Destiné à être mis en œuvre dans le projet Android Open Source (AOSP), ce descriptif technique explique la motivation derrière la personnalisation sur l'appareil (ODP), les principes de conception qui guident son développement, sa confidentialité via le modèle de confidentialité et comment celui-ci permet de garantir une expérience privée vérifiable.
Pour ce faire, nous simplifions le modèle d'accès aux données et veillons à ce que toutes les données utilisateur qui quittent la limite de sécurité soient à confidentialité différentielle au niveau de l'utilisateur, de l'utilisateur, du modèle (parfois abrégé au niveau de l'utilisateur dans ce document).
Tout le code lié à la sortie potentielle des données des utilisateurs finaux depuis les appareils des utilisateurs finaux sera Open Source et vérifiable par des entités externes. Dès les premières étapes de notre proposition, nous cherchons à susciter l'intérêt et à recueillir des commentaires pour une plate-forme qui facilite les possibilités de personnalisation sur l'appareil. Nous invitons les personnes concernées à interagir avec nous, telles que des experts en confidentialité, des analystes de données et des spécialistes de la sécurité.
Vision
La personnalisation sur l'appareil est conçue pour protéger les informations des utilisateurs finaux contre les entreprises avec lesquelles ils n'ont pas interagi. Les entreprises peuvent continuer à personnaliser leurs produits et services pour les utilisateurs finaux (par exemple, en utilisant des modèles de machine learning correctement anonymisés et à confidentialité différentielle), mais elles ne pourront pas voir les personnalisations exactes apportées à un utilisateur final (cela dépend non seulement de la règle de personnalisation générée par le propriétaire de l'entreprise, mais également des préférences de l'utilisateur final individuel), à moins qu'il n'y ait des interactions directes entre l'entreprise et l'utilisateur final. Si une entreprise produit des modèles de machine learning ou des analyses statistiques, l'ODP s'assurera qu'ils sont correctement anonymisés à l'aide des mécanismes de confidentialité différentielle appropriés.
Notre plan actuel consiste à explorer l'ODP à plusieurs étapes clés, en couvrant les fonctionnalités suivantes. Nous invitons également les personnes intéressées à suggérer de manière constructive des fonctionnalités ou workflows supplémentaires pour approfondir cette exploration :
- Environnement de bac à sable dans lequel toute la logique métier est contenue et exécutée, ce qui permet à une multitude de signaux d'utilisateurs finaux d'entrer dans le bac à sable tout en limitant les sorties.
Data stores chiffrés de bout en bout pour :
- Commandes utilisateur et autres données liées aux utilisateurs. Ces informations peuvent être fournies par l'utilisateur final ou collectées et déduites par les entreprises, ainsi que des contrôles de la valeur TTL (Time To Live), des règles d'effacement, des règles de confidentialité, etc.
- Configurations d'entreprise. L'ODP fournit des algorithmes pour compresser ou obscurcir ces données.
- Le traitement des résultats est effectué. Voici les différents types de résultats possibles :
- Utilisés en entrée lors des cycles de traitement ultérieurs.
- Signalés par les mécanismes de confidentialité différentielle appropriés et importés sur les points de terminaison éligibles.
- Importés à l'aide du flux d'importation sécurisé dans des environnements d'exécution sécurisés (TEE, Trusted Execution Environment) exécutant des charges de travail Open Source avec des mécanismes de confidentialité différentielle centraux appropriés.
- Affichés aux utilisateurs finaux.
API conçues pour les éléments suivants :
- Mise à jour 2(a), par lot ou de manière incrémentielle.
- Mise à jour 2(b) à intervalles réguliers, par lot ou incrémentielle.
- Importation 2(c), avec des mécanismes de bruit appropriés dans les environnements d'agrégation de confiance. Ces résultats peuvent devenir 2(b) pour les cycles de traitement suivants.
Chronologie
Il s'agit du plan d'enregistrement actuel pour le test de l'ODP en version bêta. Le calendrier est susceptible d'être modifié.
| Fonctionnalité | H1 2025 | T3 2025 |
|---|---|---|
| Entraînement et inférence sur l'appareil | Contactez l'équipe Privacy Sandbox pour discuter des options de test possibles pendant cette période. | Début du déploiement sur les appareils Android T et versions ultérieures éligibles. |
Principes de conception
L'ODP cherche à équilibrer trois piliers : la confidentialité, l'impartialité et l'utilité.
