Am Vorschlag für Attribution Reporting wurden einige Änderungen vorgenommen, um Feedback aus der Community, von Änderungen an API-Mechanismen bis hin zu neuen Funktionen.
Änderungsprotokoll
- 7. Februar 2022: Abschnitt zur Weiterleitung von Headern zu Triggern hinzugefügt.
- 27. Januar 2022: Artikel erstmals veröffentlicht.
An wen richtet sich dieser Beitrag?
Dieser Beitrag richtet sich an dich:
- Wenn Sie die API bereits verstehen, z. B. wenn Sie die an den Diskussionen über das WICG-Repository teilnehmen und Änderungen, die im Januar 2022 am Vorschlag vorgenommen wurden.
- Sie verwenden die Attribution Reporting API in einer Demo oder einem Test in der Produktionsumgebung.
Wenn Sie diese API gerade erst verwenden und/oder noch nicht damit experimentiert haben, gehen Sie direkt zu den Einführung in die API .
Migration steht bevor
Nach der Implementierung dieser Änderungen in Chrome: Wenn Sie Berichte auf Ereignisebene der Attribution Reporting API in einer Demo oder einem Test in der Produktion (Ursprungstest) verwenden, müssen Sie den Code bearbeiten, damit die API weiterhin funktioniert. Sie können auch die neuen Funktionen verwenden.
In diesem Artikel werden auch Änderungen für aggregierbare Berichte aufgeführt. Falls diese Änderungen implementiert werden, sind jedoch keine Maßnahmen und keine Migration erforderlich, da es zum Zeitpunkt der Erstellung dieses Dokuments noch keine Browserimplementierung für aggregierte Berichte gab.
Namensänderungen
Zusammenfassende Berichte und aggregierbare Berichte
Unter „Zusammenfassungsberichte“ als Zusammenfassungsberichte.
Zusammenfassungsberichte sind das endgültige Ergebnis der Zusammenfassung mehrerer aggregierbarer Berichte. als Beitrags- oder Histogrammbeiträge bezeichnet.
Änderungen am API-Mechanismus
Header-basierte Quellenregistrierung (Berichte auf Ereignisebene)
Was ändert sich und warum?
Wenn ein Nutzer eine Anzeige sieht oder darauf klickt, erfasst der Browser – lokal auf dem Gerät des Nutzers – dieses Ereignis.
neben Parametern, die für Attributionsberichte spezifisch sind (z. B.
attributionsourceeventid, attributiondestination, attributionexpiry und andere Parameter). Die
werden die Werte dieser Parameter
von der AdTech festgelegt.
Die Art und Weise, wie diese Parameter festgelegt werden, ändert sich.
Im vorherigen Angebot mussten die Parameter clientseitig eingefügt werden: entweder in den Anchor-Tags. als HTML-Attribute oder als Argumente eines JS-basierten Aufrufs. Parameter mussten beim Klicken oder Aufrufen bekannt sein. .
Im neuen Angebot wird der Wert dieser Parameter stattdessen auf dem AdTech-Server definiert.
