_site (available for Attribution Reporting API only), source_registration-time (available for Attribution Reporting API only), scheduled_report_time, version.
This means that multiple reports belong to the same shared ID should they share the same attributes of the shared_info field. This plays an important role within Aggregatable Report Accounting.
Read more about Trusted Servers.
|
| Summary Report |
A summary report is an Attribution Reporting API and Private Aggregation API report type. A summary report includes aggregated user data and can contain detailed conversion data, with noise added. Summary reports are made up of aggregate reports. Summary reports allow for greater flexibility and a richer data model than event-level reporting, particularly for some use-cases like conversion values. |
| Reporting Origin |
מקור הדיווח הוא הישות שמקבלת דוחות נצברים. במילים אחרות, טכנולוגיית הפרסום שנקרא 'Attribution Reporting API'. דוחות נצברים נשלחים מאת מכשירים של משתמשים לכתובת URL ידועה שמשויכת לדיווח המקור. צריך לציין את מקור הדיווח הזה במהלך הרישום. |
| Contribution Bonding | Aggregatable reports may contain an arbitrary number of counter increments. For example, a report may contain a count of products that a user has viewed on an advertiser's site. The sum of increments in all aggregatable reports related to a single source event must not exceed a given limit, `L1=2^16`. Learn more in the aggregatable reports explainer. |
| Noise & Scaling | A certain amount of statistical noise is added to summary reports as a part of the aggregation process that also functions to preserve privacy and ensure the final reports provide anonymized measurement information. Read more about additive noise mechanism, which is drawn from Laplace distribution. |
| Attestation |
אימות (attestation) הוא מנגנון לאימות זהות התוכנה, בדרך כלל באמצעות טביעות אצבע קריפטוגרפיות או חתימות. בהצעה של שירות הצבירה, האימות תואם לקוד שפועל בשירות הצבירה המופעל על-ידי טכנולוגיות פרסום לבין קוד הקוד הפתוח. Read more about attestation. |
מידע נוסף על הרקע של שירות הצבירה זמין במאמר ההסבר וברשימת התנאים המלאה.
תרחישים לדוגמה לצבירה
נבחן את התהליכים הבאים למפתחים בנושא מדידת ביצועים של מודעות וספריות הלקוח התואמות שלהם למדידת ביצועים.
| תרחיש לדוגמה | נקודת כניסה | תיאור |
|---|---|---|
| אופטימיזציה של הבידינג | Attribution Reporting API (Chrome ו-Android) | שימוש בדוחות מצטברים כדי להטמיע אותות המרה לצורכי אופטימיזציה של הבידינג. |
| מדידה בפלטפורמות שונות | Attribution Reporting API (Chrome ו-Android) | בעזרת היכולות למדידת ביצועים באתרים ובאפליקציות תוכלו לקבל תמונה ברורה יותר של הביצועים ב-Chrome וב-Android. |
| דיווח על המרות | Attribution Reporting API (Chrome ו-Android) | ליצור דוחות המרות מצטברים שמותאמים לצורכי הקמפיינים של הלקוחות (כולל דוחות על המרות מסוג 'המרות מסוג 'קליק להמרה'' ודוחות על המרות מסוג 'קליק להצגת מודעה'). |
| מדידת היקף החשיפה של הקמפיין | Shared Storage API ו-Private Aggregation API (Chrome) | השתמשו במשתנים של צפיות במודעות באתרים שונים כדי למדוד את פוטנציאל החשיפה של הקמפיין. |
| דיווח על מאפיינים דמוגרפיים | Shared Storage API ו-Private Aggregation API (ב-Chrome) | השתמשו בתצוגת מודעות באתרים שונים ובמידע דמוגרפי כדי למדוד את פוטנציאל החשיפה לפי קבוצות דמוגרפיות. |
| ניתוח נתיב ההמרות | Shared Storage API ו-Private Aggregation API (ב-Chrome) | אחסון של צפיות במודעות באתרים שונים ומשתנים של המרות כדי לבצע ניתוח מצטבר של נתיבי המרות. |
| התחזקות המותג ועלייה בהמרות | Shared Storage API ו-Private Aggregation API (ב-Chrome) | דיווח על קבוצות ניסוי/בקרה ועל נתוני סקרים כדי למדוד את התחזקות המותג ואת העלייה המצטברת. |
| ניפוי באגים במכרזים | Protected Audience API ו-Private Aggregation API (Chrome) | שימוש בדוחות נצברים לניפוי באגים. |
| חלוקת הצעות המחיר | Protected Audience API ו-Private Aggregation API (ב-Chrome) | אפשר להשתמש בדוחות נצברים כדי לתעד את ההתפלגות של ערכי הצעות המחיר במכרזים. |
תהליך מקצה לקצה
בתרשים הבא מוצג שירות הצבירה בפעולה. נתמקד בתהליך מקצה לקצה, החל מקבלת הדוחות מהאינטרנט והנייד ועד ליצירת דוחות הסיכום בשירות הצבירה.