Modèle de données au format tour pour une protection renforcée de la confidentialité
Il respecte la protection des données personnelles dès la conception et il est conçu pour protéger la confidentialité des utilisateurs finaux par défaut.
L'ODP explore le transfert du traitement de personnalisation sur l'appareil d'un utilisateur final. Cette approche équilibre la confidentialité et l'utilité en conservant les données sur l'appareil autant que possible et en ne les traitant en dehors de l'appareil que si nécessaire. L'ODP se concentre sur les éléments suivants :
- Contrôle des données de l'utilisateur final, même lorsqu'il quitte l'appareil. Les destinations doivent être certifiées comme des environnements d'exécution sécurisés proposés par les fournisseurs de services cloud publics exécutant du code développé par l'ODP.
- Possibilité de vérifier ce qu'il advient des données de l'utilisateur final si celui-ci quitte l'appareil. L'ODP fournit des charges de travail de calcul fédéré Open Source pour coordonner le machine learning inter-appareil et l'analyse statistique pour les utilisateurs. L'appareil d'un utilisateur final atteste que ces charges de travail sont exécutées dans des environnements d'exécution sécurisés sans modification.
- Confidentialité technique garantie (par exemple, agrégation, bruit, confidentialité différentielle) des sorties qui quittent la limite contrôlée/vérifiable par l'appareil.
Par conséquent, la personnalisation sera spécifique à chaque appareil.
De plus, les entreprises exigent également des mesures de confidentialité, que la plate-forme devrait prendre en compte. Cela implique de conserver les données d'entreprise brutes dans leurs serveurs respectifs. Pour ce faire, l'ODP adopte le modèle de données suivant :
- Chaque source de données brutes sera stockée sur l'appareil ou côté serveur, ce qui permet l'apprentissage local et l'inférence.
- Nous fournissons des algorithmes pour faciliter la prise de décision à partir de plusieurs sources de données, par exemple le filtrage entre deux emplacements de données disparates, ou l'entraînement ou l'inférence sur différentes sources.
Dans ce contexte, il peut y avoir une tour d'entreprise et une tour d'utilisateur final :
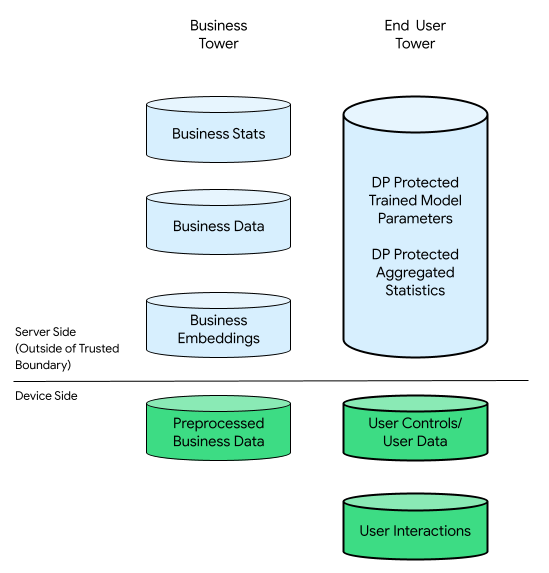
La tour de l'utilisateur final se compose de données fournies par l'utilisateur final (par exemple, ses informations de compte et de commandes), de données collectées en rapport avec ses interactions avec son appareil et de données dérivées (par exemple, centres d'intérêt et préférences) déduites par l'entreprise. Les données déduites ne remplacent pas les déclarations directes des utilisateurs.
À titre de comparaison, dans une infrastructure centrée sur le cloud, toutes les données brutes de la tour de l'utilisateur final sont transférées vers les serveurs des entreprises. À l'inverse, dans une infrastructure centrée sur l'appareil, toutes les données brutes de la tour de l'utilisateur final restent à leur origine, tandis que les données des entreprises restent stockées sur des serveurs.
La personnalisation sur l'appareil combine le meilleur des deux mondes en n'activant que du code Open Source certifié pour traiter les données susceptibles d'être liées aux utilisateurs finaux des environnements d'exécution sécurisés (TEE) à l'aide de canaux de sortie plus privés.