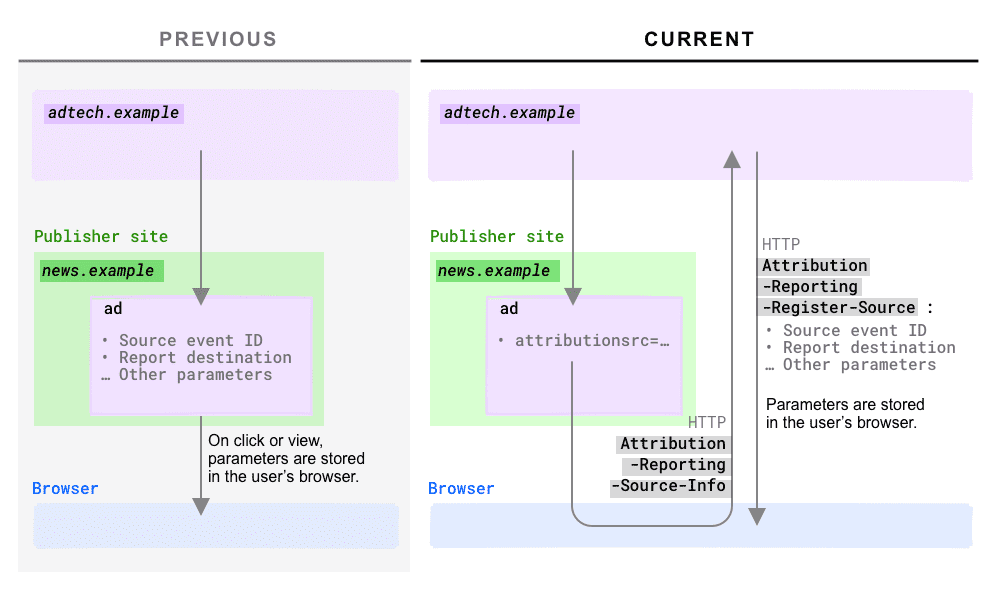
Dies hat eine Reihe von Vorteilen, insbesondere in Bezug auf die Sicherheit: Der Header-Mechanismus ermöglicht es die direkte Kontrolle darüber, ob eine Zuordnungsquelle in ihrem Umfang. So lassen sich Betrugsfälle teilweise entschärfen, da nach dieser Änderung kein echter Browser eine Quelle ohne die Zustimmung des Ursprungs der Berichterstellung zu registrieren.
Wie funktioniert die Quellenregistrierung?
- Für eine bestimmte Anzeige müsste die AdTech jetzt ein spezifisches clientseitiges Attribut definieren.
attributionsrcDer Wert dieses Attributs ist eine URL, an die der Browser eine anfragen: Diese Anfrage enthält den neuen HTTP-HeaderAttribution-Reporting-Source-Info, dessennavigationoderevent,gibt an, ob die Quelle ein Klick bzw. ein Aufruf war. - Nach Erhalt dieser Anforderung sollte der Klick-/Ansicht-Tracking-Server mit einer HTTP-Antwort
Header,
Attribution-Reporting-Register-Source, der die gewünschte Attribution enthält Parameter. Der Ursprung, der diesen Header zurückgibt, ist jetzt der Ursprung der Berichterstellung (früher definiert als
attributionreportto.HTTP-Antwortheader
Attribution-Reporting-Register-Source:{ "source_event_id": "267630968326743374", "destination": "https://toasters.example", "expiry": "604800000" }
Weitere Informationen findest du in der technischen Erläuterung.
Attributionsquellen registrieren
An der öffentlichen Diskussion teilnehmen
Trigger für kopfbasiertes Attributionsmodell (Berichte auf Ereignisebene)
Was ändert sich und warum?
Genau wie bei einer Klick- oder Aufrufregistrierung ändert das neue Angebot den Attributionsauslöser:
Adtech weist den Browser an, eine Conversion zu erfassen. Dabei wird ein Header-basierter Ansatz verfolgt.
Dieser Mechanismus ist auf die headerbasierte Quellregistrierung abgestimmt und bietet mehr
herkömmlicher als der zuvor verwendete Weiterleitungsmechanismus.
Außerdem wird im neuen Angebot das Attribut attributionsrc auf der Conversion-Seite benötigt.
Die Begründung ist eine Frage der Berechtigungen: Im vorherigen Vorschlag wurde die Auslöser-seitige Website – in der Regel
Website eines Werbetreibenden – allgemeine Kontrolle über die Funktion über eine Permissions-Policy-Kopfzeile, aber
hatte keine detaillierte Kontrolle auf Elementebene darüber, ob ein Element eine Anfrage an eine Partei senden kann
die letztendlich eine Attribution auslösen würden. attributionsrc ändert dies: diese erforderliche Markierung
können Werbetreibende überwachen und somit steuern, welche Elemente
Namensnennung.