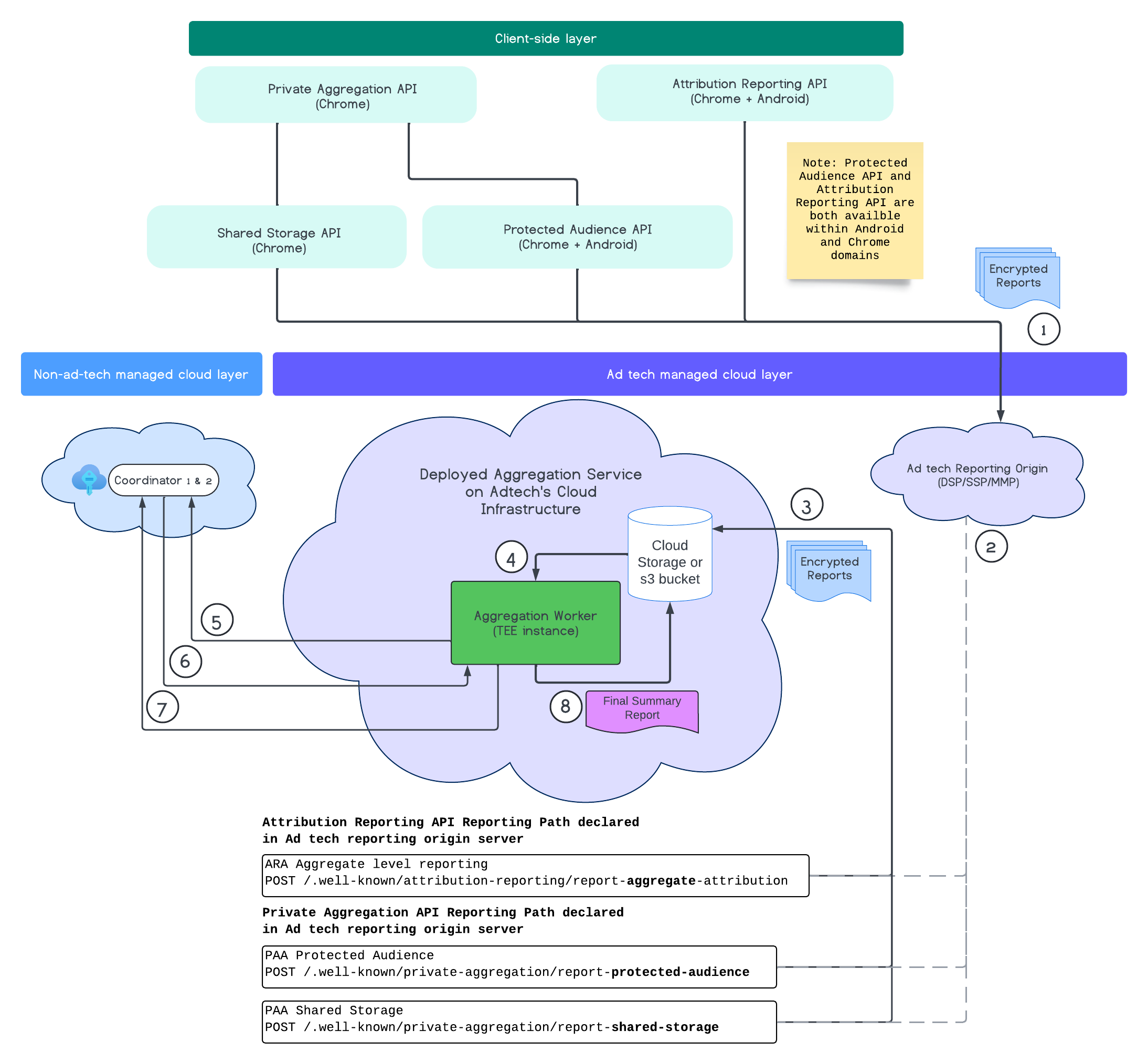
- אחזור מפתח ציבורי ליצירת דוחות מוצפנים.
