この技術解説ドキュメントでは、Android オープンソース プロジェクト(AOSP)での実装が予定されている On-Device Personalization(ODP)の背後にある動機、その開発の指針となる設計原則、機密性保持モデルによるプライバシー、検証可能なプライバシー体験の確保に役立つ方法について説明します。
Google は、データアクセス モデルを簡素化し、セキュリティ境界から出るすべてのユーザーデータを(ユーザー、導入者、model_instance)レベル(このドキュメントではユーザーレベルに短縮されることがあります)で差分プライベートにすることで、これを実現する予定です。
エンドユーザーのデバイスから送信される可能性のあるエンドユーザー データに関連するコードはすべてオープンソースであり、外部エンティティによって検証できます。提案の初期段階では、On-Device Personalization の最適化を促進できるように、プラットフォームに対する関心を高め、フィードバックを収集することを目指しています。Google では、プライバシーの専門家、データ アナリスト、セキュリティ担当者などの関係者からのご協力を期待しています。
ビジョン
On-Device Personalization は、エンドユーザーがやり取りしたことのないビジネスからエンドユーザーの情報を保護するように設計されています。企業は、エンドユーザー向けに商品やサービスをカスタマイズし続けることができます(たとえば、適切に匿名化され差分プライベート化した機械学習モデルを使用するなど)。しかし、企業とエンドユーザーが直接やり取りしない限り、エンドユーザー向けに行われた正確なカスタマイズ(ビジネス オーナーによって生成されたカスタマイズ ルールだけでなく、個々のエンドユーザーの好みにも依存)を確認することはできません。企業が機械学習モデルや統計分析を作成する場合、ODP は、適切な差分プライバシー メカニズムを使用して、それらが適切に匿名化されるようにします。
現在の計画では、次の特長と機能をカバーする複数のマイルストーンで ODP を検討しています。この取り組みをさらに進めるために、関心をお持ちの方からの、追加の機能やワークフローに関する建設的なご提案も歓迎いたします。
- すべてのビジネス ロジックが含まれており、それが実行されるサンドボックス環境。サンドボックスへの多数のエンドユーザー シグナル入力を許可する一方で、出力は制限されています。
下記のデータ用のエンドツーエンドで暗号化されたデータストア:
- ユーザー コントロール、その他のユーザー関連データ。これは、エンドユーザーが提供するものもあれば、企業が収集して推論するものもあります。有効期間(TTL)制御、消去ポリシー、プライバシー ポリシーなども含まれます。
- ビジネス設定。ODP には、これらのデータを圧縮または難読化するアルゴリズムが用意されています。
- ビジネス処理の結果。結果は次のようになります。
- 以降の処理ラウンドで入力として消費される。
- 適切な差分プライバシー メカニズムによりノイズが追加され、対象となるエンドポイントにアップロードされる。
- 適切なセントラル差分プライバシー メカニズムを備えたオープンソース ワークロードを実行する高信頼実行環境(TEE)に、信頼できるアップロード フローを使用してアップロードされる。
- エンドユーザーに表示される。
次の目的で設計された API:
- 2(a)をバッチまたは増分方式で更新する。
- 2(b)を定期的に(バッチまたは増分方式で)更新する。
- 信頼できる集計環境で適切なノイズ追加メカニズムを使用して、2(c)をアップロードする。このような結果は、次の処理ラウンドでは 2(b)になる可能性があります。