Beachten Sie, dass auf der Quellseite – in der Regel einer Publisher-Website – eine seitenweite Kontrolle über
Permissions-Policy sowie ein Steuerelement für das gesamte Element über attributionsrc sind vorhanden.
Wie funktioniert der Attributionstrigger?
Nach Erhalt einer Pixelanfrage und der Entscheidung,
dass sie als Conversion kategorisiert werden soll,
sollte mit einem neuen HTTP
-Fehler antworten
Header Attribution-Reporting-Register-Event-Trigger.
Der Wert dieses Headers gibt an, wie das Triggerereignis als JSON-Objekt behandelt werden soll. Das Gleiche Informationen, die im vorherigen Angebot als Abfrageparameter definiert wurden.
HTTP-Antwortheader Attribution-Reporting-Register-Event-Trigger:
[{
trigger_data: (unsigned 3-bit integer),
trigger_priority: (signed 64-bit integer),
deduplication_key: (signed 64-bit integer)
}]
Weiterleitung (optional)
Optional kann der Adtech-Server die Antwort, die Attribution-Reporting-Register-Event-Trigger enthält, als Weiterleitungsantwort senden.
So können Drittanbieter das Conversion-Ereignis beobachten und den Browser anweisen, es zuzuordnen.
Die Weiterleitung ist optional. wenn sowohl AdTech als auch Drittanbieter Pixel auf der Seite haben.
Weitere Informationen finden Sie unter Berichte zu Drittanbietern.
Weitere Informationen findest du in der technischen Erläuterung.
An der öffentlichen Diskussion teilnehmen
Kein Worklet (aggregierbare Berichte)
Was ändert sich und warum?
Beim vorherigen Vorschlag für aggregierbare Berichte war JavaScript-Zugriff erforderlich, um eine Worklet zu erstellen, einem JavaScript-basierten Mechanismus, mit dem diese Berichte generiert werden.
Im neuen Angebot ist kein Worklet erforderlich. Stattdessen würde ein AdTech-Team die Definition deklarativ – über HTTP Header – die Regeln, die der Browser zum Erstellen aggregierter Berichte verwenden soll.
Das neue Angebot bietet mehrere Vorteile:
- Browserimplementierung:Das neue Design ist im Gegensatz zum Worklet-Design wesentlich einfacher ist, weil dafür keine neue Ausführungsumgebung in Browsern erforderlich ist.
- Entwicklererfahrung:Das neue Design beruht auf Überschriften, die häufig verwendet und im Gegensatz zu Worklets allgemein bekannt sind. Sie ist außerdem eng an die API-Oberfläche für Quellregistrierung. Dadurch ist die API leichter zu erlernen und zu verwenden.
- Verwendung: Das neue Design ermöglicht es mehr bestehenden Messsystemen, aggregierte Berichte. Viele Analysetools arbeiten nur mit HTTP, sie basieren auf Bildanfragen – Pixel die keinen JavaScript-Zugriff erfordern. Da der Worklet-Ansatz jedoch JavaScript-Zugriff haben, war es möglicherweise schwierig, von einigen bestehenden Messsystemen zu migrieren.
- Robustheit:Das neue Design verringert Datenverluste, da es einfacher zu integrieren ist.
mit
keepalive-Semantik, z. B. wenn ein Klick oder eine Ansicht registriert wird, wenn ein Nutzer die Website verlässt auf einer Seite.
Wie funktioniert der Mechanismus ohne Worklets?
Dieser deklarative Mechanismus basiert auf HTTP-Headern – genau wie bei der Quellenregistrierung auf Ereignisebene. und den Header für den Attributionstrigger. Weitere Informationen hierzu finden Sie in den nächsten Abschnitten.
An der öffentlichen Diskussion teilnehmen
Headerbasierte Quellenregistrierung (aggregierbare Berichte)
Es wird ein neuer Mechanismus vorgeschlagen, um eine Quelle für einen aggregierten Bericht zu registrieren. ist dieser Mechanismus der entspricht der Quellenregistrierung auf Ereignisebene.
