Implementa y administra este servicio para generar informes de resumen para la API de Attribution Reporting o la API de Private Aggregation.
Implementa y administra un servicio de agregación para procesar datos informes de la API de Attribution Reporting o la API de Private Aggregation para crea un informe de resumen.
Estado de implementación
- El servicio de agregación ahora está disponible de manera general.
- El servicio de agregación se puede probar con el API de Attribution Reporting y API de Private Aggegration para la API de Protected Audience y el almacenamiento compartido.
Los esquemas de la explicación términos clave, útiles para comprender el servicio de agregación.
Disponibilidad
| Proposal | Status |
|---|---|
| Aggregation Service support for Amazon Web Services (AWS) across Attribution Reporting API, Private Aggregation API
Explainer |
Available |
| Aggregation Service support for Google Cloud across Attribution Reporting API, Private Aggregation API Explainer |
Available in beta |
| Aggregation Service site enrollment and mapping of a site to cloud accounts (AWS, or GCP) FAQs on GitHub |
Available |
| The Aggregation Service's epsilon value will be kept as a range of up to 64, to facilitate experimentation and feedback on different parameters.
Submit ARA epsilon feedback. Submit PAA epsilon feedback. |
Available. We will provide advanced notice to the ecosystem before the epsilon range values are updated. |
| More flexible contribution filtering for Aggregation Service queries
Explainer |
Expected Q2 2024 |
| Process for budget recovery post-disasters (errors, misconfigurations, and so on)
GitHub issue |
Available: Explainer. |
| Accenture operating as one of the Coordinators on AWS
Developer Blog |
Available |
| Independent party operating as one of the Coordinators on Google Cloud
Developer Blog |
Expected Q3 2024 |
Procesamiento de datos seguro
El servicio de agregación desencripta y combina los datos recopilados de los informes agregables, agrega ruido y muestra el informe de resumen final. Este servicio se ejecuta en un entorno de ejecución confiable (TEE), que se implementa en un servicio en la nube que admite las medidas de seguridad necesarias para proteger estos datos.
El código del TEE es el único lugar en el servicio de agregación que tiene acceso a informes sin procesar: los investigadores de seguridad, la administración de privacidad y los promotores y las tecnologías publicitarias. Para confirmar que el TEE publica la aprobación exacta y de que los datos permanezcan protegidos, un coordinador realiza la certificación.
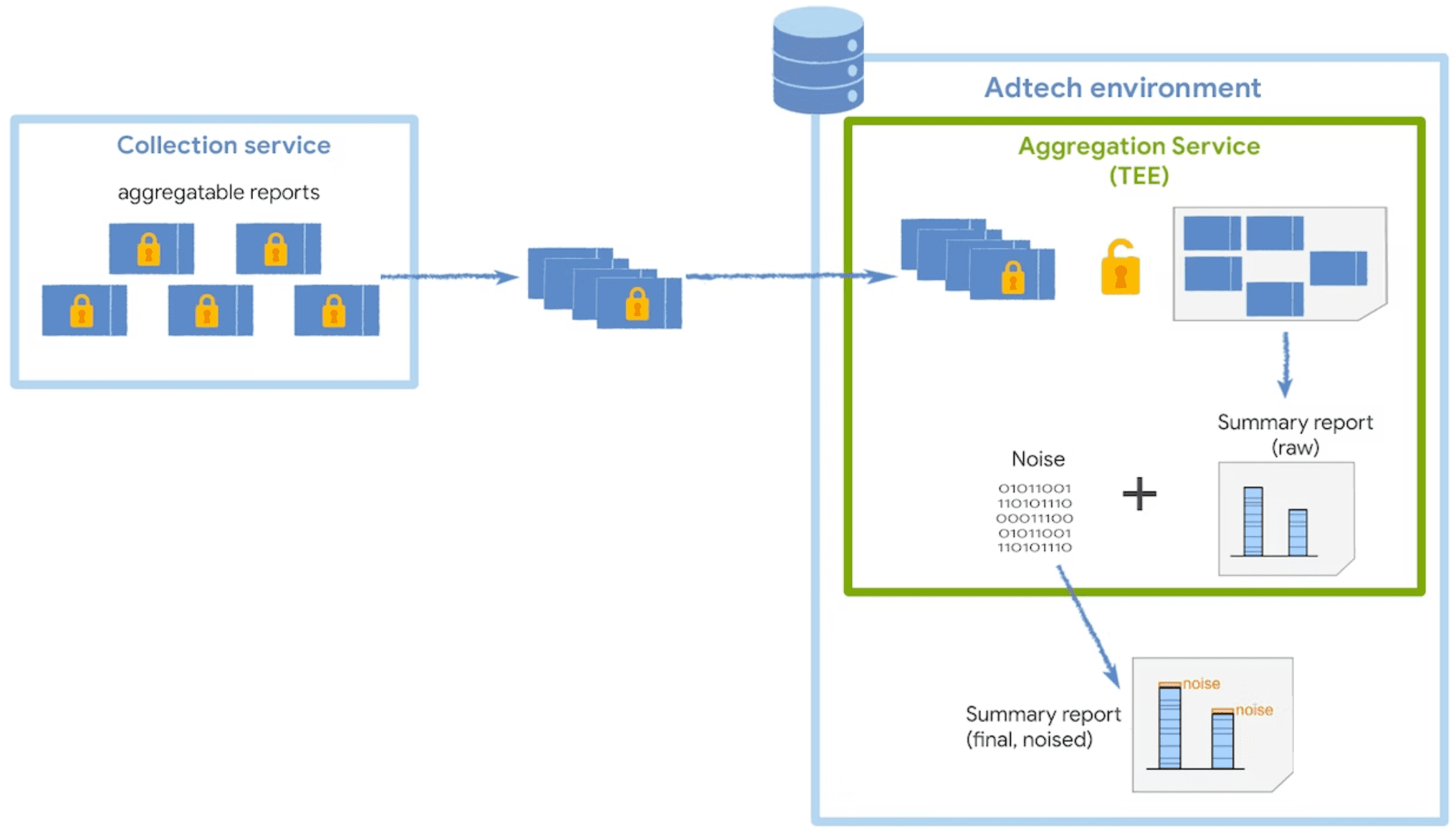
Certificación de coordinador del TEE
El coordinador es una entidad responsable de la administración de claves la contabilización de informes.