タイムライン
以下は、ODP のベータ版テストに関する現在の計画です。タイムラインは変更される可能性があります。
| 機能 | 2025 年上半期 | 2025 年第 3 四半期 |
|---|---|---|
| オンデバイス トレーニング + 推論 | この期間に試験運用できるオプションについて、プライバシー サンドボックス チームにお問い合わせください。 | 対象の Android T 以降のデバイスへのリリースを開始します。 |
設計の原則
ODP は、プライバシー、公平性、有用性の 3 つの柱のバランスを追求します。
タワー型のデータモデルでプライバシー保護を強化
ODP はプライバシー バイ デザインに準拠し、エンドユーザーのプライバシーを最初から保護するように設計されています。
ODP では、パーソナライズ処理をエンドユーザーのデバイスに移すことを検討します。このアプローチでは、データを可能な限りデバイスに保持し、必要な場合にのみデバイスの外部で処理することで、プライバシーと有用性のバランスを取ります。ODP は以下に焦点を当てています。
- エンドユーザー データのデバイス コントロール(デバイスから外部に送信される場合でも)。宛先は、ODP で作成されたコードを実行するパブリック クラウド プロバイダが提供する高信頼実行環境であることが証明されている必要があります。
- エンドユーザー データがデバイスから離れた場合にどうなるかのデバイス検証可能性。ODP は、オープンソースの連携コンピューティング ワークロードを提供し、クロスデバイス機械学習と統計分析を連携させます。エンドユーザーのデバイスは、そのようなワークロードが変更されずに高信頼実行環境で実行されることを証明します。
- デバイスの制御下にある / 検証可能な境界を離れる出力の技術的なプライバシー保証(集計、ノイズ、差分プライバシーなど)。
したがって、パーソナライズはデバイス固有になります。
さらに、企業はプライバシー保護対策も必要としており、プラットフォームはこれに対処する必要があります。そのためには、それぞれのサーバーでビジネスの元データを維持する必要があります。これを実現するために、ODP では次のデータモデルを採用しています。
- 各元データソースはデバイスまたはサーバー側に保存され、ローカルでの学習と推論が可能になります。
- Google は、2 つの異なるデータ ロケーション間のフィルタリングや、さまざまなソースにわたるトレーニングや推論など、複数のデータソースにわたる意思決定を容易にするアルゴリズムを提供します。
ここでは、ビジネスタワーとエンドユーザー タワーがあります。
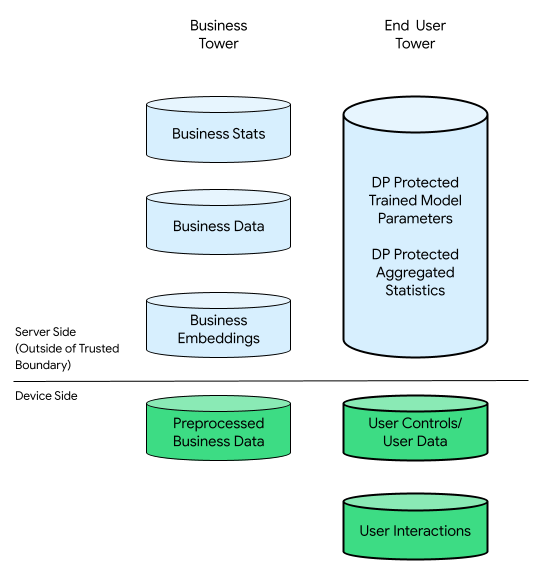
エンドユーザー タワーには、エンドユーザーから提供されたデータ(アカウント情報やコントロールなど)、エンドユーザーによるデバイスの操作に関連する収集データ、企業によって推論される派生データ(関心や好みなど)が含まれます。推論データによってユーザーの直接宣言が上書きされることはありません。
比較として、クラウド中心のインフラストラクチャでは、エンドユーザー タワーからのすべての元データが企業のサーバーに転送されます。逆に、デバイス中心のインフラストラクチャでは、エンドユーザー タワーからのすべての元データは元の場所に残り、ビジネスデータはサーバーの保存場所に残ります。
On-Device Personalization は、証明済みのオープンソース コードのみが、よりプライベートな出力チャネルを使用して TEE のエンドユーザーに関連する可能性があるデータを処理できるようにすることで、両方の長所を兼ね備えています。