Nur der Headername unterscheidet sich: Attribution-Reporting-Register-Aggregatable-Source.
Weitere Informationen findest du in der technischen Erläuterung.
Registrierung der Attributionsquelle
Trigger für Header-basierter Attribution (aggregierbare Berichte)
Es wird ein neuer Mechanismus vorgeschlagen, um eine Quelle für einen aggregierten Bericht zu registrieren. ist dieser Mechanismus der wie der Attributionstrigger auf Ereignisebene.
Nur der Headername unterscheidet sich: Attribution-Reporting-Register-Aggregatable-Trigger-Data.
Weitere Informationen findest du in der technischen Erläuterung.
Registrierung des Attributionsauslösers
Neue Funktionen
Drittanbieterberichte (Berichte auf Ereignisebene und aggregierte Berichte)
Was ändert sich und warum?
Zwei Aspekte des neuen Angebots tragen dazu bei, Berichte von Drittanbietern besser zu unterstützen:
- Optional können AdTechs Netzwerkanfragen an andere AdTech-Server weiterleiten, sodass diese anderen damit AdTechs ihre eigene Quelle ausführen und die Registrierung auslösen können. Dies ist eine gängige Methode, werden heute konfiguriert. Dies vereinfacht die Einführung der API unter anderem in bestehenden Drittanbieter-Berichtssysteme.
- Für die Berichtsquellen – in der Regel AdTechs – gelten die meisten Datenschutzbeschränkungen. Dies unterstützt die Verwendung wenn mehrere AdTech-Unternehmen mit denselben Publishern oder Werbetreibenden zusammenarbeiten.
Wie funktionieren Berichte von Drittanbietern?
Im neuen Angebot basieren die antwortbasierte Quellenregistrierung und der Trigger auf HTTP-Header. AdTech kann HTTP-Weiterleitungen für diese Anfragen nutzen.
Wenn eine Klick-/Aufrufanfrage auf einer Publisher-Website (Quellenregistrierung) anschließend auf
kann jede dieser Parteien diesen Aufruf oder Klick registrieren (Quellereignis).
Ebenso kann ein AdTech-Anbieter
eine spezifische Zuordnungsanfrage weiterleiten, die von
So können mehrere andere Parteien eine Conversion registrieren (Attributionstrigger).
Jede Partei kann auf ihre separaten Berichte zugreifen und sie mit separaten Daten konfigurieren.
Mehrere Trigger ohne Weiterleitungen registrieren
Sie können auch mehrere Attributionstrigger ohne Weiterleitungen registrieren, indem Sie mehrere Pixelelemente auf der Conversion-Seite hinzufügen (eines pro Trigger).
An der öffentlichen Diskussion teilnehmen
View-through-Messung (Berichte auf Ereignisebene und aggregierbare Berichte)
Was ändert sich und warum?
Im neuen Angebot werden View-through-Messung und Klick-Messung vereinheitlicht:
registerattributionsrcist das ansichtsspezifische Attribut, das den Browser angewiesen hat, Aufrufe mit Klicks erzielen, ist nicht mehr Bestandteil des Vorschlags.- Die Datenschutzmechanismen sind jetzt für Click-and-View vereinheitlicht. Weitere Informationen hierzu finden Sie im Abschnitt Rauschen und Transparenz.
Diese Änderung wird im Einklang mit dem neuen headerbasierten Registrierungsmechanismus vorgeschlagen. Außerdem vereinfacht es die Entwicklererfahrung, wenn sowohl Klick- als auch View-through-Conversions möglich sind. zu messen.
Wie funktioniert die View-through-Analyse?
Die View-through-Messung und die Klick-Messung basieren beide auf einer headerbasierten Registrierung.
Weitere Informationen findest du in der technischen Erläuterung.