- דוחות מוצפנים נצברים שנשלחים לשרתים של פרסום דיגיטלי לצורך איסוף, טרנספורמציה וקיבוץ.
- שרת טכנולוגיית הפרסום אוסף דוחות (בפורמט avro) ושולח אותם לשירות האגרגציה שנפרס. (צריך להשלים את השלב של טכנולוגיית הפרסום).
- אחזור דוחות נצברים לצורך פענוח.
- אחזור מפתחות פענוח מהרכזים.
- שירות Aggregation Service מפענח דוחות לצורך צבירה והוספת רעש.
- בדיקות של שירות חשבונאות של דוחות נצברים אם נותר תקציב פרטיות, כדי להפיק דוח סיכום לדוחות המצטברים הנתונים.
- שולחים דוח סיכום סופי.
בתרשים אפשר לראות את הקשר הכולל של שירות האגרגציה עם ממשקי ה-API העיקריים למדידת לקוחות: Attribution Reporting API, Private Aggregation API והתיאמים.
התהליך מתחיל בממשקי API שונים למדידה, כמו Attribution Reporting API או Private Aggregation API, שמייצרים דוחות מכמה מופעים בדפדפן. Chrome לוקח את המפתח הציבורי משירות אירוח המפתחות במרכז התיאום כדי להצפין את הדוחות לפני שהם נשלחים למקור הדיווח של חברת טכנולוגיית הפרסום. המפתחות הציבוריים מבצעים רוטציה מדי 7 ימים.
אחרי שמקור הדיווח של טכנולוגיית הפרסום יקבל את הדוחות האלה, צריך להגדיר את מקור הדיווח כך שיאסוף וימיר את הדוחות האלה לפורמט Avro, וישלח אותם למכונה של Aggregation Service שנפרסה. כדאי לעיין במאמר בנושא שיטות ארגון בקבוצות.
כשמערכת טכנולוגיית הפרסום מוכנה ליצירת קבוצה, היא יוצרת בקשת קבוצה לשירות המצטבר, שבו הדוחות מפענחים על ידי אחזור מפתחות הפענוח משירות אירוח המפתחות, ולאחר מכן הם נצברים ומתווסף להם רעש כדי ליצור דוח סיכום. חשוב לזכור שההחלטה הזו מותנית בשאלה אם תקציב הפרטיות מספיק כדי להפיק את דוחות הסיכום הסופיים.
נקודת הקצה המקורית לדיווח של חברת טכנולוגיית הפרסום, שבה נאספים הדוחות, מתארחת על ידי חברת טכנולוגיית הפרסום, ושירות הצבירה נפרס בענן של חברת טכנולוגיית הפרסום.
קיבוץ דוחות נצברים
תהליך הדיווח לא יושלם ללא עזרה משרת המקור הייעודי לדיווח. זהו המקור שפלטפורמת ה-AdTech הייתה שולחת בתהליך ההרשמה. הפעולות העיקריות שמקור הדיווח אחראי להן יהיו איסוף, טרנספורמציה וקיבוץ של הדוחות המצטברים שהתקבלו, והכנה שלהם לשליחה לשירות האגרגציה שנפרס של טכנולוגיית הפרסום ב-Google Cloud או ב-Amazon Web Services. מידע נוסף על הכנת דוחות שניתן לצבור
עכשיו, אחרי שהבנתם את הקונספט הכללי, נבחן לעומק את הרכיבים שיוצבו בשירות הצבירה.
רכיבי ענן
שירות הצבירה מורכב מרכיבים שונים של שירותי ענן. קובצי הסקריפטים של Terraform שסופקו והגדירו את כל הרכיבים הדרושים של שירותי ענן.