Un coordinador tiene varias responsabilidades:
- Mantener una lista de imágenes binarias autorizadas Estas imágenes son hashes criptográficos de las compilaciones de software del servicio de agregación, que Google lanzamiento. Esto se podrá reproducir para que cualquier parte pueda verificar las imágenes son idénticos a las del servicio de agregación.
- Opera un sistema de administración de claves. Las claves de encriptación son necesarias para Chrome en el dispositivo de un usuario para encriptar informes agregables. Las claves de desencriptación son necesario para demostrar que el código del servicio de agregación coincide con las imágenes binarias.
- Realiza un seguimiento de los informes agregables para evitar la reutilización en la agregación para el resumen informes, ya que la reutilización puede revelar información de identificación personal (PII).
"Sin duplicados" regla
Para obtener información sobre el contenido de un informe agregable específico, se el atacante podría hacer varias copias del informe e incluirlas en una uno o varios lotes. Por ello, el servicio de agregación aplica una "sin duplicados" regla:
- En un lote: Un informe agregable solo puede aparecer una vez dentro de un lote.
- En varios lotes: Los informes agregables no pueden aparecer en más de un lote ni contribuir a más de un informe de resumen.
Para lograrlo, el navegador asigna a cada informe agregable un ID compartido.
El navegador genera el ID compartido a partir de varios datos, incluidos los siguientes: API
versión, origen del informe, sitio de destino, hora de registro de la fuente
hora programada para el informe. Estos datos provienen del
shared_info del informe.
El servicio de agregación confirma que todos los informes agregables que tengan la misma ID compartido están en el mismo lote y se informa al coordinador que Se procesó el ID. Si se crean varios lotes con el mismo ID, solo se permite por lotes pueden aceptarse para la agregación y otros lotes se rechazan.
Cuando realices una ejecución de depuración, el mensaje "sin duplicados" no se aplica de manera forzosa en los lotes. En otras palabras, los informes de lotes anteriores pueden aparecer en una ejecución de depuración. Sin embargo, la regla es aún se aplica en un lote. Esto te permite experimentar con el servicio y varias estrategias de lote, sin limitar el procesamiento futuro en un entorno de producción.
Ruido y escalamiento
Para proteger la privacidad del usuario, el servicio de agregación aplica una mecanismo de ruido aditivo a los datos sin procesar de los informes agregables. Esto significa que una cierta cantidad de se agrega ruido estadístico a cada valor agregado antes de su lanzamiento en un de resumen.
Si bien no tienes el control directo sobre cómo se agrega el ruido, puedes influir en el impacto del ruido en los datos de medición.

El valor de ruido se obtiene de forma aleatoria desde un Distribución de probabilidad de Laplace, y la distribución es la misma, independientemente de la cantidad de datos recopilados en informes agregables. Cuantos más datos recopiles, menor será el impacto del ruido en los resultados del informe de resumen. Puedes multiplicar el informe agregable por un factor de escala para reducir el impacto del ruido.
Para entender cómo se agrega ruido, tus controles y el impacto en tu de seguridad, consulta la Presupuesto de contribución y Escalamiento vertical del presupuesto de contribución en Cómo trabajar con ruido.
Genera informes de resumen
La generación de informes de resumen depende del uso de la API. Obtén más información sobre generar informes de resumen para API de Private Aggregation y la API de Attribution Reporting.
Prueba el servicio de agregación
Recomendamos leer la guía correspondiente para cada API que pruebes:
Para probar el servicio de agregación, prueba nuestros codelabs:
También hay una herramienta de pruebas local disponible para procesar informes agregables para Attribution Reporting y la API de Private Aggregation.
El framework de prueba de carga del servicio de agregación proporciona un framework de prueba sugerido.
Interactúa y comparte tus comentarios
El servicio de agregación es una pieza clave de las APIs de medición de Privacy Sandbox. Al igual que otras APIs de Privacy Sandbox, esto se documenta y analiza de forma pública en GitHub.
- Asistencia para el servicio de agregación: Lee la explicación, plantea las preguntas, proporciona comentarios sobre la implementación y participa en el debate. Si necesitas más ayuda, comunícate con nuestro alias de asistencia.
- Asistencia para desarrolladores de Privacy Sandbox: Haga preguntas y participe en debates en el repositorio de asistencia para desarrolladores de Privacy Sandbox.