Berichte auf Ereignisebene (für Klicks und Aufrufe)
An der öffentlichen Diskussion teilnehmen
Fehlerbehebung / Leistungsanalyse (Berichte auf Ereignisebene und aggregierbare Berichte)
Was ändert sich und warum?
Der Vorschlag wurde um einen Debugging-Mechanismus ergänzt, mit dem Entwickler Fehler leichter erkennen und die Leistung von Attribution Reporting mit der von anderen Cookie-basierten Analysetools vergleichen.
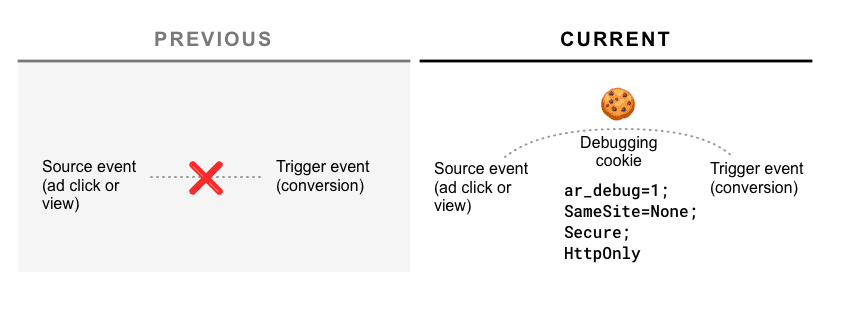
Wie funktioniert die Fehlerbehebung?
Sowohl die Quell- als auch die Triggerregistrierung akzeptieren den neuen Parameter debug_key, einen unsignierten 64-Bit-Parameter.
Integer (d. h. eine große Zahl) ein.
Wenn ein Bericht mit Quelle erstellt wird und Schlüssel zur Fehlerbehebung auslöst, und wenn ein Samesite=None ar_debug=1-Cookie
in der Cookie-JAR-Datei des Berichtsursprungs an der Quelle vorhanden ist und den Zeitpunkt der Registrierung auslöst, wird eine Fehlerbehebung
Bericht (JSON) wird an einen .well-known/attribution-reporting/debug-Endpunkt gesendet:
{
"source_debug_key": 1234567890987,
"trigger_debug_key": 4567654345028
}
Berichte auf Ereignisebene und aggregierte Berichte enthalten ebenfalls diese beiden neuen Parameter, die mit dem richtigen Debug-Bericht verknüpft sind.
Weitere Informationen findest du in der technischen Erläuterung.
Optional: erweiterte Debugging-Berichte
An der öffentlichen Diskussion teilnehmen
Filterfunktionen (Berichte auf Ereignisebene und aggregierte Berichte)
Was ändert sich und warum?
Da sie wichtige Anwendungsfälle im Werbesystem von heute unterstützen, gibt es eine Reihe von Anwendungsfällen, werden jetzt in Berichten auf Ereignisebene und in aggregierten Berichten unterstützt:
- Conversion-Filterung:Filtern Sie Conversions basierend auf quellseitigen Informationen. Für Sie können beispielsweise unterschiedliche Triggerdaten (Conversion-Daten) für Anzeigenklicks und -aufrufe auswählen.
- Nicht übereinstimmende Attribution:Conversions, die falsch zugeordnet wurden, werden herausgefiltert. das ist ein Conversion-Filterung verwenden. So können Sie z. B. Conversions herausfiltern, der falsche Anzeigenklick bzw. der falsche Anzeigenklick aufgrund des Zielbereichs von „etld+1“ in der API.
Wie funktionieren Filterfunktionen? (für Berichte auf Ereignisebene)
Mit dem optionalen Feld source_data im quellseitigen JSON-Objekt können Elemente definiert werden,
und der später bei der Conversion verwendet wird, um eine Filterlogik anzuwenden.
{
source_event_id: "267630968326743374",
destination: "https://toasters.example",
expiry: "604800000"
source_data: {
conversion_subdomain: ["electronics.megastore"
"electronics2.megastore"],
product: "198764",
// Note that "source_type" will be automatically generated as one of {"navigation", "event"}
}
}
Für die Triggerregistrierung wird jetzt der optionale Header „Attribution-Reporting-Filters“ akzeptiert.