Engagement du public inclusif en faveur de solutions équitables
L'ODP vise à assurer un environnement équilibré pour tous les participants au sein d'un écosystème diversifié. Nous sommes conscients du caractère complexe de cet écosystème, qui se compose de différents acteurs proposant des services et des produits distincts.
Pour inspirer l'innovation, l'ODP propose des API pouvant être implémentées par les développeurs et les entreprises qu'ils représentent. La personnalisation sur l'appareil facilite l'intégration de ces implémentations tout en gérant les versions, la surveillance, les outils pour les développeurs et les outils de commentaires. La personnalisation sur l'appareil ne crée aucune logique métier concrète mais sert plutôt de catalyseur pour la créativité.
L'ODP pourrait offrir plus d'algorithmes au fil du temps. La collaboration avec l'écosystème est essentielle afin de déterminer le bon niveau de fonctionnalités et éventuellement d'établir un plafond raisonnable en termes de ressources d'appareils pour chaque entreprise participante. Nous attendons les commentaires de l'écosystème pour nous aider à identifier et à hiérarchiser les nouveaux cas d'utilisation.
Un utilitaire de développement pour une meilleure expérience utilisateur
Avec l'ODP, il n'y a aucune perte de données d'événements ni de délais d'observation, car tous les événements sont enregistrés localement au niveau de l'appareil. Il n'y a aucune erreur de connexion, et tous les événements sont associés à un appareil spécifique. Par conséquent, tous les événements observés forment naturellement une séquence chronologique reflétant les interactions de l'utilisateur.
Ce processus simplifié élimine le besoin de joindre ou de réorganiser les données, ce qui permet une accessibilité en temps quasi réel et sans perte des données utilisateur. Réciproquement, cela peut améliorer l'utilité que les utilisateurs finaux perçoivent lorsqu'ils interagissent avec des produits et services basés sur les données, ce qui peut conduire à des niveaux de satisfaction plus élevés et à des expériences plus significatives. L'ODP permet aux entreprises de s'adapter efficacement aux besoins de leurs utilisateurs.
Le modèle de confidentialité : la confidentialité par le biais de la confidentialité
Les sections suivantes traitent du modèle consommateur-producteur comme base de cette analyse de la confidentialité, et présentent la confidentialité de l'environnement de calcul par rapport à la précision des résultats.
Le modèle consommateur-producteur est la base de cette analyse de la confidentialité
Nous utiliserons le modèle consommateur-producteur pour examiner les garanties de confidentialité par le biais de la confidentialité. Dans ce modèle, les calculs sont représentés par des nœuds au sein d'un graphe orienté acyclique (DAG) composé de nœuds et de sous-graphiques. Chaque nœud de calcul comporte trois composants : les entrées consommées, les sorties produites et le calcul mappant les entrées aux sorties.

Dans ce modèle, la protection de la confidentialité s'applique à l'ensemble des trois composants :
- Confidentialité de la saisie. Les nœuds peuvent disposer de deux types d'entrées. Si une entrée est générée par un nœud prédécesseur, elle dispose déjà des garanties de confidentialité de la sortie de ce nœud. Sinon, les entrées doivent effacer les règles d'entrée de données à l'aide du moteur de règles.
- Confidentialité des résultats. Il peut être nécessaire de rendre privée la sortie, comme celle fournie par la confidentialité différentielle (DP).
- Confidentialité de l'environnement de calcul. Le calcul doit avoir lieu dans un environnement fermé de manière sécurisée, garantissant que personne n'a accès aux états intermédiaires au sein d'un nœud. Les technologies qui permettent ce fonctionnement incluent les calculs fédérés (FC), les environnements d'exécution sécurisés (TEE) basés sur le matériel, le calcul multipartite sécurisé (sMPC), le chiffrement homomorphe (HPE), etc. Il convient de noter que la protection de la vie privée via la confidentialité protège les états intermédiaires et que toutes les sorties quittant la limite de confidentialité doivent toujours être protégées par des mécanismes de confidentialité différentielle. Voici deux revendications obligatoires :
- Confidentialité des environnements, en s'assurant que seuls les résultats déclarés quittent l'environnement.
- La régularité, qui permet de déduire de manière précise les réclamations pour atteinte à la vie privée des données de sortie à partir des réclamations pour atteinte à la vie privée des entrées. L'intégrité permet de propager la propriété de confidentialité dans un graphe orienté acyclique (DAG).