公平なソリューションに向けたインクルーシブな一般エンゲージメント
ODP は、多様性のあるエコシステム内のすべての参加者にとってバランスの取れた環境を確保することを目的としています。Google は、このエコシステムの複雑さを認識しています。このエコシステムは、それぞれ異なるサービスや商品を提供するさまざまなプレーヤーで構成されています。
イノベーションを促進するために、ODP は、デベロッパーとその企業が実装できる API を提供しています。On-Device Personalization により、リリース、モニタリング、デベロッパー ツール、フィードバック ツールを管理しながら、これらの実装をシームレスに統合できます。On-Device Personalization では、具体的なビジネス ロジックは作成されませんが、その代わりにクリエイティビティを促進します。
ODP では、今後、より多くのアルゴリズムを提供していきます。適切な機能レベルを決定し、参加する企業ごとに妥当なデバイス リソースの上限を設定するためには、エコシステムとの協力が不可欠です。新しいユースケースの認識と優先順位付けのために、エコシステムからのフィードバックをお待ちしています。
ユーザー エクスペリエンスを向上させるデベロッパー ユーティリティ
ODP では、すべてのイベントがデバイスレベルでローカルに記録されるため、イベントデータの損失やモニタリングの遅延は発生しません。結合エラーはなく、すべてのイベントが特定のデバイスに関連付けられています。その結果、モニタリングされたすべてのイベントは、ユーザーの操作を反映した時系列のシーケンスを自然に形成します。
この簡素化されたプロセスにより、データの結合や再配置が不要になり、ほぼリアルタイムで、無損失なユーザー データアクセスを行えます。これにより、エンドユーザーがデータドリブンのプロダクトやサービスを利用しているときに認識する有用性が向上し、満足度が向上し、より有意義なエクスペリエンスにつながる可能性があります。ODP を使用すると、企業はユーザーのニーズに効果的に適応できます。
プライバシー モデル: 機密性保持によるプライバシー
以降のセクションでは、このプライバシー分析のベースとしてのコンシューマー / プロデューサー モデルと、計算環境のプライバシーと出力の精度について説明します。
このプライバシー分析のベースとなるコンシューマー / プロデューサー モデル
ここでは、コンシューマー / プロデューサー モデルを使用して、機密性保持によるプライバシーの保証について検証します。このモデルの計算は、ノードとサブグラフで構成される有向非巡回グラフ(DAG)内のノードとして表されます。各計算ノードには、消費される入力、生成される出力、入力から出力への計算マッピングという 3 つのコンポーネントがあります。

このモデルでは、プライバシー保護は次の 3 つの要素すべてに適用されます。
- 入力のプライバシー。ノードには 2 種類の入力があります。入力が先行ノードによって生成される場合、その先行ノードの出力プライバシー保証がすでに入力に設定されています。それ以外の場合は、ポリシー エンジンを使用して入力データの内向きポリシーをクリアする必要があります。
- 出力のプライバシー。出力は、差分プライバシー(DP)などの手法により、非公開化する必要がある場合があります。
- 計算環境の機密性保持。計算は、ノード内の中間状態にアクセスできないように、安全にシーリングした環境で実行する必要があります。これを可能にするテクノロジーには、連携コンピューティング(FC)、ハードウェア ベースの高信頼実行環境(TEE)、秘匿マルチパーティ計算(sMPC)、準同型暗号化(HPE)などがあります。機密性保持によるプライバシー保護対策がされている中間状態および機密性境界外に出るすべての出力は、引き続き差分プライバシー メカニズムによって保護される必要があることに注意してください。次の 2 つのクレームが必要です。