HTTP-Antwortheader Attribution-Reporting-Filters:
{
"conversion_subdomain": "electronics.megastore",
"directory": "/store/electronics"
}
Alternativ kann der Attribution-Reporting-Register-Event-Trigger-Header mit einem
filters-Feld für die selektive Filterung, um trigger_data basierend auf source_data festzulegen.
Wenn Schlüssel in den JSON-Filtern mit Schlüsseln in source_data übereinstimmen, ist der Trigger
wird vollständig ignoriert, wenn die Kreuzung leer ist.
Weitere Informationen findest du in der technischen Erläuterung.
An der öffentlichen Diskussion teilnehmen
Änderungen beim Datenschutz
Rauschen und Transparenz (Berichte auf Ereignisebene und aggregierte Berichte)
Was ändert sich und warum?
Im neuen Vorschlag wurde einer der Datenschutzmechanismen für Berichte verbessert: Berichte sind
einer zufälligen Antwort unterliegen.
Das bedeutet, dass einige echte Conversions korrekt erfasst werden. und ein bestimmter Prozentsatz
werden einige echte Conversions unterdrückt oder falsche Conversions hinzugefügt.
Diese neue Technik hat einige Vorteile:
- Dadurch wird der Datenschutzmechanismus für Klicks und Aufrufe vereinheitlicht.
- Das ist einfacher als ein Verfahren, bei dem die Triggerdaten (Conversion-Daten) und das Rauschen zwischen dem Trigger und dem Link der Quelle getrennt werden.
- Es wird ein Datenschutz-Framework geschaffen, durch das mit den richtigen Einstellungen für die Rauschen sichergestellt werden kann, dass sich keine Partei darauf verlassen kann, dass die API sicher ist, dass ein einzelner Nutzer eine Conversion für eine bestimmte Anzeige abgeschlossen hat oder nicht.
Dieser neue Mechanismus ersetzt den vorherigen Mechanismus, bei dem in 5% der Fälle Trigger-Daten (Conversion-Daten) wurde durch einen zufälligen Wert ersetzt.
Außerdem wurde der Wert für die Wahrscheinlichkeit der zufälligen Antwort in den Berichtstext eingefügt.
(randomized_trigger_rate Feld). Dieses Feld gibt die Wahrscheinlichkeit (0 bis 1) an, dass eine Quelle
einer zufälligen Antwort vor.
Dies hat zwei Hauptvorteile:
- Dadurch wird das zugrunde liegende Browserverhalten für die Parteien, die die Berichte erhalten, transparent. (in der Regel AdTechs).
- Dies ist hilfreich für eine Zukunft, in der die API in verschiedenen Browser: Unterschiedliche Browser verwenden möglicherweise unterschiedliche Rauschpegel, und die für den Bericht zuständigen Beteiligten müssen diese Informationen sehen können.
Wie funktionieren Geräusche?
Wenn im neuen Angebot eine Quelle registriert wird, d.h. ein Anzeigenklick oder eine Anzeige erfasst wird, nach dem Zufallsprinzip entscheidet, ob Conversions korrekt zugeordnet werden Anzeigenklick bzw. -aufruf oder die Erzeugung einer gefälschten Ausgabe.
Die fiktive Ausgabe kann so aussehen:
- Keinerlei Bericht – unabhängig davon, ob der Nutzer eine Conversion ausführt
- Eine oder mehrere gefälschte Meldungen – unabhängig davon, ob der Nutzer eine Conversion ausführt
In gefälschten Berichten sind die Trigger-Daten (Conversion-Daten) zufällig: ein 3-Bit-Zufallswert für Klicks (alle eine Zahl zwischen 0 und 7) und einen 1-Bit-Zufallswert für Ansichten (0 oder 1) enthält.