Un système privé assure la confidentialité des entrées, de l'environnement de calcul et des résultats. Cependant, le nombre d'applications des mécanismes de confidentialité différentielle peut être réduit en fermant davantage de traitements dans un environnement de calcul confidentiel.
Ce modèle présente deux avantages principaux. Tout d'abord, la plupart des systèmes, petits ou grands, peuvent être représentés sous forme de DAG. Deuxièmement, les propriétés de post-traitement [Section 2.1] et de composition Lemme 2.4 dans "The Complexity of Differential Privacy" de la confidentialité différentielle prêtent des outils puissants pour analyser le compromis (dans le pire des cas) en termes de confidentialité et de précision pour un graphique entier :
- Le post-traitement garantit que lorsqu'une quantité est privatisée, elle ne peut pas être "déprivatisée" si les données d'origine ne sont pas utilisées à nouveau. Tant que toutes les entrées d'un nœud sont privées, sa sortie l'est également, quels que soient ses calculs.
- La composition avancée garantit que si chaque partie du graphique est une confidentialité différentielle (DP), le graphique global délimite également de manière effective le ε et le δ du résultat final d'un graphique d'environ ε√κ, respectivement, en supposant qu'un graphique comporte κ unités et que la sortie de chaque unité soit égale à (ε, δ)-DP.
Ces deux propriétés se traduisent en deux principes de conception pour chaque nœud :
- Propriété 1 (du post-traitement) si les entrées d'un nœud sont toutes des confidentialités différentielles (DP), sa sortie est une DP, acceptant n'importe quelle logique métier exécutée dans le nœud et la prise en charge des "sauces secrètes" des entreprises.
- Propriété 2 (à partir de la composition avancée) si les entrées d'un nœud ne sont pas toutes des DP, sa sortie doit être rendue conforme à la confidentialité différentielle. Si un nœud de calcul est un nœud qui s'exécute dans des environnements d'exécution sécurisés et exécute des charges de travail et des configurations Open Source basées sur la personnalisation sur l'appareil, des limites de DP plus strictes sont possibles. Sinon, la personnalisation sur l'appareil devra peut-être utiliser les limites de DP dans le pire des cas. En raison de contraintes de ressources, les environnements d'exécution sécurisés proposés par un fournisseur de services cloud publics seront initialement prioritaires.
Confidentialité de l'environnement de calcul par rapport à la précision de la sortie
Par la suite, la personnalisation sur l'appareil visera à améliorer la sécurité des environnements de calcul confidentiels et à s'assurer que les états intermédiaires restent inaccessibles. Ce processus de sécurité, appelé fermeture, sera appliqué au niveau du sous-graphique, ce qui permettra à plusieurs nœuds d'être simultanément conformes à la confidentialité différentielle. Cela signifie que la propriété 1 et la propriété 2 mentionnées précédemment s'appliquent au niveau du sous-graphique.

Bien sûr, la sortie du graphique final, la sortie 7 est conforme à la confidentialité différentielle. Cela signifie qu'il y aura 2 DP en tout pour ce graphique ; contre 3 DP total (local) si aucun scellement n'a été utilisé.
En bref, en sécurisant l'environnement de calcul et en éliminant la possibilité pour les attaquants d'accéder aux entrées et aux états intermédiaires d'un graphe ou d'un sous-graphique, cela permet d'implémenter la DP centrale (c'est-à-dire que la sortie d'un environnement fermé est conforme à la DP), ce qui peut améliorer la justesse par rapport à la DP locale (c'est-à-dire que les entrées individuelles sont conformes à la DP). Ce principe sous-tend l'utilisation des FC, des TEE, des sMPC et des HPE comme des technologies de confidentialité. Reportez-vous au chapitre 10 de l'article The Complexity of Differential Privacy.
L'entraînement de modèle et l'inférence constituent un bon exemple pratique. Les discussions ci-dessous supposent que (1) la population d'entraînement et la population d'inférence se chevauchent, et (2) que les caractéristiques et les étiquettes constituent des données utilisateur privées. Nous pouvons appliquer la DP à toutes les entrées :

La personnalisation sur l'appareil peut appliquer la DP locale aux étiquettes et aux fonctionnalités des utilisateurs avant de les envoyer aux serveurs. Cette approche n'impose aucune exigence concernant l'environnement d'exécution du serveur ni sa logique métier.



Il s'agit de la conception actuelle de la personnalisation sur l'appareil.