- 環境の機密性保持。宣言された出力のみが環境から外部に出ることを保証します。
- 健全性。入力プライバシーのクレームから出力プライバシーのクレームを正確に推論できるようにします。健全性により、プライバシー プロパティを DAG に伝播できます。
非公開システムでは、入力プライバシー、計算環境の機密性、出力プライバシーが維持されます。ただし、機密計算環境内にシーリングしてより多くの処理を扱うことで、差分プライバシー メカニズムの適用数を減らすことができます。
このモデルには、主に 2 つの利点があります。1 つ目は、大小のほとんどのシステムを DAG として表せることです。次に、DP の 後処理 [セクション 2.1] と構成 Lemma 2.4 in the Complexity of Differential Privacy は、グラフ全体のプライバシーと精度のトレードオフ(最悪の場合)を分析するための強力なツールとなります。
- 後処理により、一度ある量が非公開化されると、元データが再び使用されない限り「非公開を解除」できないことが保証されます。ノードのすべての入力が非公開である限り、その計算に関係なく、出力は非公開になります。
- 高度な合成では、グラフの各部分が DP の場合、グラフ全体も同様に DP であることを保証します。グラフが κ 個のユニットを持ち、各ユニットの出力が (ε, δ)-DP であると仮定すると、グラフの最終出力の ε と δ をそれぞれ約 ε√κ で効果的に束縛します。
これらの 2 つのプロパティは、各ノードに対する次の 2 つの設計原則に変換できます。
- プロパティ 1(後処理から): ノードの入力がすべて DP の場合、その出力は DP になり、ノードで実行される任意のビジネス ロジックに対応し、ビジネスの「シークレット ソース」をサポートします。
- プロパティ 2(高度な合成から): ノードの入力がすべて DP とは限らない場合、その出力を DP に準拠させる必要があります。計算ノードが高信頼実行環境上で実行され、オープンソースの On-Device Personalization によって提供されるワークロードと構成を実行している場合は、より厳しい DP 境界を設定できます。それ以外の場合、On-Device Personalization では、最悪のケースの DP 境界を使用する必要があります。リソースの制約により、パブリック クラウド プロバイダが提供する高信頼実行環境が最初に優先されます。
計算環境のプライバシーと出力の精度
今後、On-Device Personalization では、機密計算環境のセキュリティを強化し、中間状態にアクセスできないようにすることに重点を置きます。シーリングと呼ばれるこのセキュリティ プロセスはサブグラフ レベルで適用され、複数のノードをまとめて DP に準拠させることができます。つまり、前述のプロパティ 1 とプロパティ 2 はサブグラフ レベルで適用されます。

もちろん、最終的なグラフ出力である Output 7 は、合成によって DP されています。つまり、このグラフの DP は合計で 2 つになります。シーリングを使用しない場合は合計(ローカル)DP は 3 になります。