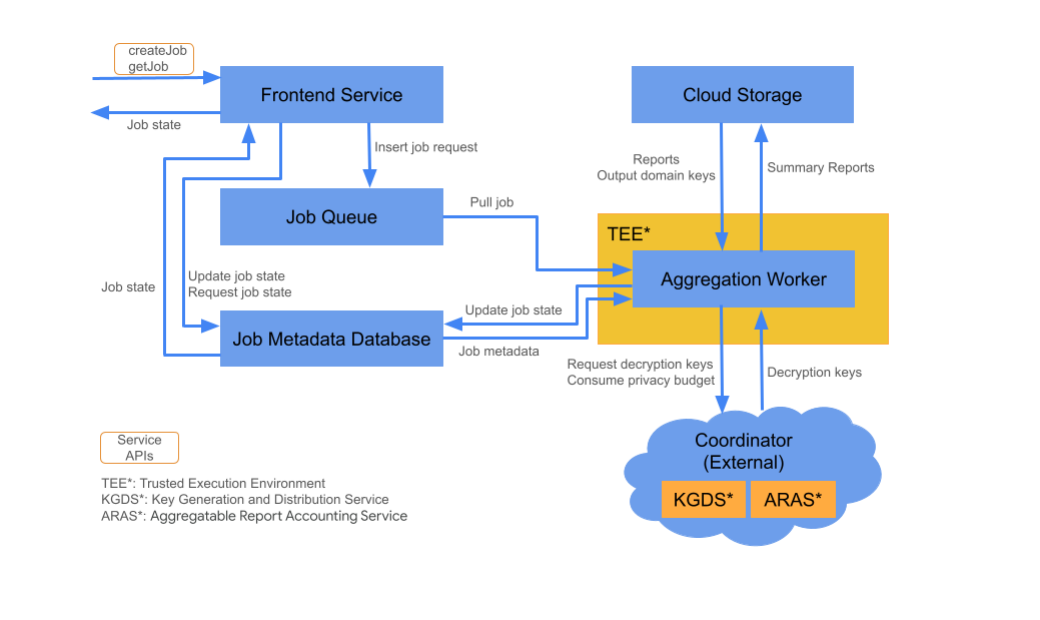
שירות לקצה הקדמי
שירות ענן מנוהל: פונקציה של Cloud Functions (Google Cloud) / שער API (Amazon Web Services)
Frontend Service הוא שער ללא שרת (serverless), שמשמש כנקודת הכניסה לקריאות ל-Aggregation API ליצירת משימות ולאחזור מצב של משימות. הוא אחראי לקבלת בקשות ממשתמשי שירות האגרגציה, לאימות הפרמטרים של הקלט ולהפעלת תהליך תזמון משימות האגרגציה.
שני ממשקי API זמינים ב-Frontend Service:
| נקודת קצה | תיאור |
|---|---|
createJob |
ה-API הזה מפעיל משימה של Aggregation Service. נדרש מידע כדי להפעיל משימה כמו מזהה משימה, פרטי אחסון קלט, פרטי אחסון פלט, מקור הדיווח ועוד. |
getJob |
ממשק ה-API הזה מחזיר את הסטטוס של משימה לפי מזהה משימה ספציפי. הוא מספק מידע על סטטוס המשימה, כמו 'נשלחה', 'בטיפול' או 'הושלמה'. בנוסף, אם המשימה הסתיימה, תופיע תוצאת המשימה, כולל הודעות השגיאה שנתקלו בהן במהלך ביצוע המשימה. |
מסמכי העזרה של Aggregation Service API
Job Queue
שירות ענן מנוהל: Pub/Sub (Google Cloud) או Amazon SQS (Amazon Web Services)
'תור המשימות' הוא תור של הודעות שמאחסן בקשות של משימות לשירות הצבירה. שירות Frontend מוסיף הודעות של בקשות משימה לתור, ואז Aggregation Worker צורכת הודעות כדי לעבד את בקשת המשימה.
אחסון בענן
שירות ענן מנוהל: Google Cloud Storage (Google Cloud) או Amazon S3 (שירותי אינטרנט של Amazon) אחסון בענן משמש לאחסון קובצי קלט ופלט שמשמשים את שירות הצבירה (לדוגמה: קובצי דוחות מוצפנים, דוחות סיכום פלט וכו').