Confidentialité vérifiable
La personnalisation sur l'appareil vise à assurer la confidentialité vérifiable. L'accent est mis sur la vérification de ce qui se passe hors des appareils des utilisateurs. L'ODP créera le code qui traite les données quittant les appareils des utilisateurs finaux. Il utilisera l'architecture RATS (Remote ATtestation Procédures) RFC 9334 du NIST pour attester que ce code est en cours d'exécution non modifié sur un serveur sans privilèges pour l'administrateur d'instance conforme au Confidential Computing Consortium. Ces codes seront Open Source et accessibles pour une vérification transparente afin d'établir une relation de confiance. De telles mesures peuvent garantir aux individus que leurs données sont protégées et que les entreprises peuvent établir une réputation en s'appuyant sur une base solide de protection de la confidentialité.
La réduction de la quantité de données privées collectées et stockées est un autre aspect essentiel de la personnalisation sur l'appareil. Il adhère à ce principe en adoptant des technologies telles que le calcul fédéré et la confidentialité différentielle, permettant ainsi la révélation de modèles de données intéressants sans exposer de détails individuels sensibles ou d'informations identifiables.
La maintenance d'une piste d'audit qui enregistre les activités liées au traitement et au partage des données est un autre aspect clé de la confidentialité vérifiable. Cela permet de créer des rapports d'audit et d'identifier les failles, mettant ainsi en évidence nos engagements en matière de confidentialité.
Nous sollicitons une collaboration constructive de la part d'experts en confidentialité, d'institutions, d'autorités du secteur et d'individus pour nous aider à améliorer en permanence la conception et les implémentations.
Le graphique ci-dessous montre le chemin de code pour l'agrégation inter-appareil et le bruit par confidentialité différentielle.
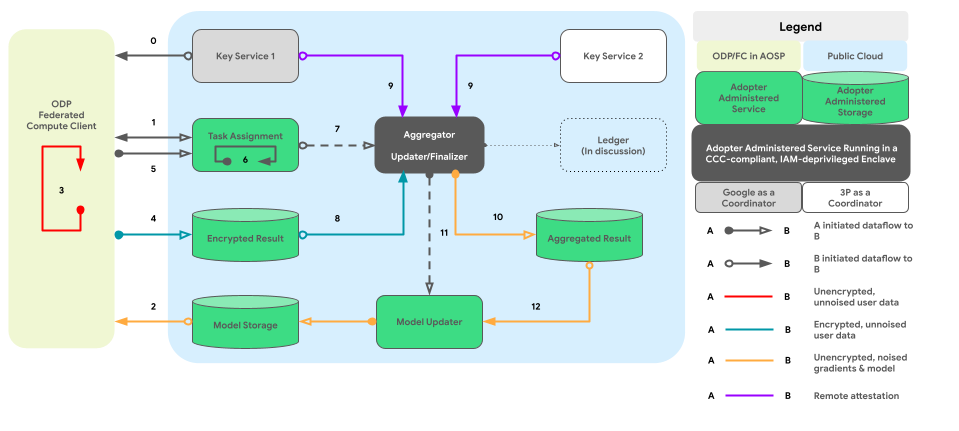
Conception de haut niveau
Comment mettre en œuvre la protection de la vie privée par le biais de la confidentialité ? De manière générale, un moteur de règles créé par l'ODP qui s'exécute dans un environnement fermé sert de composant principal supervisant chaque nœud/sous-graphique tout en suivant l'état de DP de leurs entrées et sorties :
- Du point de vue du moteur de règles, les appareils et les serveurs sont traités de la même manière. Les appareils et les serveurs exécutant le même moteur de règles sont considérés comme identiques d'un point de vue logique, une fois que leurs moteurs de règles ont été mutuellement certifiés.
- Sur les appareils, l'isolation s'effectue via des processus isolés AOSP (ou pKVM à long terme, une fois la disponibilité élevée). Sur les serveurs, l'isolation repose sur une "partie de confiance" qui est soit un TEE, ainsi que d'autres solutions de fermeture technique de préférence, un accord contractuel, ou les deux.
En d'autres termes, tous les environnements fermés qui installent et exécutent le moteur de règles de plate-forme sont considérés comme faisant partie de notre Trusted Computing Base (TCB). Les données peuvent se propager sans bruit supplémentaire avec le TCB. La DP doit être appliquée lorsque les données quittent le TCB.