基本的に、計算環境を保護し、攻撃者がグラフまたはサブグラフの入力と中間状態にアクセスする機会を排除することで、中央 DP(シーリングされた環境の出力が DP に準拠)を実装できます。これにより、ローカル DP(個々の入力が DP に準拠)と比較して精度を向上させることができます。この原則は、プライバシー技術として FC、TEE、sMPC、HPE を検討するベースとなります。『The Complexity of Differential Privacy』の第 10 章をご覧ください。
実用的な良い例は、モデルのトレーニングと推論です。以下の説明では、(1)トレーニング母集団と推論母集団が重複し、(2)機能とラベルの両方が非公開のユーザーデータを構成することを前提としています。DP はすべての入力に適用できます。

On-Device Personalization では、サーバーに送信する前にローカル DP をユーザーラベルと機能に適用できます。このアプローチでは、サーバーの実行環境やビジネス ロジックに対する要件はありません。



これは現在の On-Device Personalization の設計です。
検証可能なプライバシー
On-Device Personalization は、検証可能なプライバシーを実現することを目的としています。ユーザーのデバイス外に出ると何が起こるかを検証することに重点を置いています。ODP は、エンドユーザーのデバイスから送信されるデータを処理するコードを作成し、NIST の RFC 9334 リモート認証手続き(RATS)アーキテクチャを使用して、そのようなコードが Confidential Computing Consortium 準拠のインスタンス管理者特権のないサーバーで変更されていないことを認証します。これらのコードはオープンソースとして利用でき、透明性の高い検証により信頼を構築できます。このような対策により、個人は自分のデータが保護されているという確信を得ることができ、企業はプライバシー保証の強固な基盤に基づいて評判を確立できます。
収集、保存される個人データの量を減らすことも、On-Device Personalization の重要な側面です。連携コンピューティングや差分プライバシーなどのテクノロジーを採用することで、この原則を遵守し、個人の機密情報や個人を特定できる情報を公開することなく、貴重なデータパターンを発見できます。
データ処理と共有に関連するアクティビティを記録する監査証跡を維持することは、検証可能なプライバシーのもう一つの重要な側面です。これにより、監査レポートの作成と脆弱性の特定が可能になり、プライバシーに対する Google の取り組みを如実に示します。
設計と実装の継続的な改善のため、プライバシーの専門家、機関、業界、個人に建設的なコラボレーションをお願いしています。
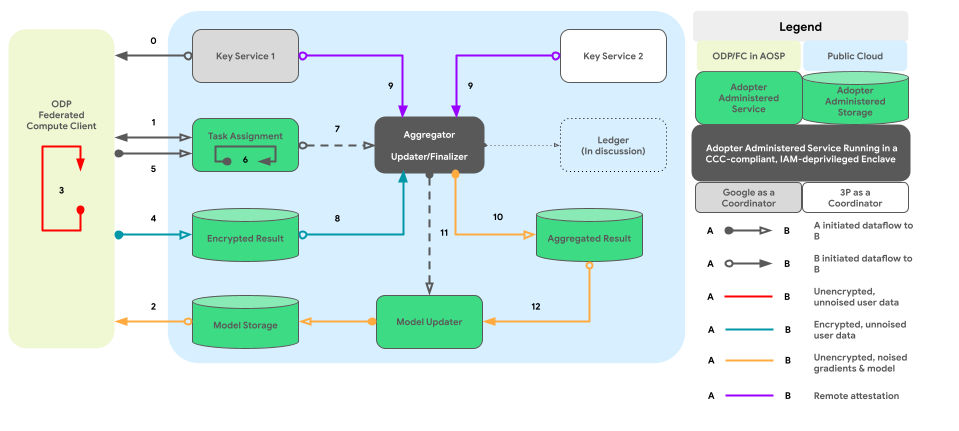
下のグラフは、差分プライバシーに従ったクロスデバイス集計とノイズ追加のコードパスを示しています。
設計の概要
機密性保持によるプライバシーを実装するにはどうすればよいでしょうか。大まかに言うと、シーリングした環境で実行される ODP によって作成されたポリシー エンジンは、各ノード / サブグラフを監視すると同時にその入力と出力の DP ステータスを追跡するコア コンポーネントとして機能します。
- ポリシー エンジンの観点においては、デバイスとサーバーは同じように扱われます。同じポリシー エンジンを実行しているデバイスとサーバーは、ポリシー エンジンが相互に認証されると、論理的に同一とみなされます。
- デバイスでは、AOSP の分離プロセス(または長期的には可用性が高くなった後は pKVM)によって分離が行われます。サーバーでは、分離は「信頼できる当事者」に依存します。信頼できる当事者とは、TEE にその他の技術的シーリング ソリューションを追加したもの(こちらを推奨します)、または契約上の合意のいずれか、あるいはその両方です。