מסד נתונים של מטא-נתונים של משימות
שירות מנוהל בענן: Spanner (Google Cloud) או DynamoDB (Amazon Web Services)
מסד נתונים של Job Metadata מאחסן ועוקב אחר הסטטוס של משימות צבירת נתונים. במסד הנתונים מתועדים מטא-נתונים כמו שעת היצירה, השעה המבוקשת, השעה המעודכנת והמצב (לדוגמה: התקבלו, בתהליך, הסתיים וכו'). Aggregation Worker מעדכן את מסד הנתונים של המשימות לפי התקדמות המשימה.
עובד צבירת נתונים
שירות ענן מנוהל: Compute Engine עם Confidential Space (Google Cloud) או Amazon Web Services EC2 עם Nitro Enclave (Amazon Web Services)
קובץ Aggregation Worker מעבד בקשות למשימות שיזומות בקשת משימה בתור המשימה, ומפענח את הקלט המוצפן באמצעות מפתחות שנשלפו מ-Key Generation and Distribution Service (KGDS) ב-Coordinator. כדי לצמצם את זמן האחזור של עיבוד המשימות, מפתחות ההצפנה נשמרים במטמון ב-Aggregation Worker למשך 8 שעות, וניתן להשתמש בהם במשימות שמעובדות על ידי מכונה עובדת זו.
העובד פועל במכונה של Trusted Execution Environment (TEE). כל עובד מטפל רק במשימה אחת בכל פעם. טכנולוגיית הפרסום יכולה להגדיר כמה עובדים לעיבוד משימות במקביל על ידי הגדרת הגדרות התאמה אוטומטית לעומס. באמצעות התאמה אוטומטית, מספר העובדים משתנה באופן דינמי בהתאם למספר ההודעות שנותרו בתור המשימות. באמצעות קובץ הסביבה של Terraform אפשר להגדיר את מספר העובדים המינימלי והמקסימלי להתאמה לעומס (auto-scaling). מידע נוסף על התאמה לעומס (autoscaling) ניתן למצוא בסקריפטים הבאים של terraform. [Amazon Web Services / Google Cloud]
Aggregation Worker קורא לשירות Aggregatable Report Accounting לגבי הנהלת דוחות נצברים. שירות החשבונאות של הדוחות המצטברים יבטיח שמשימות יופעלו רק כל עוד הוא לא חרג ממגבלת הפרטיות של התקציב. (ראו כלל 'ללא כפילויות'). אם התקציב זמין, המערכת יוצרת דוח סיכום שמבוסס על הנתונים שהצטברו עם הרעש. מידע נוסף על דיווח על דוחות שניתן לצבור
הכלי Aggregation Worker מעדכן את המטא-נתונים של המשימות במסד הנתונים של משימות, כולל קודים מתאימים של החזרת משימות ומוני שגיאות של דוחות במקרה של כשלים חלקיים בדוחות. המשתמשים יכולים לאחזר את המצב באמצעות ממשק ה-API לאחזור מצב המשימה (getJob).
תיאור מפורט יותר של שירות צבירת הנתונים זמין בהסברים שלנו.
השלבים הבאים
אחרי שסיפקנו לכם את הנקודות העיקריות של Aggregation Service, הגיע הזמן לפרוס מכונה משלכם של Aggregation Service דרך Google Cloud או Amazon Web Services. אפשר לעיין בקטע 'תחילת העבודה'. אם אתם צריכים מידע נוסף על הפעלת Aggregation Service שנפרס, תוכלו להיכנס לקישור הזה כדי לקרוא מידע נוסף על הפעלת Aggregation Service.
פתרון בעיות
במסמך קודי שגיאה נפוצים והקלות מפורטים תיאורים מפורטים יותר של הודעות השגיאה, מה יכול להיות שגרם לשגיאה שבה נתקלת והשלבים הבאים להקלה על הבעיה.
קבלת תמיכה ושליחת משוב
- אם יש לכם בעיות טכניות, שאלות לגבי המוצר, משוב או בקשות למאפיינים חדשים, אתם יכולים ליצור דיווח על בעיה במאגר שלנו ב-GitHub.
- אם יש לכם שאלות שבהן אתם צריכים לספק מידע רגיש או קנייני לצורך פתרון בעיות, תוכלו לפנות אלינו בכתובת aggregation-service-support@google.com
- כדאי לבדוק בלוח הבקרה של הסטטוס הציבורי כדי לראות אם יש בעיות ידועות.