La conception de haut niveau de la personnalisation sur l'appareil intègre efficacement deux éléments essentiels :
- Architecture de processus associé pour l'exécution de la logique métier
- Des règles ainsi qu'un moteur de règles permettant de gérer l'entrée et la sortie des données, ainsi que les opérations autorisées.
Cette conception cohérente permet aux entreprises d'exécuter leur code propriétaire dans un environnement d'exécution sécurisé et d'accéder aux données utilisateur qui ont fait l'objet de vérifications appropriées au niveau des règles.
Les sections suivantes développeront ces deux aspects clés.
Architecture de processus associé pour l'exécution de la logique métier
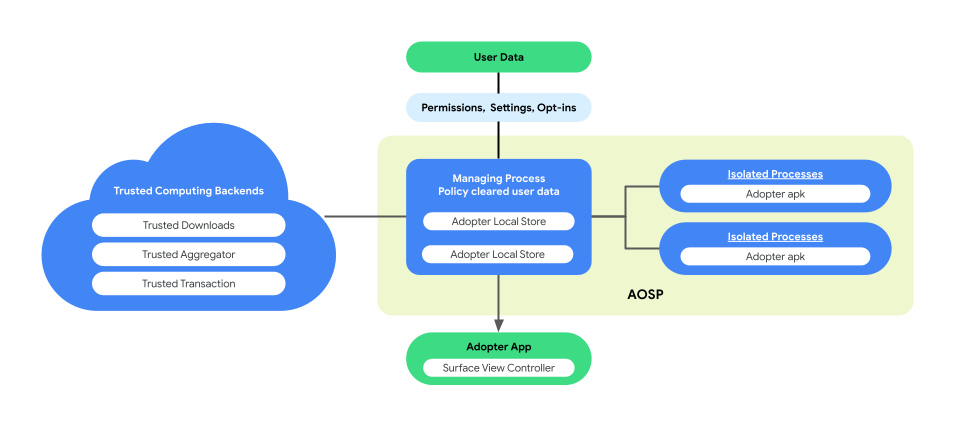
La personnalisation sur l'appareil introduit une architecture couplée dans AOSP pour améliorer la confidentialité des utilisateurs et la sécurité des données lors de l'exécution de la logique métier. Cette architecture comprend les éléments suivants :
ManagingProcess. Ce processus crée et gère des IsolatedProcesses, en veillant à ce qu'ils restent isolés au niveau du processus avec un accès limité aux API de la liste d'autorisation et sans autorisation réseau ou disque. ManagingProcess gère la collecte de toutes les données d'entreprise, de toutes les données d'utilisateurs finaux et des règles les efface pour le code d'entreprise, en les transférant dans IsolatedProcesses pour exécution. En outre, il arbitre l'interaction entre IsolatedProcesses et d'autres processus, tels que system_server.
IsolatedProcess. Considéré comme isolé (
isolatedprocess=truedans le fichier manifeste), ce processus reçoit les données d'entreprise, les données des utilisateurs finaux validées par le règlement et le code d'entreprise de ManagingProcess. Cela permet au code d'entreprise de fonctionner sur ses données et sur les données des utilisateurs finaux validées par le règlement. IsolatedProcess communique exclusivement avec ManagingProcess pour l'entrée et la sortie, sans autorisation supplémentaire.
L'architecture de processus associé permet une vérification indépendante des règles de confidentialité des données des utilisateurs finaux, sans que les entreprises aient besoin de partager leur logique métier ou leur code en Open Source. Étant donné que ManagingProcess maintient l'indépendance d'IsolatedProcesses et qu'IsolatedProcesses exécute efficacement la logique métier, cette architecture garantit une solution plus sécurisée et efficace pour préserver la confidentialité des utilisateurs lors de la personnalisation.
La figure suivante illustre cette architecture de processus associé.
Règles et moteurs de règles pour les opérations de données
La personnalisation sur l'appareil introduit une couche d'application des règles entre la plate-forme et la logique métier. L'objectif est de fournir un ensemble d'outils permettant de mapper les contrôles de l'utilisateur final et de l'entreprise dans des décisions stratégiques centralisées et exploitables. Ces règles sont ensuite appliquées de manière exhaustive et fiable à l'ensemble des flux et des entreprises.