つまり、プラットフォーム ポリシー エンジンをインストールして実行するシーリングされた環境はすべて、トラステッド コンピューティング ベース(TCB)の一部とみなされます。TCB では、ノイズ追加なしでデータを伝播できます。DP は、データが TCB から出るときに適用する必要があります。
On-Device Personalization の大まかな設計には、次の 2 つの重要な要素が効果的に統合されています。
- ビジネス ロジック実行用のペアのプロセス アーキテクチャ
- データの出入り、および許可されたオペレーションを管理するためのポリシーとポリシー エンジン。
この一貫した設計により、企業は、高信頼実行環境で独自のコードを実行し、適切なポリシー チェックをクリアしたユーザーデータにアクセスできる、公平な競争の場を提供します。
以降のセクションでは、この 2 つの重要な側面について詳しく説明します。
ビジネス ロジック実行用のペアのプロセス アーキテクチャ
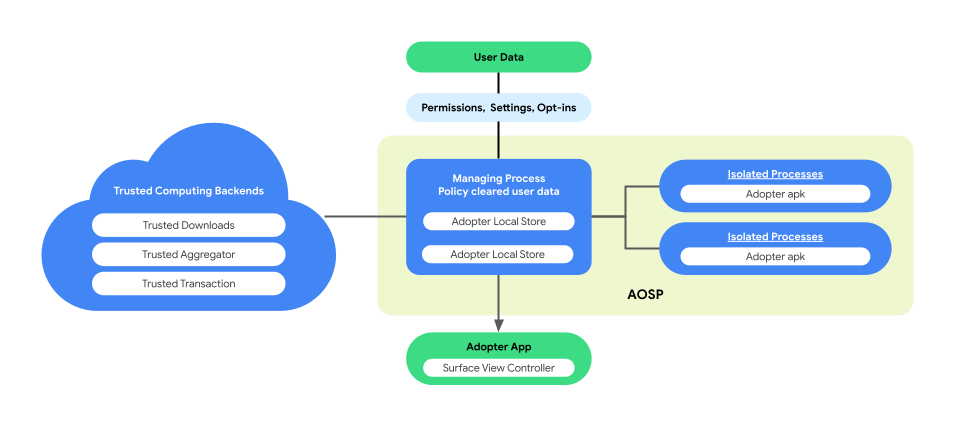
On-Device Personalization では、AOSP にペアのプロセス アーキテクチャが導入され、ビジネス ロジックの実行中にユーザーのプライバシーとデータ セキュリティが強化されます。このアーキテクチャは、次の要素で構成されています。
ManagingProcess。このプロセスは、IsolatedProcess を作成および管理し、許可リストに登録された API のみにアクセスを限定し、ネットワークやディスクの権限がないプロセスレベルの分離を維持します。ManagingProcess は、すべてのビジネスデータとすべてのエンドユーザー データを集めて、ビジネスコード用にポリシーの承認を受け、IsolatedProcesses にプッシュしてこれを実行します。さらに、IsolatedProcesses と system_server などの他のプロセスとの間のやり取りを仲介します。
IsolatedProcess。このプロセスは、分離(マニフェストの
isolatedprocess=true)として指定され、ManagingProcess からビジネスデータ、ポリシーで承認されたエンドユーザー データ、ビジネスコードを受け取ります。これにより、ビジネスコードがビジネスデータとポリシーの承認を得たエンドユーザー データを操作できるようになります。IsolatedProcess は、入力と出力の両方で ManagingProcess とのみ通信し、追加の権限は与えられません。
ペアのプロセス アーキテクチャにより、ビジネス ロジックやコードをオープンソース化しなくても、エンドユーザー データのプライバシー ポリシーの独立した検証を行えます。ManagingProcess が IsolatedProcesses の独立性を維持し、IsolatedProcess がビジネス ロジックを効率的に実行することで、このアーキテクチャでは、パーソナライズ中にユーザーのプライバシーを保護するための、より安全で効率的なソリューションが保証されます。
次の図は、このペアのプロセスのアーキテクチャを示しています。
データ運用のためのポリシーとポリシー エンジン
On-Device Personalization では、プラットフォームとビジネス ロジックの間にポリシー適用レイヤが導入されます。エンドユーザーとビジネスのコントロールを一元化された実用的なポリシー決定にマッピングする一連のツールを提供することが目的です。これらのポリシーは、フローやビジネス全体で包括的かつ確実に適用されます。