Genau wie echte Meldungen werden auch gefälschte Meldungen nicht sofort nach einer Conversion gesendet. Sie werden an die folgende Adresse gesendet: am Ende eines zufälligen Berichtsfensters an.
Es gibt drei Berichtszeiträume für Klicks (2 Tage, 7 Tage oder 30 Tage nach dem Klick). Jede Fälschung wird einem der Berichtsfenster nach dem Zufallsprinzip zugewiesen.
Wie im vorherigen Angebot bereits angegeben, ist die Reihenfolge der Berichte innerhalb eines Fensters zufällig.
Weitere Informationen findest du in der technischen Erläuterung.
Beispiele für unechte Fake-Conversions
An der öffentlichen Diskussion teilnehmen
Einschränkungen bei der Berichterstellung (Berichte auf Ereignisebene und aggregierte Berichte)
Grenzwerte für die Berichtsquelle
Was ändert sich und warum?
Im neuen Angebot wird explizit eingeschränkt, wie viele Parteien Ereignisse zwischen zwei Websites messen können.
- Die maximale Anzahl eindeutiger Berichtsquellen (in der Regel AdTech-Unternehmen), die registriert werden können die Anzahl der Quellen pro {publisher, advertiser} soll auf 100 pro 30 Tage begrenzt werden. Dieses wird der Zähler für jeden Klick oder jeden Anzeigenaufruf erhöht (Quellereignis). Dies gilt auch für Klicks, die nicht zugeschrieben werden.
- Die maximale Anzahl eindeutiger Berichtsquellen (in der Regel AdTech-Unternehmen), die pro Für {publisher, advertiser} wird eine Begrenzung auf 10 pro 30 Tage vorgeschlagen. Dieser Zähler wird erhöht sich für jede zugeordnete Conversion.
Diese Grenzwerte sind so hoch angesetzt, dass sie die Fähigkeit von Schauspielern nicht einschränken, Conversions, aber niedrig genug, um einige Formen des API-Missbrauchs einzudämmen.
Wartezeiten und Ratenbegrenzungen für Berichte
Was ändert sich und warum?
Die Wartezeit bei Berichten ist ein Datenschutzmechanismus, der die Menge der insgesamt gesendeten Informationen drosselt in einem bestimmten Zeitraum für einen Nutzer über diese API.
Im neuen Angebot: 100 Berichte pro {Quellwebsite, Ziel, Ursprung der Berichterstellung} (in der Regel {publisher, advertiser, adtech}) kann über 30 Tage geplant werden.
Wird diese Grenze überschritten, plant der Browser keine Berichte mehr, die dieser angegebenen {source site, Ziel, Berichtsursprung} (normalerweise {publisher, advertiser, adtech}) – bis zu den rollierenden 30 Tagen Die Anzahl der Berichte für {source site, destination, reporting origin} liegt unter 100.
Weitere Informationen findest du in der technischen Erläuterung.
Berichterstellung für Wartezeiten / Ratenbegrenzungen
Ziel-Capping (nur Berichte auf Ereignisebene)
Was ändert sich und warum?
Ziel-Capping wird so geändert, dass der Ursprung der Berichterstellung (in der Regel eine Anzeigentechnologie) mit dem Gültigkeitsbereich 100 eindeutig eingeschlossen wird. ausstehende Ziele (normalerweise Websites von Werbetreibenden oder Websites, für die Conversions erwartet werden) Place) pro {publisher, adtech} zulässig sind.
Dies ist eine Datenschutzmaßnahme, mit der die Rekonstruktion des Browserverlaufs eingeschränkt wird.
Weitere Informationen findest du in der technischen Erläuterung.
Begrenzen der Anzahl eindeutiger Ziele, die von ausstehenden Quellen abgedeckt werden
Alle Ressourcen
- Weitere Informationen finden Sie unter Attributionsberichte.
- Wichtige Informationen zur API
Das Kopfzeilenbild stammt von Diana Polekhina auf Unsplash.