Dans l'architecture à processus couplé, le moteur de règles se trouve dans le processus de gestion de processus, supervisant l'entrée et la sortie des données d'utilisateurs finaux et d'entreprises. Elle fournira également les opérations de la liste d'autorisation à IsolatedProcess. Exemples de domaines d'application : respect des commandes pour les utilisateurs finaux, protection de l'enfance, prévention du partage de données sans consentement et confidentialité des entreprises.
Cette architecture d'application des règles comprend trois types de workflows exploitables :
- Workflows hors connexion lancés localement avec des communications d'environnements d'exécution sécurisés (TEE) :
- Flux de téléchargement de données : téléchargements fiables
- Flux d'importation de données : transactions fiables
- Workflows en ligne lancés localement :
- Flux de mise en service en temps réel
- Flux d'inférence
- Workflows hors connexion initiés localement :
- Flux d'optimisation : entraînement de modèle sur l'appareil implémenté via l'apprentissage fédéré (FL)
- Flux de rapports : agrégation multi-appareil implémentée via Federated Analytics (FA)
La figure suivante illustre l'architecture du point de vue des règles et des moteurs de règles.
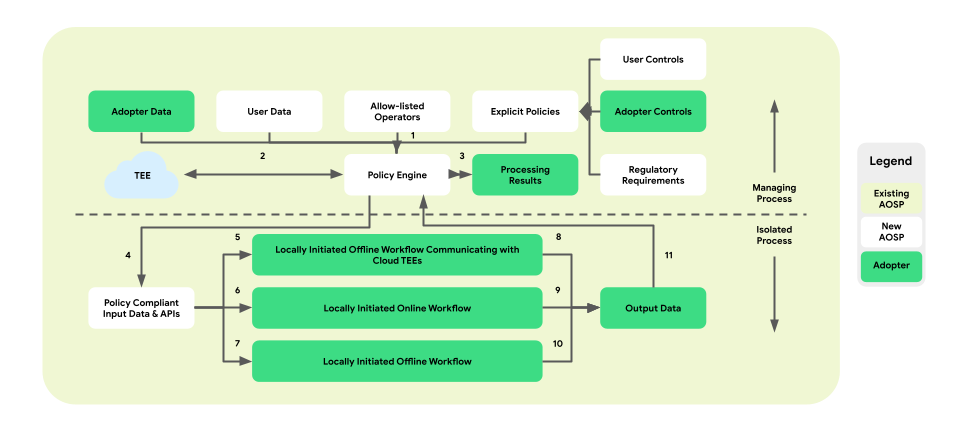
- Téléchargement : 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Inférence: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Optimisation : 2 (fournit un plan d'entraînement) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Rapports : 3 (fournit un plan d'agrégation) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
Dans l'ensemble, l'introduction de la couche d'application des règles et du moteur de règles dans l'architecture couplée de processus de personnalisation sur l'appareil garantit un environnement isolé et protégeant la confidentialité permettant d'exécuter la logique métier, tout en fournissant un accès contrôlé aux données nécessaires et aux opérations.
Surfaces d'API multicouches
La personnalisation sur l'appareil fournit une architecture d'API en couches pour les entreprises intéressées. La couche supérieure est constituée d'applications conçues pour des cas d'utilisation spécifiques. Les entreprises potentielles peuvent connecter leurs données à ces applications, appelées API de couche supérieure. Les API de couche supérieure reposent sur les API de couche moyenne.
Nous prévoyons d'ajouter d'autres API de couche supérieure au fil du temps. Lorsqu'une API de couche supérieure n'est pas disponible pour un cas d'utilisation particulier ou que les API de couche supérieure existantes ne sont pas suffisamment flexibles, les entreprises peuvent implémenter directement les API de couche moyenne, qui fournissent une flexibilité et une alimentation électrique grâce aux primitives de programmation.
Conclusion
La personnalisation sur l'appareil est une proposition de recherche en phase de démarrage visant à solliciter l'intérêt et les commentaires d'une solution à long terme qui répond aux préoccupations des utilisateurs finaux en termes de confidentialité grâce aux technologies les plus récentes et les plus performantes, censées apporter un haut niveau d'utilité.
Nous souhaitons collaborer avec les personnes concernées, telles que les experts en confidentialité, les analystes de données et les utilisateurs finaux potentiels, afin de nous assurer que l'ODP répond à leurs besoins et répond à leurs préoccupations.