ペアのプロセス アーキテクチャでは、ポリシー エンジンは ManagingProcess 内に存在し、エンドユーザー データとビジネスデータの出入りを監視します。また、許可リストに登録されたオペレーションを IsolatedProcess に提供します。対象となる領域の例としては、エンドユーザー コントロールの尊重、児童の保護、同意のないデータ共有の防止、ビジネスのプライバシーなどがあります。
このポリシー適用アーキテクチャは、次の 3 種類の利用可能なワークフローから構成されています。
- 高信頼実行環境(TEE)通信を使用したローカルで開始されるオフライン ワークフロー:
- データ ダウンロード フロー: 信頼できるダウンロード
- データ アップロード フロー: 信頼できるトランザクション
- ローカルで開始されるオンライン ワークフロー:
- リアルタイム提供フロー
- 推論フロー
- ローカルで開始されるオフライン ワークフロー:
- 最適化フロー: フェデレーション ラーニング(FL)を介して実装されたオンデバイス モデル トレーニング
- レポートフロー: フェデレーション分析(FA)を介して実装されたクロスデバイス集計
次の図は、ポリシーとポリシー エンジンの観点からアーキテクチャを示しています。
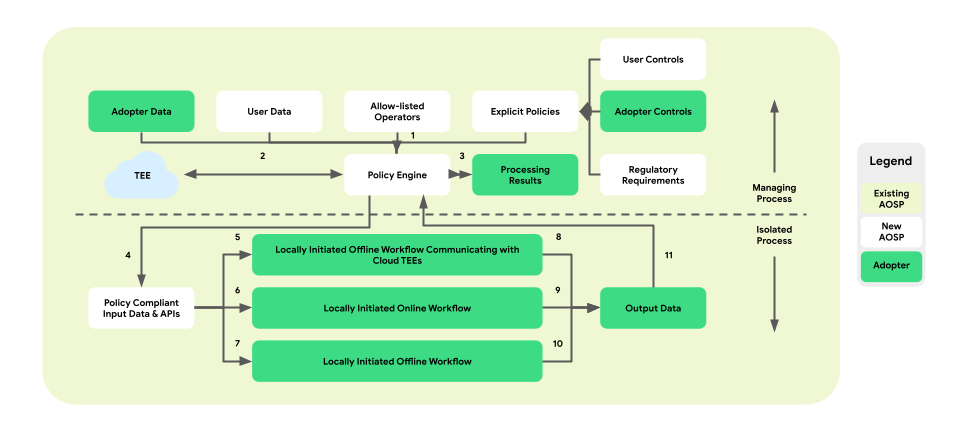
- ダウンロード: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- 提供: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- 最適化: 2(トレーニング プランを提供)-> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- レポート: 3(集計プランを提供)-> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
全体として、On-Device Personalization のペアのプロセス アーキテクチャにポリシー適用レイヤとポリシー エンジンを導入することで、必要なデータとオペレーションへの制御されたアクセスを提供しながら、ビジネス ロジックを実行するための分離されたプライバシー保護環境を確保します。
レイヤ化された API サーフェス
On-Device Personalization は、関心のある企業に階層化された API アーキテクチャを提供します。最上位レイヤは、特定のユースケース向けに構築されたアプリケーションで構成されています。潜在的な企業は、最上位レイヤ API と呼ばれるこれらのアプリケーションにデータを接続できます。最上位レイヤ API は、中間レイヤ API 上に構築されています。
今後、最上位レイヤ API をさらに追加していく予定です。最上位レイヤ API が特定のユースケースで利用できない場合、または既存の最上位レイヤ API の柔軟性が十分でない場合、企業はプログラミング プリミティブにより柔軟性を高めることができる中間レイヤ API を直接実装できます。
まとめ
On-Device Personalization は、高い実用性をもたらすことが期待される最新かつ最高水準のテクノロジーを使用して、エンドユーザーのプライバシーに関する懸念に対処する長期的なソリューションへの関心を喚起し、フィードバックを求める初期段階の研究提案です。
Google は、プライバシーの専門家、データ アナリスト、潜在的なエンドユーザーなどの関係者と連携して、ODP がニーズを満たし、懸念事項に対処できるようにしたいと考えています。